
大语言模型(LLMs)在近年来取得了快速发展。本文总结了2024年6月上半月发布的一些最重要的LLM论文,可以让你及时了解最新进展。
LLM进展与基准测试
1、WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
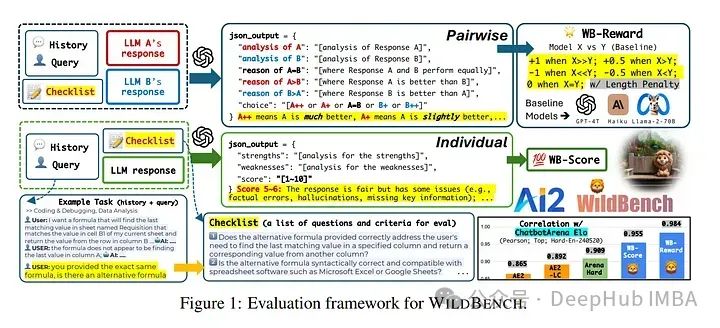
WildBench是一个自动评估框架,使用具有挑战性的、现实世界中的用户查询来基准测试大语言模型(LLMs)。WildBench包含1,024个任务和精心挑选超过一百万个人机对话日志。
为了使用WildBench进行自动评估,论文开发了两个指标,WB-Reward和WB-Score,这些指标可以使用高级LLMs如GPT-4-turbo计算。
https://arxiv.org/abs/2406.04770
2、NATURAL PLAN: Benchmarking LLMs on Natural Language Planning

NATURAL PLAN是一个在自然语言中进行现实规划的基准测试,包含三个关键任务:旅行规划、会议规划和日历安排。
这个评估重点是在完全了解任务信息的情况下对LLMs的规划能力进行评估,通过提供来自Google Flights、Google Maps和Google Calendar等工具的输出作为模型的上下文。这消除了在评估LLMs在规划方面的需要使用工具环境的需求。
随着问题复杂度的增加,模型性能急剧下降:所有模型在涉及10个城市的情况下的表现均低于5%,这凸显了在自然语言规划中存在的显著差距。
论文还对NATURAL PLAN进行了广泛的消融研究,进一步揭示了自我纠正、少量示例泛化和长上下文规划等方法在改善LLM规划方面的(无)效果。
https://arxiv.org/abs/2406.04520
3、Tx-LLM: A Large Language Model for Therapeutics

开发治疗方法是一个漫长且昂贵的过程,需要满足许多不同的标准,而能够加速此过程的AI模型非常宝贵。
当前大多数AI方法仅解决特定领域内明确定义的任务范围。而Tx-LLM(PaLM-2微调)编码了关于多种治疗方式的知识。
Tx-LLM使用709个数据集进行训练,这些数据集针对药物发现流程的各个阶段的66个任务。使用一组权重,Tx-LLM可以同时处理各种化学或生物实体(小分子、蛋白质、核酸、细胞系、疾病)与自由文本的交错,预测广泛的相关属性,与最新的(SOTA)性能竞争,其中43个任务达到了SOTA性能,22个超过了SOTA。
https://arxiv.org/abs/2406.06316
4、Towards a Personal Health Large Language Model
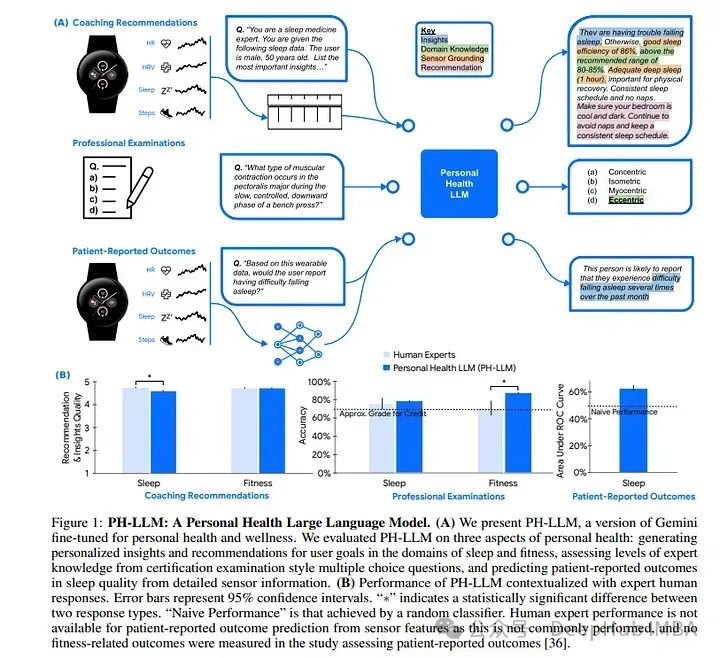
在健康领域,大多数大语言模型(LLM)研究侧重于临床任务。很少将移动和可穿戴设备集成到此类任务中,这些设备提供了丰富的纵向个人健康监测数据。
论文介绍了个人健康大语言模型(PH-LLM),它是从Gemini微调而来,用于理解和推理数值时间序列个人健康数据。创建并整理了三个数据集,用于测试:
- 从睡眠模式、身体活动和生理反应中生成个性化见解和建议。
- 领域专家知识
- 预测睡眠结果。
尽管对于安全关键的个人健康领域,还需要进一步的开发和评估,但这些结果展示了Gemini模型的广泛知识和能力,以及在个人健康应用中对生理数据进行情境化的好处,正如PH-LLM所做的那样。
https://arxiv.org/abs/2406.06474
5、Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
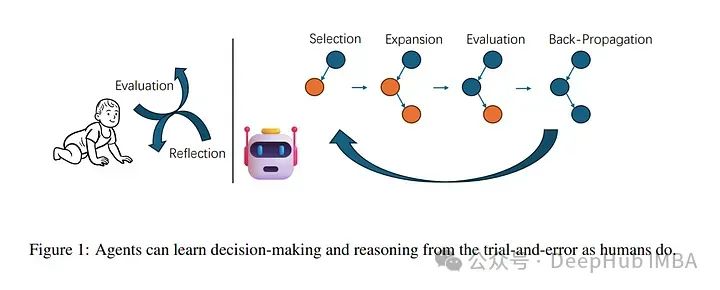
MCTSr算法是将大语言模型(LLMs)与蒙特卡洛树搜索(MCTS)创新整合的方法,旨在提高复杂数学推理任务的性能。
面对LLMs在策略和数学推理中的准确性和可靠性挑战,MCTSr利用系统探索和启发式自我完善机制来改进LLMs内的决策框架。
该算法通过迭代的选择、自我完善、自我评估和反向传播过程构建蒙特卡洛搜索树,使用改进的上限置信区间(UCB)公式来优化探索和利用的平衡。
广泛的实验表明,MCTSr在解决奥林匹克级数学问题上的有效性,显著提高了多个数据集上的成功率,包括GSM8K、GSM Hard、MATH和奥林匹克级基准,如 Math Odyssey、AIME和OlympiadBench。
https://arxiv.org/abs/2406.07394
6、MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
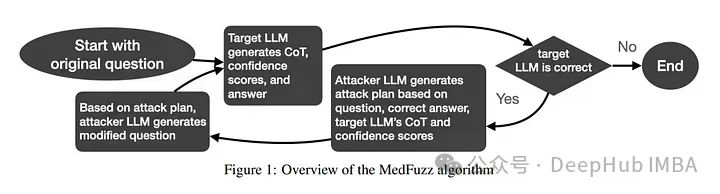
大语言模型(LLM)在医学问答基准测试中取得了令人印象深刻的表现。但是高基准测试准确率并不意味着能够推广到真实世界的临床环境中。
医学问答基准测试依赖于与量化LLM性能一致的假设,但这些假设在临床的开放环境中可能不成立。论文寻求量化LLM在医学问答基准测试性能在基准假设被违反时的推广能力。提出了一种我们称为MedFuzz(用于医学模糊测试)的对抗性方法。
论文介绍了一种排列测试技术,可以确保成功的攻击具有统计意义。并展示如何使用在“MedFuzzed”基准上的表现以及单个成功攻击来使用这些方法。这些方法在提供洞察LLM在更现实设置中的稳健操作能力方面显示出希望。
https://arxiv.org/abs/2406.06573
7、mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus

多模态大语言模型(mLLMs)在大量的文本-图像数据上进行训练。尽管大多数mLLMs是在仅有标题的数据上训练的,Alayrac等人展示了在它们的训练中额外包含文本和图像的交错序列可以促使上下文学习能力的出现。
但是他们使用的数据集M3W是不公开的,并且仅限英语。当前的多语种和多模态数据集要么仅由标题组成,要么规模中等,或完全是私有数据。这限制了对世界上其他7000种语言的mLLM研究。因此论文推出了mOSCAR,这是第一个从网络爬取的大规模多语种和多模态文档语料库。
它涵盖了163种语言、3.15亿文档、2140亿标记和12亿图像。作者还仔细进行了一系列的过滤和评估步骤,以确保mOSCAR足够安全、多样化且质量良好。
最后作者还训练了两种类型的多语种模型以证明mOSCAR的好处:(1)在mOSCAR的一个子集和标题数据上训练的模型以及(2)仅在标题数据上训练的模型。在mOSCAR上额外训练的模型在各种多语种图文任务和基准测试中表现出强大的少数示例学习性能。
https://arxiv.org/abs/2406.08707
8、Are We Done with MMLU?
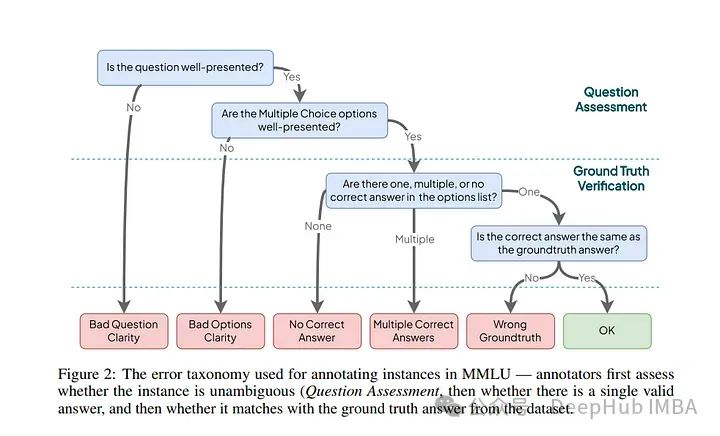
论文识别并分析了流行的大规模多任务语言理解(MMLU)基准中的错误。尽管MMLU广泛使用,但分析显示许多真实错误掩盖了LLMs的真正能力。
例如,发现在分析的病毒学子集中57%的问题存在错误。为了解决这个问题引入了一个全面的框架来使用新的错误分类法识别数据集错误。然后创建了MMLU-Redux,这是一个包含30个MMLU科目中3000个手动重新标注问题的子集。
使用MMLU-Redux,展示了与最初报告的模型性能指标之间的显著差异。结果强烈支持修订MMLU错误问题,以增强其未来作为基准的实用性和可靠性。
https://arxiv.org/abs/2406.04127
9、CS-Bench: A Comprehensive Benchmark for Large Language Models Towards Computer Science Mastery
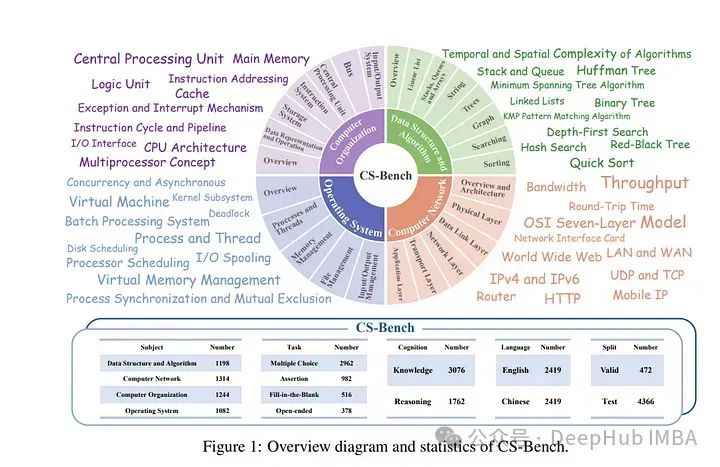
计算机科学(CS)是人类智能的复杂体现,推动了人工智能和现代社会的发展。当前的大语言模型(LLMs)社区过分关注分析特定基础技能的基准(例如数学和代码生成),忽略了对计算机科学领域的全面评估。
论文引入了CS-Bench,这是第一个双语(中英文)基准,专门用于评估LLMs在计算机科学中的表现。CS-Bench包含约5K精心策划的测试样本,涵盖计算机科学的4个关键领域中的26个子领域,包括各种任务形式和知识与推理的分区。
https://arxiv.org/abs/2406.08587
10、Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
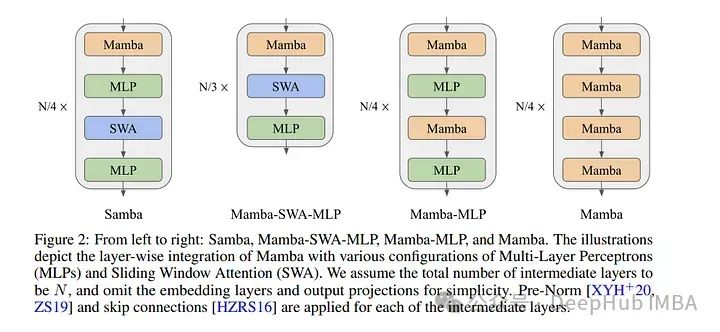
高效模拟具有无限上下文长度的序列一直是一个长期存在的问题。过去的工作要么存在二次计算复杂性问题,要么在长度泛化能力上有限。
Samba是一种简单的混合架构,通过分层结合Mamba(一种选择性状态空间模型SSM)和滑动窗口注意力(SWA),在保持精确记忆回忆能力的同时,选择性地压缩给定序列到递归隐藏状态。
论文将Samba扩展到38亿参数,使用32亿训练标记,并展示了Samba在一系列基准测试上显著优于基于纯注意力或SSM的最新模型。
在4K长度序列上训练时,Samba可以有效地外推到256K上下文长度,并在高达1M上下文长度的标记预测上表现出改善。
作为一个线性时间序列模型,Samba在处理128K长度用户提示时的吞吐量比采用分组查询注意力的transformer高出3.73倍,并在生成64K标记的无限流式传输中加速3.64倍。
https://arxiv.org/abs/2406.07522
11、 Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
从规模化先进AI系统中获得可预测行为是一个极具吸引力的特性。尽管关于预训练性能随规模变化的文献已广为人知,但关于特定下游能力随规模变化的文献却显得模糊不清。
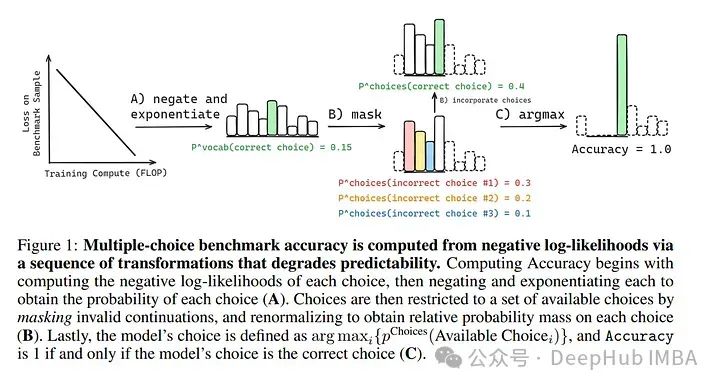
论文退一步问:为什么随规模变化预测特定下游能力仍然难以实现?虽然肯定有许多因素负责,但识别出了一个新因素,使得在广泛使用的多项选择问答基准上建模规模行为变得具有挑战性。
揭示了导致这种退化的机制:下游指标要求将正确选择与少数特定错误选择进行比较,这意味着准确预测下游能力需要预测随规模增加正确选择上的概率质量如何集中,以及错误选择上的概率质量如何波动。
通过实证研究探讨了在增加计算时正确选择上的概率质量与错误选择上的概率质量如何共变,暗示错误选择的规模化定律可能是可实现的。
https://arxiv.org/abs/2406.04391
12、Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models
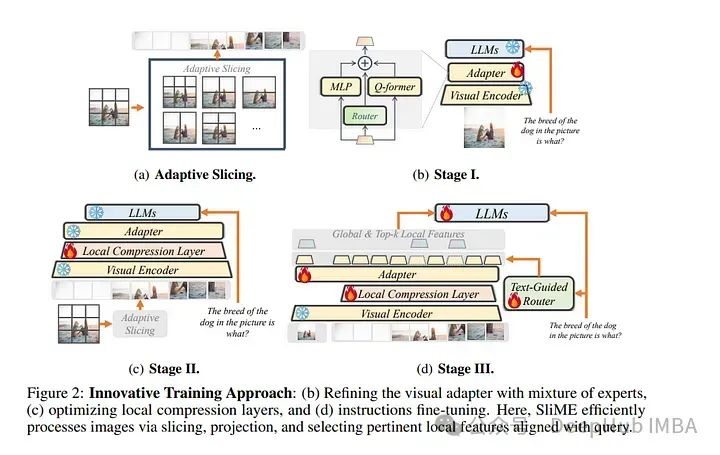
高分辨率是大规模多模态模型(LMMs)的基础,这些模型已被证明对视觉感知和推理至关重要。
现有工作通常采用直接的分辨率升级方法,其中图像由全局和局部分支组成,后者是被切分的图像块但重新调整为与前者相同的分辨率。这意味着更高的分辨率需要更多的局部补丁,导致巨大的计算费用,同时局部图像标记的优势可能会减弱全局上下文。
论文深入探讨这些问题,并提出一个新的框架以及一个精细的优化策略。具体来说,我们通过混合适配器从全局视图中提取上下文信息,基于观察到不同适配器在不同任务中表现出色。
https://arxiv.org/abs/2406.08487
LLM训练、评估与推理
1、GenAI Arena: An Open Evaluation Platform for Generative Models
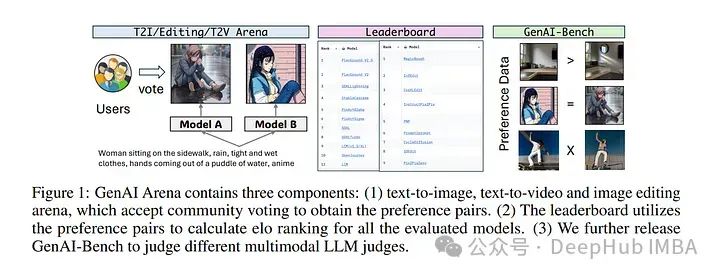
本文提出了一个开放平台GenAI-Arena,用于评估不同的图像和视频生成模型,用户可以积极参与评估这些模型。通过利用集体用户反馈和投票。
它涵盖了三个领域:文本到图像生成、文本到视频生成和图像编辑。总共涵盖了27个开源生成模型。GenAI-Arena已经运行了四个月,累计获得了6000多票。
为了进一步促进基于模型的评估指标研究,还发布了三个任务数据准备脚本GenAI-Bench。结果显示现有的多模态模型在评估生成的视觉内容方面仍然落后,即使是表现最好的模型GPT-4o在质量子分数上的皮尔森相关性也只有0.22,并且在其他方面表现得像随机猜测一样。
https://arxiv.org/abs/2406.04485
2、CRAG — Comprehensive RAG Benchmark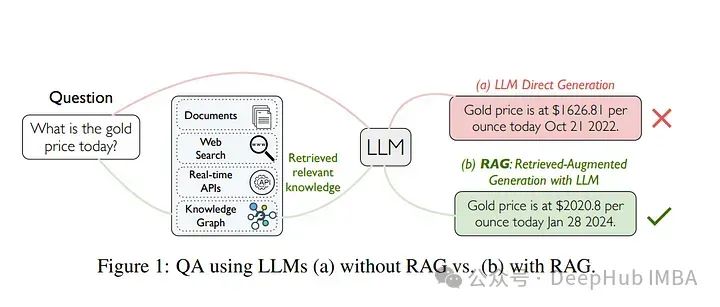
检索增强生成(RAG)作为解决大型语言模型(LLM)缺乏知识问题的有希望的解决方案而兴起。现有的RAG数据集并未充分代表现实世界问答(QA)任务的多样性和动态性。为了弥补这一差距,论文引入了全面的RAG基准(CRAG),这是一个由4,409个问答对组成的事实性问答基准,模拟Web和知识图谱(KG)搜索的模拟API。
CRAG旨在涵盖五个领域和八个问题类别的多样化问题阵列,反映了从热门到长尾的实体流行度和从年度到秒级的时间动态。
https://arxiv.org/abs/2406.04744
3、McEval: Massively Multilingual Code Evaluation
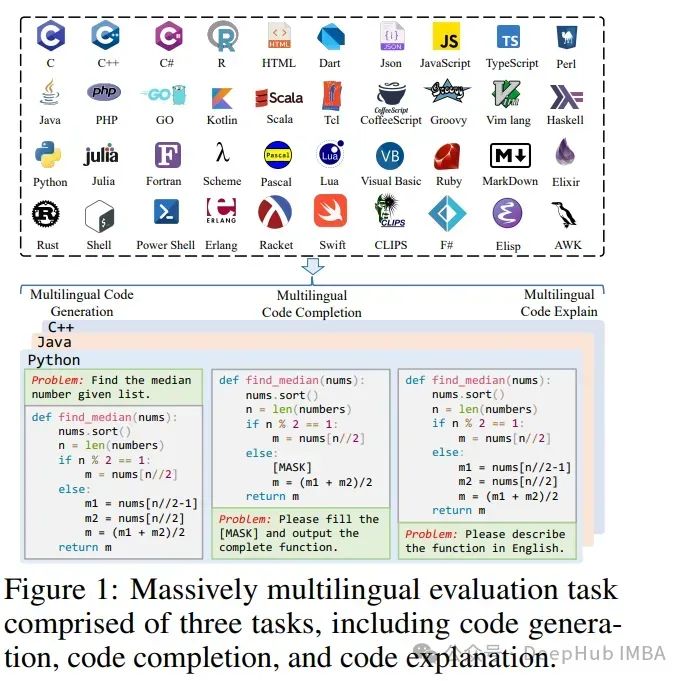
代码大语言模型(LLMs)在代码理解、完成和生成任务中表现出了显著的进步。目前大多数现有基准主要关注Python,仍然限制在有限的语言数量上,其中其他语言的样本是从Python样本翻译而来,这降低了数据多样性。
为了进一步促进代码LLMs的研究,论文提出了一个涵盖40种编程语言的大规模多语言代码基准(McEval),包含16K测试样本,极大地推动了代码LLMs在多语言场景中的极限。
该基准包含具有挑战性的代码完成、理解和生成评估任务,并配有精心策划的大规模多语言指令语料库McEval-Instruct。此外还介绍了一种有效的多语言编程语言生成器mCoder,该生成器在McEval-Instruct上进行了训练。
https://arxiv.org/abs/2406.07436
4、Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
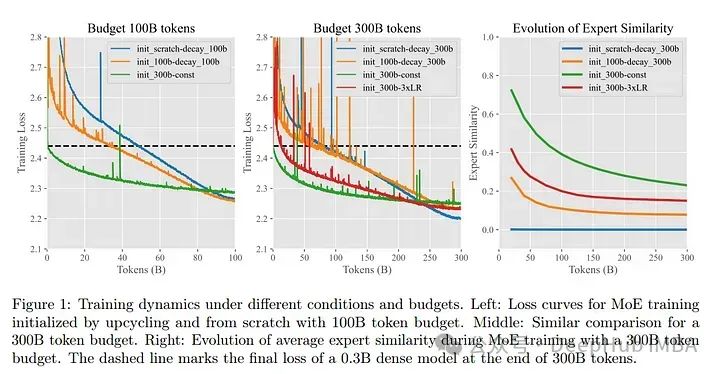
在这份技术报告中介绍了在开发Skywork-MoE这一高性能混合专家(MoE)大语言模型(LLM)时实施的训练方法,该模型拥有1460亿参数和16个专家。
模型是从现有的Skywork-13B模型的检查点初始化的。并且使用了两种创新技术:门控对数归一化,提高了门控出口多样化,以及自适应辅助损失系数,允许对辅助损失系数进行层特定的调整。我们的实验结果验证了这些方法的有效性。
https://arxiv.org/pdf/2406.06563
5、Large Language Model Confidence Estimation via Black-Box Access
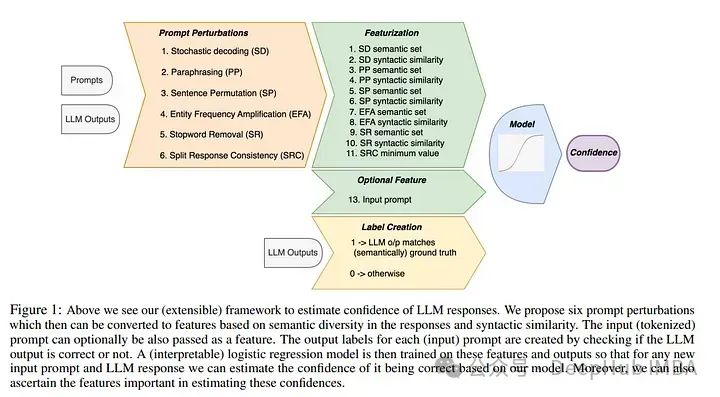
在模型响应的不确定性或置信度的估计中,可以显著地评估不仅仅是对响应的信任,而且对整个模型的信任。论文探讨了通过仅黑箱或查询访问它们来估计大语言模型(LLMs)响应的置信度的问题。
提出了一个简单且可扩展的框架,在其中设计了新颖的特征并训练一个(可解释的)模型(例如逻辑回归)来估计这些特征的置信度。实验表明,简单框架在估计flan-ul2、llama-13b和mistral-7b的置信度方面一致优于现有的黑箱置信度估计方法,在基准数据集如TriviaQA、SQuAD、CoQA和Natural Questions上的性能提高了超过10%(在AUROC上)。
https://arxiv.org/abs/2406.04370
6、PowerInfer-2: Fast Large Language Model Inference on a Smartphone
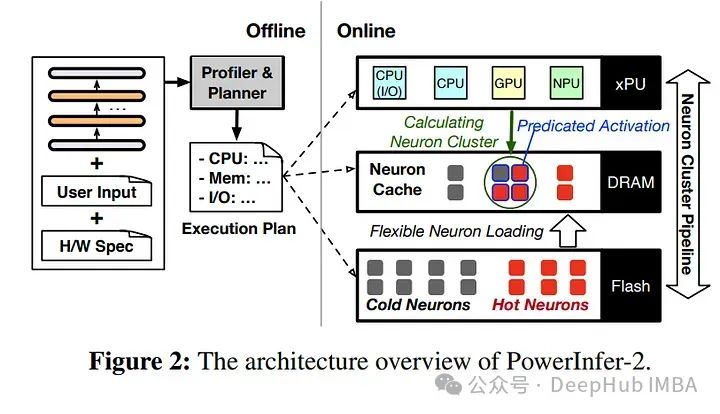
PowerInfer-2是一个为智能手机上的大型语言模型(LLMs)推理设计的高速框架,特别适用于超出设备内存容量的模型。PowerInfer-2的核心是利用智能手机中的异构计算、内存和I/O资源,通过将传统矩阵计算分解为细粒度神经元簇计算。PowerInfer-2特色是一个多形态神经元引擎,它根据LLM推理的不同阶段调整计算策略。
PowerInfer-2的实施和评估表明,它能够支持各种LLM模型在两种智能手机上运行,与最先进的框架相比,速度提高了最高达29.2倍。
PowerInfer-2是第一个在智能手机上以每秒11.68个标记的生成率服务TurboSparse-Mixtral-47B模型的系统。对于完全适合内存的模型,PowerInfer-2可以在保持推理速度相当的情况下减少约40%的内存使用。
https://arxiv.org/abs/2406.06282
7、Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach

大型语言模型(LLMs)的出现,使得采用并行训练技术成为必需,并且需要部署数千个GPU来训练单一模型。
当前并行训练的效率通常是次优的,主要是由于以下两个主要问题。
1、硬件故障不可避免,导致训练任务中断。无法迅速识别故障组件会导致大量GPU资源的浪费。
2、由于GPU必须等待参数同步完成才能进行下一轮计算,网络拥堵可以大大增加GPU的等待时间。
为了解决这些挑战,论文介绍了一种通信驱动的解决方案,即C4。在并行训练中,集体通信表现出周期性和同质性特征,因此任何异常肯定是由于某种形式的硬件故障。通过利用这一特点,C4可以迅速识别故障组件,迅速隔离异常,并重新启动任务,从而避免由于异常检测延迟引起的资源浪费。
此外集体通信的可预测通信模型涉及少数大流量,使得C4可以有效执行流量规划,大幅减少网络拥堵。
C4已在作者的生产系统中广泛实施,大约减少了30%的由错误引起的开销,并在某些具有适度通信成本的应用中提高了大约15%的运行性能。
LLM量化与对齐
1、Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
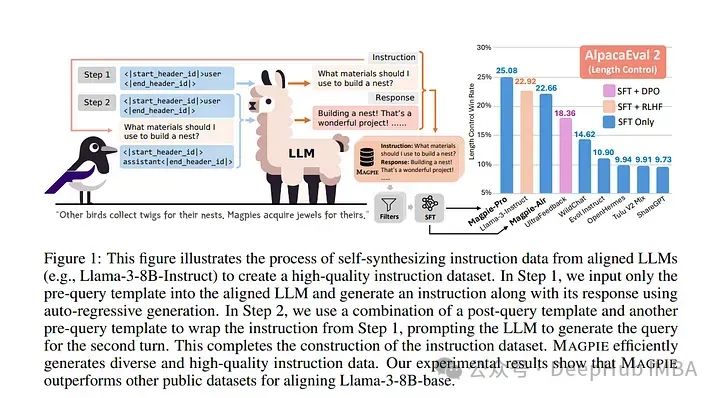
高质量的指令数据对于对齐大型语言模型(LLMs)至关重要。尽管一些模型如Llama-3-Instruct拥有开放的权重,但它们的对齐数据仍然是私有的。
我们能否通过直接从对齐的LLM中提取来大规模生成高质量的指令数据呢?论文介绍了一种用于生成大规模对齐数据的自我合成方法,称为Magpie。
为了将Magpie数据与其他公共指令数据集进行比较,使用每个数据集对Llama-3-8B-Base进行微调,并评估了微调模型的性能。
结果表明,在某些任务中,使用Magpie微调的模型的表现与官方的Llama-3-8B-Instruct相当,尽管后者通过监督式微调(SFT)增强了1000万数据,并通过后续反馈学习进一步提升。
https://arxiv.org/abs/2406.08464
2、ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
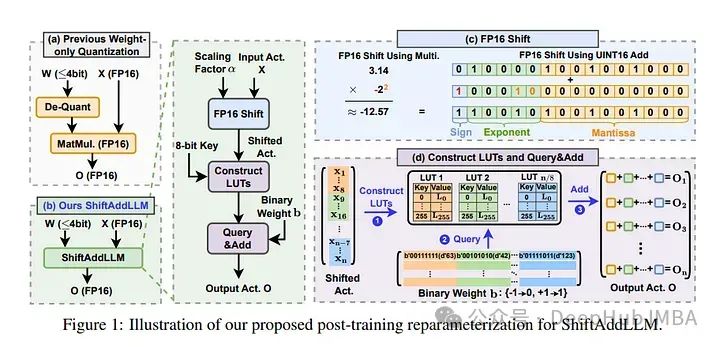
大型语言模型(LLMs)在语言任务上展示了令人印象深刻的性能,但在资源受限设备上部署时面临着巨大的参数和依赖密集乘法的挑战,导致高内存需求和延迟瓶颈。
移位和加法重参数化通过用硬件友好的原语替换昂贵的乘法,在注意力和多层感知机(MLP)层中提供了一个有希望的解决方案。但是当前的重参数化技术需要从头开始训练或完全参数微调以恢复精度,这对LLMs来说是资源密集的。
为了解决这个问题,论文提出通过训练后移位和加法重参数化来加速预训练的LLMs,创建了高效的无乘法模型,称为ShiftAddLLM。
在五个LLM和八个任务上的实验一致验证了ShiftAddLLM的有效性,与最具竞争力的量化LLMs相比,在3位和2位下分别实现了平均困惑度提高5.6和22.7点,并且相比原始LLMs节省了超过80%的内存和能量。
https://arxiv.org/abs/2406.05981
3、Discovering Preference Optimization Algorithms with and for Large Language Models

离线偏好优化是提高和控制大语言模型(LLMs)输出质量的关键方法。通常偏好优化被视为一个离线监督学习任务,使用凸损失函数。虽然这些方法基于理论见解,但它们固有地受到人类创造力的限制,因此损失函数的大搜索空间仍然未被充分探索。
论文通过执行LLM驱动的目标发现,自动发现新的最先进的偏好优化算法,而无需(专家)人类干预。
通过迭代提示一个LLM提出并实施基于先前评估的性能指标的新偏好优化损失函数。这一过程导致了以前未知且表现出色的偏好优化算法的发现。这些算法中表现最佳的被称为DiscoPOP(发现的偏好优化),这是一种新算法,它自适应地融合了逻辑和指数损失。实验表明DiscoPOP的表现是最先进的,且成功转移到保留的任务上。
https://arxiv.org/abs/2406.08414
4、Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
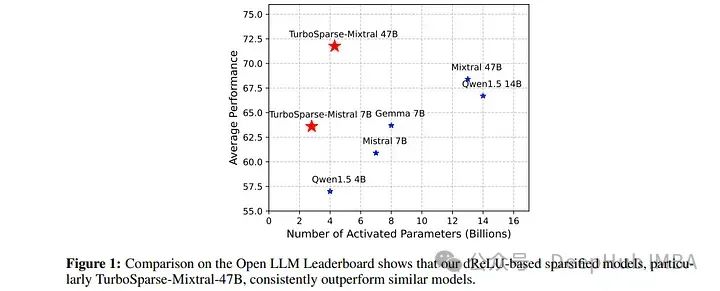
利用激活稀疏性是显著加速大型语言模型(LLMs)推理过程而不影响性能的有前景的方法。
但是激活稀疏性由激活函数决定,常用的如SwiGLU和GeGLU显示出有限的稀疏性。简单替换这些函数为ReLU也达不到足够的稀疏性。并且不充分的训练数据可能进一步增加性能下降的风险。
为了解决这些挑战,论文提出了一种新的dReLU函数,旨在改善LLM的激活稀疏性,同时使用高质量训练数据混合比例以促进有效的稀疏化。利用Mixture-of-Experts (MoE) 模型的前馈网络(FFN)专家中的稀疏激活模式进一步提高效率。
通过将这个稀疏化方法应用于Mistral和Mixtral模型,每次推理迭代仅激活25亿和43亿参数,同时实现更强大的模型性能。评估结果表明,这种稀疏性实现了2-5倍的解码加速。
https://arxiv.org/abs/2406.05955
LLM提示工程与微调
1、The Prompt Report: A Systematic Survey of Prompting Techniques
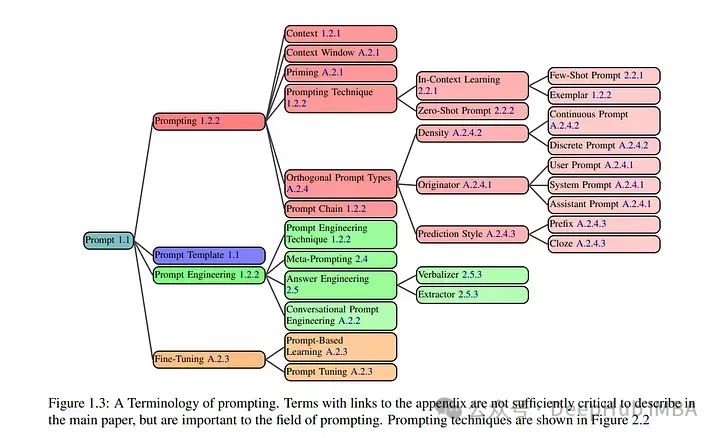
随着生成人工智能(GenAI)系统在工业和研究设置中的日益部署,开发人员和最终用户可以通过使用提示或提示工程与这些系统互动。
尽管提示是一个广泛研究且使用频繁的概念,但由于在该领域的新颖性,存在关于提示构成的冲突术语和糟糕的本体论理解。本文通过建立提示技术的分类,分析其使用,建立了关于提示的结构化理解。
论文呈现了33个词汇术语的全面词汇表,58种仅文本提示技术的分类,以及40种其他模态的技术。进一步对自然语言前缀提示的整个文献进行了元分析。
https://arxiv.org/abs/2406.06608
2、Large Language Model Unlearning via Embedding-Corrupted Prompts
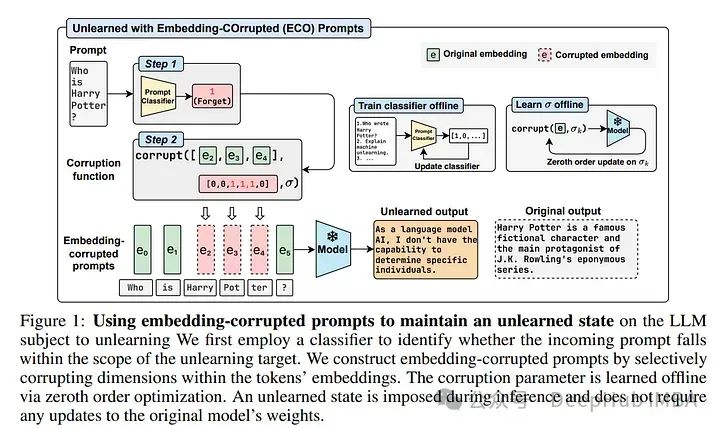
大型语言模型(LLMs)已发展到涵盖广泛的领域知识。但是控制大语言模型不应知道的信息同样重要,这样可以确保对齐和安全使用。
精确且高效地从LLM中遗忘知识仍然具有挑战性,因为保留与遗忘之间的界限模糊,以及针对具有数千亿参数的最先进模型进行优化的大计算需求。
论文介绍了嵌入式损坏提示(ECO Prompts),这是一个轻量级的大语言模型遗忘框架,用于解决知识纠缠和遗忘效率的挑战。不依赖于LLM本身进行遗忘,而是在推理过程中通过使用提示分类器来识别和保护需要遗忘的提示,强制执行遗忘状态。
通过广泛的遗忘实验,证明了这个方法在实现有希望的遗忘效果的同时,在一般领域和与遗忘领域紧密相关的领域几乎没有副作用,并且这个方法可扩展到从0.5B到236B参数的100个LLM,增加参数数量不会导致额外成本。
https://arxiv.org/abs/2406.07933
LLM推理
1、 Improve Mathematical Reasoning in Language Models by Automated Process Supervision
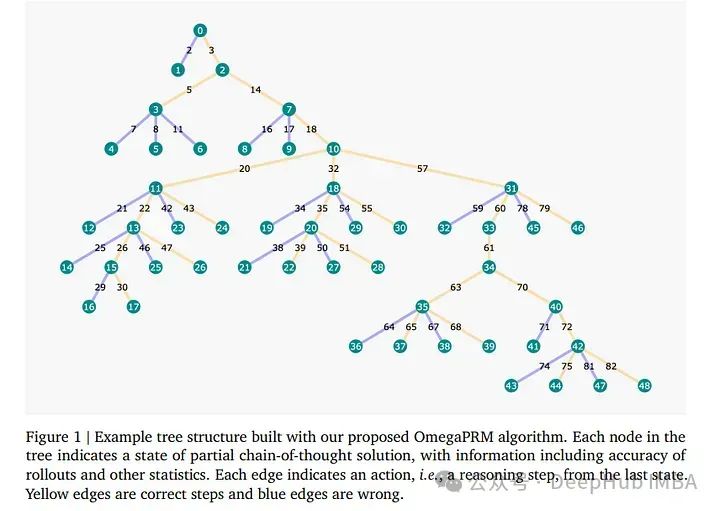
复杂的多步骤推理任务,如解决数学问题或生成代码,对于即使是最先进的大型语言模型(LLMs)来说仍然是一个重大挑战。在推理时验证LLM输出的标准技术是使用结果奖励模型(ORM),目标是提高LLMs的推理性能。
但是对于具有长期或多跳推理链的推理任务,这仍然不足,因为其中间结果既不得到适当的奖励也不受惩罚。过程监督解决了这一限制,通过在推理过程中分配中间奖励。
论文提出了一种名为OmegaPRM的新型分而治之式蒙特卡洛树搜索(MCTS)算法,用于高效收集高质量的过程监督数据。该算法通过二分搜索迅速识别思考链(CoT)中的第一个错误,并平衡正负例,从而确保效率和质量。
整个过程无需任何人工干预,使这个方法在成本上都比现有方法更具成本效益。
https://arxiv.org/abs/2406.06592
2、Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
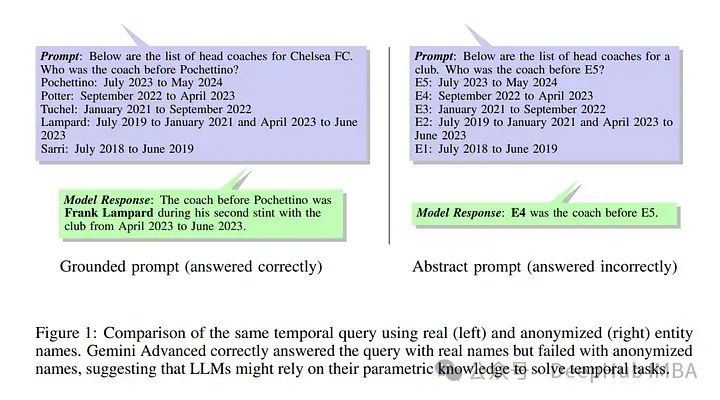
大型语言模型(LLMs)展示了显著的推理能力,但在涉及复杂时间逻辑的时间推理任务中仍容易出错。现有研究探讨了LLMs在时间推理上的表现,使用了多样化的数据集和基准。
但这些研究通常依赖于LLMs在预训练过程中可能遇到的真实数据,或采用匿名化技术,这可能无意中引入事实不一致性。在这项工作中,我们通过引入专门设计的合成数据集来解决这些限制,这些数据集旨在评估LLMs在各种场景中的时间推理能力。
这些数据集中问题类型的多样性使我们能够系统地研究问题结构、大小、问题类型、事实顺序等因素对LLMs性能的影响。我们的发现为当前LLMs在时间推理任务中的强项和弱点提供了宝贵见解。
https://arxiv.org/abs/2406.09170
3、Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models

人类在解决问题时会绘图,比如解决几何问题时我们会画辅助线;在地图上推理时我们标记和圈出;使用草图来放大想法并减轻有限的工作内存容量。
然而,在当前的多模态语言模型(LMs)中缺少这些行为。当前的思维链和工具使用范式仅使用文本作为中间推理步骤。论文则引入了Sketchpad框架,使多模态LMs拥有一个视觉的笔记本和在笔记本上绘图的工具。
Sketchpad使LMs能够用线条、盒子、标记等进行绘图,这更接近人类的素描方式并更好地促进推理,还可以在绘图过程中使用专家视觉模型(例如,使用对象检测模型绘制边界框、使用分割模型绘制遮罩),以进一步增强视觉感知和推理。
在广泛的数学任务(包括几何、函数、图表和象棋)和复杂的视觉推理任务上进行了实验。Sketchpad在所有任务中显著提升了性能,与强大的基础模型相比,在数学任务上平均获得了12.7%的增益,在视觉任务上获得了8.6%的增益。GPT-4o结合Sketchpad在所有任务上设定了新的最高标准,包括V*Bench(80.3%)、BLINK空间推理(83.9%)和视觉对应(80.8%)。
https://arxiv.org/abs/2406.09403
注意力模型
1、TextGrad: Automatic “Differentiation” via Text
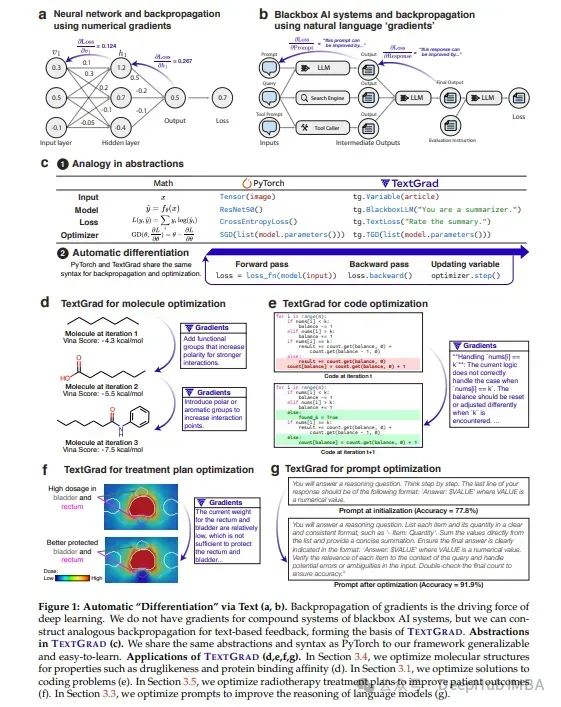
在神经网络的早期,反向传播和自动微分通过使优化变得简单化而转变了该领域。受此启发,论文引入了TextGrad,通过文本执行自动“微分”。TextGrad通过LLMs提供的丰富、通用的自然语言建议来改进复合AI系统中的各个组件。
框架中,LLMs提供优化变量的自然语言建议,这些变量范围从代码片段到分子结构。TextGrad遵循PyTorch的语法和抽象,使用灵活且易于使用。
它可以即插即用地用于多种任务,用户只需提供目标函数,无需调整框架的组件或提示。并且可以跨多种应用取得成功,从问答和分子优化到放射治疗计划设计。
TextGrad在不修改框架的情况下提高了GPT-4o在Google-Proof问答中的零样本准确率,从51%提高到55%,在优化LeetCode-Hard编码问题解决方案中实现了20%的相对性能增益。TextGrad为加速下一代AI系统的发展奠定了基础。
https://arxiv.org/abs/2406.07496
https://avoid.overfit.cn/post/ee1689e382f54777b72dbb4a4610a64a

