
近年来,大语言模型(LLM)在各个领域取得了显著成效。但现有的 Transformer 架构存在计算复杂度高、内存消耗大等问题。而状态空间模型(SSM)如 Mamba 虽然具有常数复杂度和优化的硬件性能,但在记忆回溯任务上表现较弱。针对这一问题,NVIDIA 提出了 Hymba 架构,通过在同一层中结合注意力头和 SSM 头,以实现两种架构优势的互补。
核心创新
Hymba 的核心创新主要包括三个方面:
- 并行混合头设计:
- 在同一层内并行集成注意力头和 SSM 头
- 注意力机制提供高分辨率记忆回溯能力
- SSM 提供高效的上下文总结能力
- 这种设计相比 Zamba 和 Jamba 等只在不同层使用两种机制的方法更加灵活
- 可学习的元令牌(Meta Tokens):
- 在输入序列前添加可学习的元令牌
- 这些令牌与所有后续令牌交互
- 充当知识的压缩表示
- 提高了回溯和通用任务性能
- KV 缓存优化:
- 在层间共享 KV 缓存
- 大多数层使用滑动窗口注意力机制
- 显著减少了内存和计算成本
架构设计
如论文图 1 所示,Hymba 的混合头模块包含:

- 输入处理:
- 输入序列前添加 Meta Tokens
- 通过投影层将输入转换为查询、键、值以及 SSM 特征
- 并行处理:
- 注意力头处理高精度记忆回溯
- SSM 头进行高效的上下文总结
- 两种头并行处理相同的输入信息
- 输出融合:
- 对注意力头和 SSM 头的输出进行归一化
- 通过可学习的向量进行重新缩放
- 最后取平均得到最终输出
性能优势
相比现有模型,Hymba-1.5B 在多个方面都展现出显著优势:
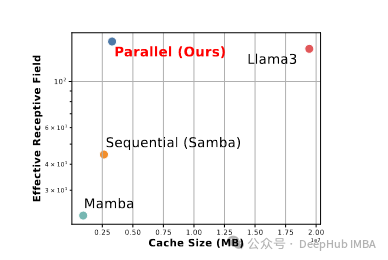
- 与 Llama 3.2 3B 相比:
- 准确率提高 1.32%
- 缓存大小减少 11.67 倍
- 吞吐量提高 3.49 倍
- 与同等规模(2B 以下)模型相比:
- 在常识推理任务上取得最好性能
- 需要的缓存大小显著减小
- 具有更高的处理速度
- 指令微调后的变体 Hymba-1.5B-Instruct:
- 在 GSM8K 和 GPQA 等基准测试上表现优异
- 经常超越更大规模的模型
Hymba 架构实现与实验评估
1. 融合混合头模块设计
Hymba 提出了一个统一且对称的模块设计公式。对于输入序列 X̃(原始输入序列 X 加上元令牌),主要包括:
输入投影:
- 使用 Win_proj = [WQ, WK, WV, WSSM, WG] 进行投影
- 生成注意力头的查询、键、值
- 生成 SSM 头的输入特征和门控信号
注意力头输出:
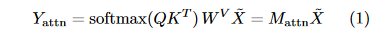
SSM 头输出:
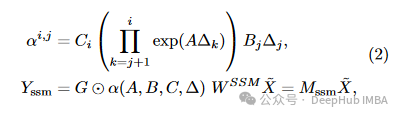
输出融合:
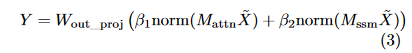
其中 β1 和 β2 是可学习的向量,用于重新缩放各通道的输出。
2. KV 缓存优化策略
全局与局部注意力结合:
- 仅在关键层(第一层、中间层和最后一层)使用全局注意力
- 其他层使用滑动窗口注意力(SWA)
- 该策略在维持性能的同时显著提升效率
跨层 KV 共享:
- 相邻层间共享键值缓存
- 减少参数冗余
- 节省的参数可以重新分配给其他模型组件
3. 元令牌的创新应用
主要功能:
- 防止令牌重写:为模型提供独立于输入的令牌
- 处理"强制关注"问题:通过修改 softmax 的分母来优化注意力分布
- KV 缓存和 SSM 状态的初始化:可以看作是一种学习到的提示调优
实现效果:
- 降低了注意力图的熵
- 帮助模型更好地聚焦于重要信息
- 提升了回溯能力和常识推理性能
实验评估
1. 基准测试性能
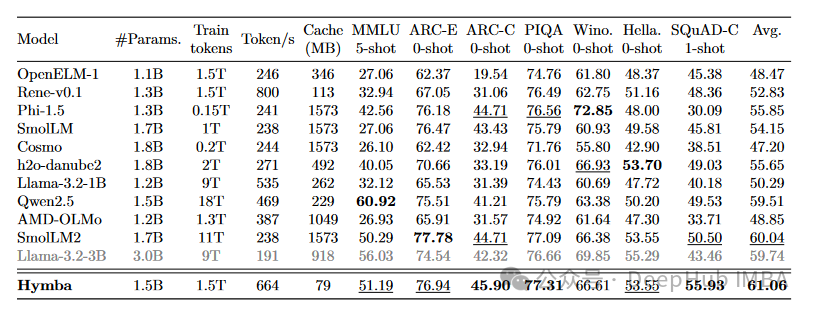
如论文表 2 所示,在 1.5T 预训练数据条件下,Hymba-1.5B 相比同规模模型具有明显优势:
- 与 SmolLM2-1.7B 比较:
- 平均准确率提升 1.02%
- 缓存大小减少 19.91 倍
- 吞吐量提高 2.79 倍
- 与其他 2T 以下训练数据的模型比较:
- 相比 Phi-1.5 提升平均准确率 5.21%
- 相比 h2o-danube2-1.8B 提升 5.41%
2. 指令微调效果
- 基础指令微调:
- 采用两阶段策略:全量微调(FFT)和直接偏好优化(DPO)
- 在 GSM8K、GPQA 等任务上达到同类最佳性能
- DoRA 参数高效微调:
- 在 RoleBench 上超越了 Llama-3.1-8B-Instruct 约 2.4%
- 展示了模型在参数高效微调场景的潜力
3. 消融实验结果
- 架构组件分析:
- 混合头结构比顺序叠加提升显著
- KV 缓存优化在保持性能的同时大幅提升效率
- 元令牌的引入进一步提升了模型表现
- 头部重要性分析:
- SSM 头在第一层对语言建模至关重要
- 移除单个注意力头平均导致 0.24%性能下降
- 移除单个 SSM 头平均导致 1.1%性能下降
这些实验结果充分证明了 Hymba 架构的有效性和优势。
Hymba 模型训练实现细节
1. 预训练策略
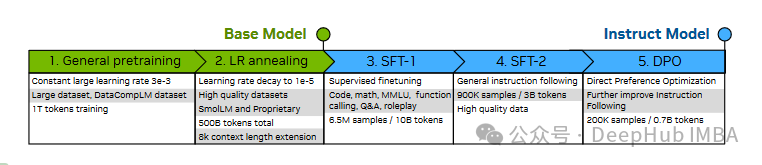
如论文图 8 所示,Hymba 采用了多阶段的训练流程:
基础预训练阶段:
- 使用较大学习率(3e-3)
- 采用 DataCompLM 数据集
- 训练 1T 个 token
学习率退火阶段:
- 逐渐将学习率降至 1e-5
- 使用高质量数据集
- 总共处理约 500B 个 token
上下文扩展:
- 将序列长度从 2K 扩展到 8K
- 调整 ROPE 基础参数
- 进一步提升长序列处理能力
2. 模型系列规格
根据论文表 11 的描述,Hymba 提供了三种不同规格的模型:
- Hymba-125M:
- 24 个模块
- 隐藏层大小 512
- 8 个注意力头
- 总参数量约 125M
- Hymba-350M:
- 32 个模块
- 隐藏层大小 768
- 12 个注意力头
- 总参数量约 350M
- Hymba-1.5B:
- 32 个模块
- 隐藏层大小 1600
- 25 个注意力头
- 总参数量约 1.52B
3. 指令微调实现
- 监督微调(SFT):
- 第一阶段:使用 900K 样本/3B tokens
- 第二阶段:使用 6.5M 样本/10B tokens
- 涵盖代码、数学、MMLU 等多个领域
- DPO 优化:
- 使用 200K 样本/0.7B tokens
- 进一步改进指令遵循能力
- 采用余弦学习率调度
实际应用与局限性分析
Hymba 模型在实际应用中展现出独特的优势,特别是在处理长序列文本时表现突出。通过 SSM 实现的高效上下文编码和滑动窗口注意力机制,显著降低了内存消耗,使其非常适合在资源受限的环境中部署。在特定任务上,如数学推理、函数调用和角色扮演等场景,Hymba 表现出与大型模型相媲美的性能,这使其成为一个极具实用价值的轻量级选择。
但是作为一个相对小型的语言模型,Hymba 也存在一些固有的局限性。由于参数量的限制,在处理某些需要深度推理或广泛知识储备的复杂任务时,其表现可能不如参数量更大的模型。此外混合架构的设计虽然创新,但也带来了实现和优化方面的挑战。模型训练过程需要更复杂的调参策略,这增加了模型开发和部署的技术门槛。
未来展望
从技术发展的角度来看,Hymba 的创新架构为语言模型的发展开辟了新的方向。未来的研究可能会进一步探索注意力机制和 SSM 的最优配比,以及更高效的融合策略。随着计算资源的提升和算法的优化,研究者们可能会尝试扩展模型规模,同时保持其高效处理的特性。特别值得关注的是,如何在保持计算效率的同时进一步提升模型性能,这个平衡点的探索将是未来研究的重要方向。
在应用拓展方面,Hymba 展现出的混合架构思路可能会被引入到更多领域。例如,将这种架构应用到多模态任务中,探索在视觉-语言交互等场景下的效果。同时,针对特定垂直领域的优化也是一个重要方向,通过专门的微调策略,可能会在特定场景下取得更好的表现。
Hymba 的出现为解决语言模型在效率和性能之间的权衡提供了新的思路。虽然目前仍存在一些局限性,但其创新的架构设计和实验结果表明,这种混合架构很可能成为未来语言模型发展的一个重要方向。随着技术的不断进步和应用场景的拓展,我们有理由期待基于这种架构的更多突破性进展。
论文地址:
https://avoid.overfit.cn/post/06def3f77bca4775a8e82a2005b2c19c

