
在机器学习和数据分析中,我们经常需要验证数据是否符合某种特定的分布(如正态分布)。这种验证对于选择合适的统计方法和机器学习模型至关重要。例如许多统计检验和机器学习算法都假设数据服从正态分布。如果这个假设不成立,我们可能需要对数据进行转换或选择其他更适合的方法。
Q-Q 图(Quantile-Quantile Plot)就是为解决这个问题而设计的强大可视化工具。它能够直观地展示数据分布与理论分布之间的差异,帮助我们做出正确的分析决策。

统计学基础:理解分布与分位数
什么是分布?
在开始理解 Q-Q 图之前,我们需要先明确什么是分布。分布描述了数据在不同值上的分布情况。例如:
- 正态分布:呈钟形,数据对称分布在平均值周围
- 偏态分布:数据分布不对称,可能向左或向右倾斜
- 均匀分布:数据在某个范围内均匀分布
分位数的概念
分位数是将有序数据划分为等份的点。最常见的例子是:
- 中位数:将数据分成两等份的点(0.5 分位数)
- 四分位数:将数据分成四等份的点(0.25, 0.5, 0.75 分位数)
- 百分位数:将数据分成 100 等份的点(0.01, 0.02, ..., 0.99 分位数)
为什么使用分位数?
分位数有几个重要特性:
- 不受极端值影响:相比均值,分位数对异常值更稳健
- 保持数据的顺序关系:反映了数据的分布特征
- 易于比较不同尺度的数据:通过标准化后的位置进行比较
Q-Q 图的工作原理
Q-Q 图通过比较两个分布的分位数来判断它们的相似性。具体来说:
数据准备:
- 将实际数据从小到大排序
- 生成理论分布(如正态分布)的对应分位数点
分位数计算:
- 对实际数据计算分位数值
- 对理论分布计算相同位置的分位数值
绘图对比:
- 横轴:理论分布的分位数
- 纵轴:实际数据的分位数
- 如果两个分布相似,点会落在对角线附近
Q-Q 图的解读规则:
- 点落在直线上:两个分布非常相似
- 点偏离直线但呈 S 形:数据可能需要简单变换
- 点严重偏离直线:分布差异显著
在下面的示例中,我们可以看到在中心区域接近正态分布,但在尾部有明显偏离,这说明它具有"肥尾"特征。

基础代码实现与解释
下面是一个基础的 Q-Q 图实现示例,我们会详细解释每个步骤:
quantiles=lambdaq : np.arange(1/q,1,1/q)
normal_dist=lambdal : np.random.standard_normal(l)
q_count=100 ## 设置分位数组数量,越大则点越密集
## 第一步:计算实际数据(BTC收益率)的分位数
btc_ret=df_btc.close.pct_change()*100 ## 计算百分比收益率
btc_q=btc_ret.quantile(quantiles(q_count)) ## 计算分位数
## 第二步:生成理论分布(标准正态分布)样本
st_nm_dist=pd.Series(normal_dist(len(btc_ret))) ## 生成正态分布样本
nd_q=st_nm_dist.quantile(quantiles(q_count)) ## 计算其分位数
## 第三步:创建Q-Q图
plt.scatter(nd_q,btc_q) ## 绘制散点图
## 第四步:添加参考线(理想情况下的直线)
x,y=nd_q,btc_q
fromscipyimportstats
lr_params=stats.linregress(x,y) ## 计算线性回归参数
slope , intercept=lr_params[0] , lr_params[1]
lr_model=slope*x+intercept
plt.plot( x , lr_model , color='red')
## 添加图表说明
plt.xlabel('Normal distribution')
plt.ylabel('BTC Returns')
plt.title('Q-Q Plot')这段代码的每个部分都有其特定的作用:
quantiles函数创建均匀分布的分位点normal_dist函数生成标准正态分布的随机样本pct_change()计算收益率,乘以 100 转换为百分比quantile()函数计算实际分位数值stats.linregress()计算理想参考线的参数
接下来,我们将继续探讨更多应用场景和高级特性。
Q-Q 图在机器学习中的应用
数据预处理中的应用
在机器学习中,数据预处理是极其重要的步骤。Q-Q 图可以帮助我们:
检测异常值
- 观察点是否严重偏离直线
- 尤其关注图的两端点
- 帮助决定是否需要处理异常值
选择数据转换方法
- 如果 Q-Q 图呈现系统性偏差
- 可以尝试对数转换、Box-Cox 转换等
- 转换后再次用 Q-Q 图验证效果
验证模型假设
- 许多机器学习模型假设残差呈正态分布
- 使用 Q-Q 图检验这一假设
- 帮助选择合适的模型
金融数据分析实例
我们以比特币和以太坊的收益率分布对比:
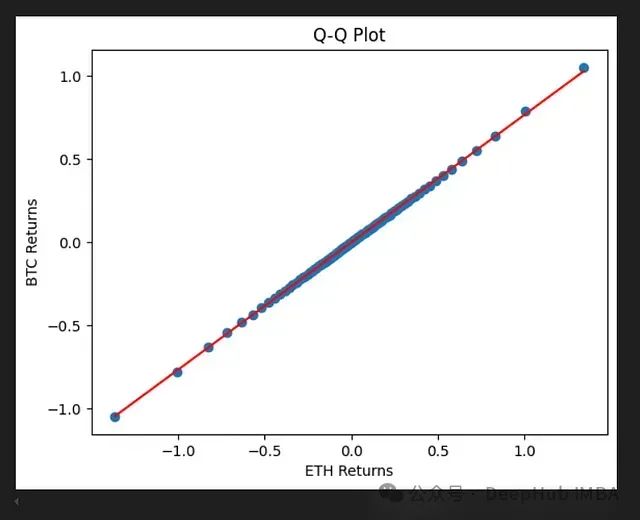
BTC 与 ETH 收益率分布对比分析
从这个 Q-Q 图中,我们可以观察到:
- 两种加密货币的收益率分布高度相似
- 这种相似性表明它们可能受相似的市场因素影响
- 可以用于构建投资组合或风险管理策略
机器学习应用提示:这种分布相似性可以用于构建预测模型,例如使用一个资产的数据来预测另一个资产的行为。
传统市场与加密货币市场对比
下面是 BTC 与 Nifty 指数的对比分析:
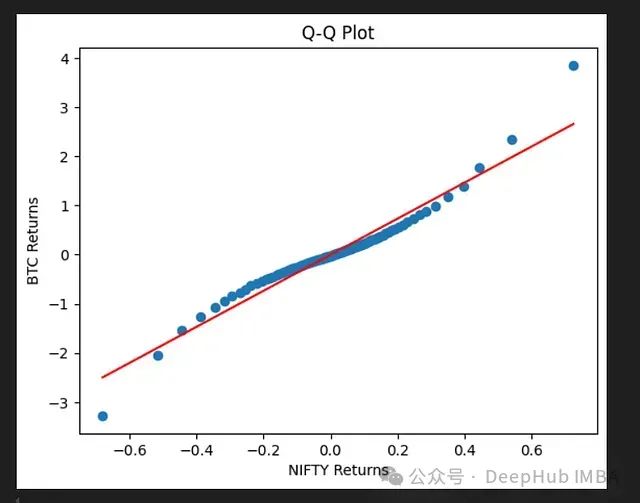
传统市场与加密货币市场的分布特征对比
这个对比揭示了重要信息:
- 两个市场存在一定的分布相似性
- 但加密货币市场可能表现出更极端的波动
- 这种差异对机器学习模型的选择有重要影响
高级概念:分位数计算与插值
插值的重要性
在机器学习中,数据往往是离散的样本点,但我们需要估计连续分布的特征。插值技术可以帮助我们:
- 更准确地估计分位数
- 生成平滑的 Q-Q 图
- 提高统计推断的准确性
插值计算详解
考虑序列 s = [1,2,3],我们来详细解释插值过程:
示例 1:计算 0.1 分位数
步骤1:计算理论位置 = (n-1)*p = (3-1)*0.1 = 0.2
步骤2:确定相邻点:
- 下界:index 0,值为1
- 上界:index 1,值为2
步骤3:线性插值:1 + 0.2*(2-1) = 1.2这个计算过程在机器学习中很重要,因为:
- 它提供了更准确的分布估计
- 有助于生成更平滑的特征
- 改善模型的泛化能力
实际应用中的考虑因素
在使用 Q-Q 图进行机器学习数据分析时,需要注意:
- 样本量的影响- 样本太少:分位数估计不准确- 样本太多:计算开销增大- 建议:根据具体需求选择合适的分位点数量
- 异常值处理- Q-Q 图能很好地展示异常值- 需要结合业务场景决定是否处理- 考虑使用稳健的统计方法
- 可视化优化- 考虑添加置信区间- 可以使用不同颜色标记不同区域- 添加适当的图例和标签
在机器学习流程中的应用建议
- 数据探索阶段- 使用 Q-Q 图快速评估数据分布- 识别潜在的数据问题- 确定预处理策略
- 特征工程阶段- 验证转换效果- 评估特征分布- 指导特征选择
- 模型验证阶段- 检查残差分布- 评估模型假设- 指导模型改进
总结
Q-Q 图在机器学习领域扮演着多重重要角色。作为一种统计可视化工具,它首先能帮助研究人员深入理解数据的分布特征,让我们直观地看到数据是否符合某种理论分布。通过 Q-Q 图的分析结果,研究人员可以更好地制定数据预处理的策略,比如确定是否需要进行数据转换或标准化。此外 Q-Q 图还能帮助验证模型的各种统计假设,为模型的选择和优化提供重要参考。在统计推断方面,Q-Q 图提供了直观的可视化支持,使得统计分析的结果更容易理解和解释。
对于想要学习使用 Q-Q 图的初学者,建议采取循序渐进的学习方法。可以先从简单的、规模较小的数据集开始练习,熟悉 Q-Q 图的基本特征和解读方法。在分析过程中,重要的是要把图形特征与实际问题结合起来解释,建立起理论与实践的连接。同时要特别注意观察图中出现的异常模式,这往往能揭示数据中的重要信息。最后建议多尝试不同的数据转换方法,观察数据在不同转换下的表现,这样能够更全面地理解数据的特征和处理方法的效果。
https://avoid.overfit.cn/post/7794c4935b424ec5ae1eafab820a886e

