
在分析变量间复杂依赖关系时,传统统计工具往往难以胜任。Copula作为一种将边际分布与联合依赖结构解耦的数学框架,为解决这类问题提供了有效途径。本文将深入探讨 copula 的基础理论、运作机制及其在数据科学领域的实际应用。
从数学本质来看,copula 是一类能够将随机变量间的依赖关系与其边际分布分离的函数。这种分离特性使 copula 在多元分析中具有独特优势,特别是在处理非线性依赖关系或异质分布变量时。
以年龄与收入的关系分析为例,copula 能够独立地对各个变量的分布特征及其相互依赖结构进行建模,从而实现更为准确和灵活的统计建模。

概率论基础
在深入 copula 理论之前,有必要回顾几个关键的概率论概念,以建立清晰的理论基础。
概率密度函数(PDF)
概率密度函数 f(x)描述了随机变量 X 取特定值 x 的概率密度。标准正态分布的概率密度函数可表示为:
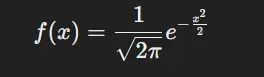
需要注意的是,虽然 f(x)本身并不直接表示概率值,但其在定义域上的积分恒等于 1,这保证了概率的归一化特性。
累积分布函数(CDF)
累积分布函数 F(x)表示随机变量 X 取值不超过 x 的概率。其数学定义为:
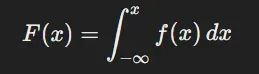
下面的代码展示了标准正态分布的 PDF 和 CDF 的可视化对比:
importplotly.graph_objectsasgo
fromplotly.subplotsimportmake_subplots
importnumpyasnp
importscipy.statsasstats
defplot_cdf_pdf_plotly():
## 生成[-4,4]区间内的10000个等距采样点
x=np.linspace(-4.0, 4.0, 10000)
## 计算对应的概率密度值和累积分布值
pdf=stats.norm.pdf(x)
cdf=stats.norm.cdf(x)
fig=make_subplots(rows=1, cols=2, subplot_titles=("PDF", "CDF"))
fig.add_trace(
go.Scatter(x=x, y=pdf),
row=1, col=1
)
fig.update_xaxes(title_text="x", row=1, col=1)
fig.update_yaxes(title_text="f(x)", row=1, col=1)
fig.add_trace(
go.Scatter(x=x, y=cdf),
row=1, col=2
)
fig.update_xaxes(title_text="x", row=1, col=2)
fig.update_yaxes(title_text="F(x)", row=1, col=2)
## 配置图表布局参数
fig.update_layout(height=400, width=900, showlegend=False)
fig.show()
plot_cdf_pdf_plotly()概率积分变换理论
概率积分变换是 copula 理论的核心数学基础。对于任意具有累积分布函数 F(x)的随机变量 X,通过变换:
Y=F(X)
可将其转换为[0,1]区间上的均匀分布随机变量 Y。这一变换在 copula 理论中具有重要意义,因为它为依赖关系建模提供了统一的概率度量空间。
以下代码演示了从正态分布到均匀分布的变换过程:
## 生成正态分布随机样本并进行概率积分变换
X=stats.norm.rvs(size=10000)
X_pit=stats.norm.cdf(X)
## 构建变换前后的对比图
fig=make_subplots(rows=1, cols=2, subplot_titles=("Samples", "Transformed Samples"))Copula 的实践应用
copula 的核心思想在于将多维随机变量的依赖结构与其各个维度的边际分布分离。这一目标通过两个步骤实现:首先将各个变量通过概率积分变换映射到均匀分布,然后通过 copula 函数捕捉它们之间的依赖关系。
高斯 Copula 实例分析
我们通过分析年龄和收入这两个变量来具体说明 copula 的应用。
原始数据分析 首先观察原始数据的分布特征:
df=sample_bivariate_age_income()
scatter_2d(df)通过单变量直方图可以更清晰地观察各变量的分布特征:
dist_1d(df['age'], title='Age')
dist_1d(df['income'], title='Income')边际分布转换 利用
copulas库中的GaussianMultivariate类实现向均匀分布的转换:
copula=GaussianMultivariate()
copula.fit(df)变换后的均匀性检验:
age_cdf=copula.univariates[0].cdf(df['age'])
dist_1d(age_cdf, title='Age')合成数据生成基于高斯 copula 建模的依赖结构,我们可以生成保持原始依赖关系的合成数据:
synthetic=copula.sample(len(df))
compare_2d(df, synthetic)技术要点总结
Copula 框架提供了边际分布与依赖结构的解耦机制,使得统计建模具有高度的可定制性和适应性。Copula 在金融领域(如资产相关性建模)、气象学等需要处理复杂依赖结构的领域有着广泛应用。现代统计计算库(如
copulas)为实现基于 copula 的模型提供了高效的工具支持,便于在实际应用中进行合成数据生成、风险建模等任务。
Copula 不仅是一个理论构造,更是连接统计理论与实际应用的重要工具。无论是在金融数据分析、真实场景模拟,还是合成数据集生成等方面,copula 都展现出其独特的理论价值和实用性。
Copula 在合成数据生成中的应用
在数据隐私保护要求日益严格或数据获取受限的背景下,合成数据在机器学习领域显示出越来越重要的价值。本节将以 Scikit-learn 提供的数据集为例,展示如何利用 copula 分布生成高质量的合成数据。
这一案例的核心目标是验证基于 copula 生成的合成数据在训练机器学习模型时的有效性,通过在真实数据集上的性能评估来验证合成数据保留原始统计特性的能力。
数据集准备
本实验使用 Scikit-learn 提供的糖尿病数据集进行演示,相关方法可以推广到任意数据集。为确保实验的可重复性,我们采用以下方式准备数据:
importwarnings
warnings.filterwarnings('ignore')
fromsklearn.datasetsimportload_diabetes
fromsklearn.model_selectionimporttrain_test_split
X, y=load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test=train_test_split(X, y, random_state=42)合成数据生成实现
我们选择高斯 Copula作为依赖结构建模的核心工具。这种方法的优势在于能够有效地分离和保持特征间的依赖关系,同时保持各个特征的边际分布特性。
具体实现代码如下:
importnumpyasnp
fromcopulas.multivariateimportGaussianMultivariate
defcreate_synthetic(X, y):
"""
构建合成数据生成器
将特征矩阵X和目标变量y组合,使用高斯copula建模,
生成具有相似统计特性的合成数据集
返回:合成特征矩阵和目标变量
"""
dataset=np.concatenate([X, np.expand_dims(y, 1)], axis=1)
model=GaussianMultivariate()
model.fit(dataset)
synthetic=model.sample(len(dataset))
X_synthetic=synthetic.values[:, :-1]
y_synthetic=synthetic.values[:, -1]
returnX_synthetic, y_synthetic
## 生成合成数据
X_synthetic, y_synthetic=create_synthetic(X_train, y_train)生成的合成数据集在保持统计特性的同时,避免了直接暴露原始数据,实现了数据共享和隐私保护的平衡。
模型性能验证
我们采用 ElasticNet 回归模型对合成数据的效果进行验证,通过与原始数据训练结果的对比来评估合成数据的质量:
fromsklearn.linear_modelimportElasticNet
## 基于合成数据训练模型
model_synthetic=ElasticNet()
model_synthetic.fit(X_synthetic, y_synthetic)
## 在真实测试集上评估性能
synthetic_score=model_synthetic.score(X_test, y_test)
print(f"Performance of model trained on synthetic data: {synthetic_score:.4f}")同时,我们训练一个基于原始数据的对照模型:
## 基于原始数据训练模型
model_real=ElasticNet()
model_real.fit(X_train, y_train)
## 在真实测试集上评估性能
real_score=model_real.score(X_test, y_test)
print(f"Performance of model trained on real data: {real_score:.4f}")实验结果分析
通过对比两个模型在真实测试集上的表现:
- 合成数据模型性能: ~0.0103
- 原始数据模型性能: ~0.0087
实验结果表明,基于高斯 copula 生成的合成数据成功保留了原始数据集的关键统计特性,使得基于合成数据训练的模型能够达到与原始数据相当的预测性能。
合成数据的价值
合成数据在机器学习实践中具有以下显著优势:
- 隐私保护:实现了数据共享与隐私保护的有效平衡
- 数据增强:为模型训练提供额外的高质量训练样本,提升模型鲁棒性
- 应用灵活性:在真实数据受限的场景下提供可行的替代方案
通过 copula 技术,我们能够生成既保持统计有效性又适用于预测建模的合成数据集,为数据科学实践提供了有力的工具支持。
https://avoid.overfit.cn/post/cfc1587037684e0da7b65f3453c8c361

