
深度强化学习是人工智能领域最具挑战性的研究方向之一,其设计理念源于生物学习系统从经验中优化决策的机制。在众多深度强化学习算法中,软演员-评论家算法(Soft Actor-Critic, SAC)因其在样本效率、探索效果和训练稳定性等方面的优异表现而备受关注。
传统的深度强化学习算法往往在探索-利用权衡、训练稳定性等方面面临挑战。SAC 算法通过引入最大熵强化学习框架,在策略优化过程中自动调节探索程度,有效解决了这些问题。其核心创新在于将熵最大化作为策略优化的额外目标,在保证收敛性的同时维持策略的多样性。
本文将系统阐述 SAC 算法的技术细节,主要包括:
- 基于最大熵框架的 SAC 算法数学原理
- 演员网络与评论家网络的具体架构设计
- 基于 PyTorch 的详细实现方案
- 网络训练的关键技术要点
SAC 算法采用演员-评论家架构,演员网络负责生成动作策略,评论家网络评估动作价值。通过两个网络的协同优化,实现策略的逐步改进。整个训练过程中,演员网络致力于最大化评论家网络预测的 Q 值,同时保持适度的策略探索;评论家网络则不断优化其 Q 值估计的准确性。
接下来,我们将从演员网络的数学原理开始,详细分析 SAC 算法的各个技术组件:
演员(策略)网络
演员是由参数 φ 确定的策略网络,表示为:

这是一个基于状态输出动作的随机策略。它使用神经网络估计均值和对数标准差,从而得到给定状态下动作的分布及其对数概率。对数概率用于熵正则化,即目标函数中包含一个用于最大化概率分布广度(熵)的项,以促进智能体的探索行为。关于熵正则化的具体内容将在后文详述。演员网络的架构如图所示:
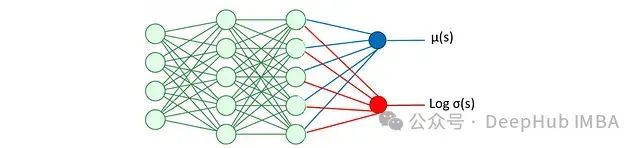
均值 μ(s)和对数 σ(s)用于动作采样:
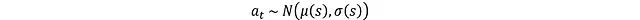
其中 N 表示正态分布。但这个操作存在梯度不可微的问题,需要通过重参数化技巧来解决。
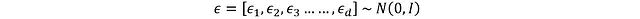
这里 d 表示动作空间维度,每个分量 ε_i 从标准正态分布(均值 0,标准差 1)中采样。应用重参数化技巧:
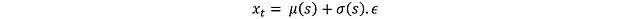
这样就解决了梯度截断问题。接下来通过激活函数将 x_t 转换为标准化动作:
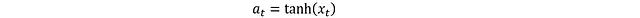
该转换确保动作被限制在[-1,1]区间内。
动作对数概率计算
完成动作计算后,就可以计算奖励和预期回报。演员的损失函数中还包含熵正则化项,用于最大化分布的广度。计算采样动作 𝑎t 的对数概率 Log(πϕ)时,从预 tanh 变换 x_t 开始分析更为便利。
由于 x_t 来自均值 μ(s)和标准差 σ(s)的高斯分布,其概率密度函数(PDF)为:
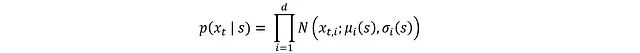
其中各独立分量 x_t,i 的分布为:
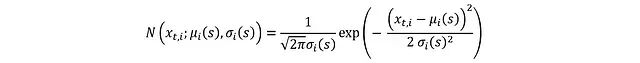
对两边取对数可简化 PDF:
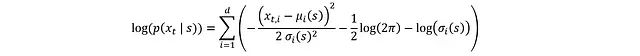
要将其转换为 log(π_ϕ),需要考虑 x_t 到 a_t 的 tanh 变换,这可通过微分链式法则实现:

这个关系的推导基于概率守恒原理:两个变量在给定区间内的概率必须相等:
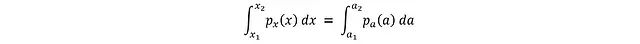
其中 a_i = tanh(x_i)。将区间缩小到无穷小的 dx 和 da:
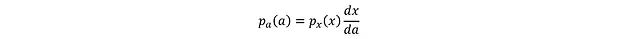
tanh 的导数形式为:
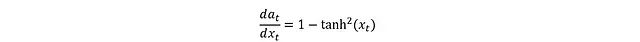
代入得到:
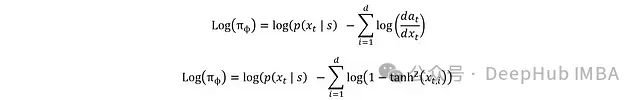
最终可得完整表达式:
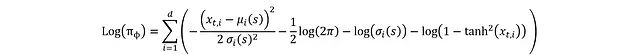
至此完成了演员部分的推导,这里有动作又有对数概率,就可以进行损失函数的计算。下面是这些数学表达式的 PyTorch 实现:
importgymnasiumasgym
fromsrc.utils.loggerimportlogger
fromsrc.models.callbackimportPolicyGradientLossCallback
frompydanticimportField, BaseModel, ConfigDict
fromtypingimportDict, List
importnumpyasnp
importos
frompathlibimportPath
importtorch
importtorch.nnasnn
importtorch.optimasoptim
importtorch.nn.functionalasF
fromtorch.distributionsimportNormal
'''演员网络:估计均值和对数标准差用于熵正则化计算'''
classActor(nn.Module):
def__init__(self,state_dim,action_dim):
super(Actor,self).__init__()
self.net=nn.Sequential(
nn.Linear(state_dim, 100),
nn.ReLU(),
nn.Linear(100,100),
nn.ReLU()
)
self.mean_linear=nn.Linear(100, action_dim)
self.log_std_linear=nn.Linear(100, action_dim)
defforward(self, state):
x=self.net(state)
mean=self.mean_linear(x)
log_std=self.log_std_linear(x)
log_std=torch.clamp(log_std, min=-20, max=2)
returnmean, log_std
defsample(self, state):
mean, log_std=self.forward(state)
std=log_std.exp()
normal=Normal(mean, std)
x_t=normal.rsample() ## 重参数化技巧
y_t=torch.tanh(x_t)
action=y_t
log_prob=normal.log_prob(x_t)
log_prob-=torch.log(1-y_t.pow(2)+1e-6)
log_prob=log_prob.sum(dim=1, keepdim=True)
returnaction, log_prob
在讨论损失函数定义和演员网络的训练过程之前,需要先介绍评论家网络的数学原理。
评论家网络
评论家网络的核心功能是估计状态-动作对的预期回报(Q 值)。这些估计值在训练过程中为演员网络提供指导。评论家网络采用双网络结构,分别提供预期回报的两个独立估计,并选取较小值作为最终估计。这种设计可以有效避免过度估计偏差,同时提升训练稳定性。其结构如图所示:
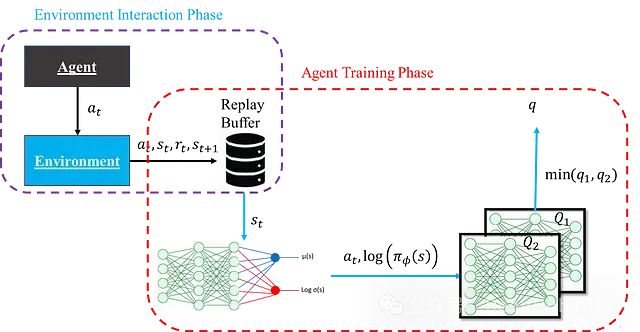
需要说明的是,此时的示意图是简化版本,主要用于理解演员和评论家网络的基本角色,暂不考虑训练稳定性的细节。另外,"智能体"实际上是演员和评论家网络的统称而非独立实体,图中分开表示只是为了清晰展示结构。假设评论家网络暂不需要训练,因为这样可以专注于如何利用评论家网络估计的 Q 值来训练演员网络。演员网络的损失函数表达式为:
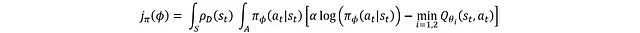
更常见的形式是: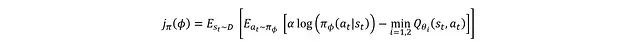
其中 ρD 表示状态分布。损失函数通过对所有动作空间和状态空间的熵项与 Q 值进行积分得到。但在实际应用中,无法直接获取完整的状态分布,因此 ρD 实际上是基于重放缓冲区样本的经验状态分布,期望其能较好地表征整体状态分布特征。
基于该损失函数可以通过反向传播对演员网络进行训练。以下是评论家网络的 PyTorch 实现:
'''评论家网络:定义q1和q2'''
classCritic(nn.Module):
def__init__(self, state_dim, action_dim):
super(Critic, self).__init__()
## Q1网络架构
self.q1_net=nn.Sequential(
nn.Linear(state_dim+action_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
)
## Q2网络架构
self.q2_net=nn.Sequential(
nn.Linear(state_dim+action_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
)
defforward(self, state, action):
sa=torch.cat([state, action], dim=1)
q1=self.q1_net(sa)
q2=self.q2_net(sa)
returnq1, q2前述内容尚未涉及评论家网络自身的训练机制。从重放缓冲区采样的每个数据点包含[s_t, s_{t+1}, a_t, R]。对于状态-动作对的 Q 值,我们可以获得两种不同的估计。
第一种方法是直接将 a_t 和 s_t 输入评论家网络: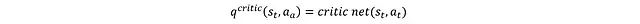
第二种方法是基于贝尔曼方程:
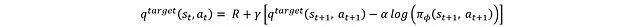
这种方法使用 s_t+1、a_t+1 以及执行动作 a_t 获得的奖励来重新估计。这里使用目标网络而非第一种方法中的评论家网络进行估计。采用目标评论家网络的主要目的是解决训练不稳定性问题。如果同一个评论家网络同时用于生成当前状态和下一状态的 Q 值(用于目标 Q 值),这种耦合会导致网络更新在目标计算的两端产生不一致的传播,从而引起训练不稳定。因此引入独立的目标网络为下一状态的 Q 值提供稳定估计。目标网络作为评论家网络的缓慢更新版本,确保目标 Q 值能够平稳演化。具体结构如图所示:
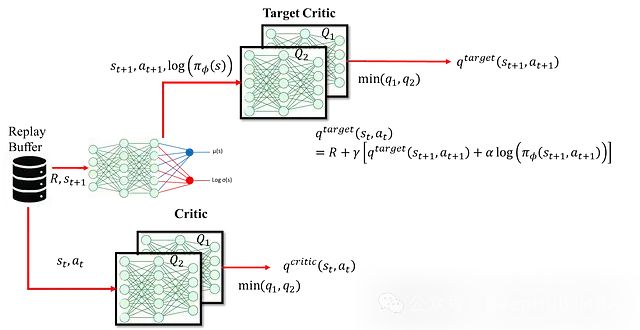
评论家网络的损失函数定义为:
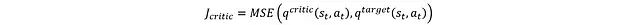
通过该损失函数可以利用反向传播更新评论家网络,而目标网络则采用软更新机制: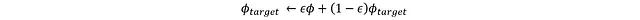
其中 ε 是一个较小的常数,用于限制目标评论家的更新幅度,从而维持训练稳定性。
完整流程
以上内容完整阐述了 SAC 智能体的各个组件。下图展示了完整 SAC 智能体的结构及其计算流程:
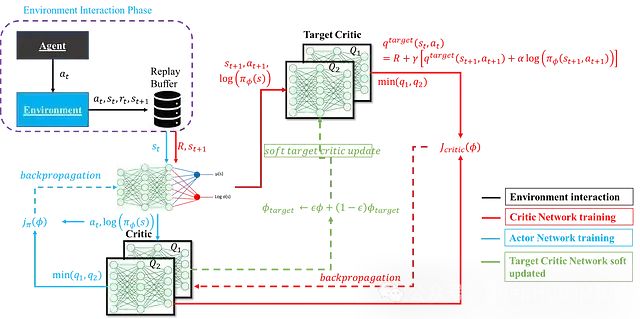
下面是一个综合了前述演员网络、评论家网络及其更新机制的完整 SAC 智能体实现
'''SAC智能体的实现:整合演员网络和评论家网络'''
classSACAgent:
def__init__(self, state_dim, action_dim, learning_rate, device):
self.device=device
self.actor=Actor(state_dim, action_dim).to(device)
self.actor_optimizer=optim.Adam(self.actor.parameters(), lr=learning_rate)
self.critic=Critic(state_dim, action_dim).to(device)
self.critic_optimizer=optim.Adam(self.critic.parameters(), lr=learning_rate)
## 目标网络初始化
self.critic_target=Critic(state_dim, action_dim).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
## 熵温度参数
self.target_entropy=-action_dim
self.log_alpha=torch.zeros(1, requires_grad=True, device=device)
self.alpha_optimizer=optim.Adam([self.log_alpha], lr=learning_rate)
defselect_action(self, state, evaluate=False):
state=torch.FloatTensor(state).to(self.device).unsqueeze(0)
ifevaluate:
withtorch.no_grad():
mean, _=self.actor(state)
action=torch.tanh(mean)
returnaction.cpu().numpy().flatten()
else:
withtorch.no_grad():
action, _=self.actor.sample(state)
returnaction.cpu().numpy().flatten()
defupdate(self, replay_buffer, batch_size=256, gamma=0.99, tau=0.005):
## 从经验回放中采样训练数据
batch=replay_buffer.sample_batch(batch_size)
state=torch.FloatTensor(batch['state']).to(self.device)
action=torch.FloatTensor(batch['action']).to(self.device)
reward=torch.FloatTensor(batch['reward']).to(self.device)
next_state=torch.FloatTensor(batch['next_state']).to(self.device)
done=torch.FloatTensor(batch['done']).to(self.device)
## 评论家网络更新
withtorch.no_grad():
next_action, next_log_prob=self.actor.sample(next_state)
q1_next, q2_next=self.critic_target(next_state, next_action)
q_next=torch.min(q1_next, q2_next) -torch.exp(self.log_alpha) *next_log_prob
target_q=reward+ (1-done) *gamma*q_next
q1_current, q2_current=self.critic(state, action)
critic_loss=F.mse_loss(q1_current, target_q) +F.mse_loss(q2_current, target_q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
## 演员网络更新
action_new, log_prob=self.actor.sample(state)
q1_new, q2_new=self.critic(state, action_new)
q_new=torch.min(q1_new, q2_new)
actor_loss= (torch.exp(self.log_alpha) *log_prob-q_new).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
## 温度参数更新
alpha_loss=-(self.log_alpha* (log_prob+self.target_entropy).detach()).mean()
self.alpha_optimizer.zero_grad()
alpha_loss.backward()
self.alpha_optimizer.step()
## 目标网络软更新
forparam, target_paraminzip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(tau*param.data+ (1-tau) *target_param.data)总结
本文系统地阐述了 SAC 算法的数学基础和实现细节。通过对演员网络和评论家网络的深入分析,我们可以看到 SAC 算法在以下几个方面具有显著优势:
理论框架
- 基于最大熵强化学习的理论基础保证了算法的收敛性
- 双 Q 网络设计有效降低了值函数估计的过度偏差
- 自适应温度参数实现了探索-利用的动态平衡
实现特点
- 采用重参数化技巧确保了策略梯度的连续性
- 软更新机制提升了训练稳定性
- 基于 PyTorch 的向量化实现提高了计算效率
实践价值
- 算法在连续动作空间中表现优异
- 样本效率高,适合实际应用场景
- 训练过程稳定,调参难度相对较小
未来研究可以在以下方向继续深化:
- 探索更高效的策略表达方式
- 研究多智能体场景下的 SAC 算法扩展
- 结合迁移学习提升算法的泛化能力
- 针对大规模状态空间优化网络架构
强化学习作为人工智能的核心研究方向之一,其理论体系和应用场景都在持续发展。深入理解算法的数学原理和实现细节,将有助于我们在这个快速演进的领域中把握技术本质,开发更有效的解决方案。
https://avoid.overfit.cn/post/295d79c7db084a839a5410e278279b4f

