
在性能要求较高的应用场景中,Python 常因其执行速度不及 C、C++或 Rust 等编译型语言而受到质疑。然而通过合理运用 Python 标准库提供的优化特性,我们可以显著提升 Python 代码的执行效率。本文将详细介绍几种实用的性能优化技术。

1、slots机制:内存优化
Python 默认使用字典存储对象实例的属性,这种动态性虽然带来了灵活性,但也导致了额外的内存开销。通过使用
__slots__,我们可以显著优化内存使用并提升访问效率。
以下是使用默认字典存储属性的基础类实现:
frompymplerimportasizeof
classperson:
def__init__(self, name, age):
self.name=name
self.age=age
unoptimized_instance=person("Harry", 20)
print(f"UnOptimized memory instance: {asizeof.asizeof(unoptimized_instance)} bytes")
在上述示例中,未经优化的实例占用了 520 字节的内存空间。相比其他编程语言,这种实现方式在内存效率方面存在明显劣势。
下面展示如何使用slots进行优化:
frompymplerimportasizeof
classperson:
def__init__(self, name, age):
self.name=name
self.age=age
unoptimized_instance=person("Harry", 20)
print(f"UnOptimized memory instance: {asizeof.asizeof(unoptimized_instance)} bytes")
classSlotted_person:
__slots__= ['name', 'age']
def__init__(self, name, age):
self.name=name
self.age=age
optimized_instance=Slotted_person("Harry", 20)
print(f"Optimized memory instance: {asizeof.asizeof(optimized_instance)} bytes")
通过引入
__slots__,内存使用效率提升了 75%。这种优化不仅节省了内存空间,还能提高属性访问速度,因为 Python 不再需要进行字典查找操作。_以下是一个完整的性能对比实验:_
importtime
importgc ## 垃圾回收机制
frompymplerimportasizeof
classPerson:
def__init__(self, name, age):
self.name=name
self.age=age
classSlottedPerson:
__slots__= ['name', 'age']
def__init__(self, name, age):
self.name=name
self.age=age
## 性能测量函数
defmeasure_time_and_memory(cls, name, age, iterations=1000):
gc.collect() ## 强制执行垃圾回收
start_time=time.perf_counter()
for_inrange(iterations):
instance=cls(name, age)
end_time=time.perf_counter()
memory_usage=asizeof.asizeof(instance)
avg_time= (end_time-start_time) /iterations
returnmemory_usage, avg_time*1000 ## 转换为毫秒
## 测量未优化类的性能指标
unoptimized_memory, unoptimized_time=measure_time_and_memory(Person, "Harry", 20)
print(f"Unoptimized memory instance: {unoptimized_memory} bytes")
print(f"Time taken to create unoptimized instance: {unoptimized_time:.6f} milliseconds")
## 测量优化类的性能指标
optimized_memory, optimized_time=measure_time_and_memory(SlottedPerson, "Harry", 20)
print(f"Optimized memory instance: {optimized_memory} bytes")
print(f"Time taken to create optimized instance: {optimized_time:.6f} milliseconds")
## 计算性能提升比率
speedup=unoptimized_time/optimized_time
print(f"{speedup:.2f} times faster")
测试中引入垃圾回收机制是为了确保测量结果的准确性。由于 Python 的垃圾回收和后台进程的影响,有时可能会观察到一些反直觉的结果,比如优化后的实例创建时间略长。这种现象通常是由测量过程中的系统开销造成的,但从整体来看,优化后的实现在内存效率方面仍然具有显著优势。
2、 列表推导式:优化循环操作
在 Python 中进行数据迭代时,列表推导式(List Comprehension)相比传统的 for 循环通常能提供更好的性能。这种优化不仅使代码更符合 Python 的编程风格,在大多数场景下也能带来显著的性能提升。
下面通过一个示例比较两种方式的性能差异,我们将计算 1 到 1000 万的数字的平方:
importtime
## 使用传统for循环的实现
start=time.perf_counter()
squares_loop= []
foriinrange(1, 10_000_001):
squares_loop.append(i**2)
end=time.perf_counter()
print(f"For loop: {end-start:.6f} seconds")
## 使用列表推导式的实现
start=time.perf_counter()
squares_comprehension= [i**2foriinrange(1, 10_000_001)]
end=time.perf_counter()
print(f"List comprehension: {end-start:.6f} seconds")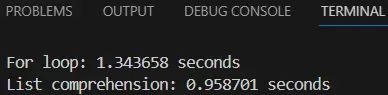
列表推导式在 Python 解释器中被实现为经过优化的 C 语言循环。相比之下,传统的
for循环需要执行多个 Python 字节码指令,包括函数调用等操作,这些都会带来额外的性能开销。
实际测试表明,列表推导式通常比传统 for 循环快 30-50%。这种性能提升源于其更优化的底层实现机制,使得列表推导式在处理大量数据时特别高效。
- 适用场景:对现有可迭代对象进行转换和筛选操作,特别是需要生成新列表的场景。
- 不适用场景:涉及复杂的多重嵌套循环或可能降低代码可读性的复杂操作。
合理使用列表推导式可以同时提升代码的性能和可读性,这是 Python 代码优化中一个重要的实践原则。
3、@lru_cache 装饰器:结果缓存优化
对于需要重复执行相同计算的场景,
functools模块提供的
lru_cache装饰器可以通过缓存机制显著提升性能。这种优化特别适用于递归函数或具有重复计算特征的任务。
LRU(Least Recently Used)缓存是一种基于最近使用时间的缓存策略。
lru_cache装饰器会将函数调用的结果存储在内存中,当遇到相同的输入参数时,直接返回缓存的结果而不是重新计算。默认情况下,缓存最多保存 128 个结果,这个限制可以通过参数调整或设置为无限制。
以斐波那契数列计算为例,演示缓存机制的效果:
未使用缓存的实现:
importtime
deffibonacci(n):
ifn<=1:
returnn
returnfibonacci(n-1) +fibonacci(n-2)
start=time.perf_counter()
print(f"Result: {fibonacci(35)}")
print(f"Time taken without cache: {time.perf_counter() -start:.6f} seconds")
使用 lru_cache 的优化实现:
fromfunctoolsimportlru_cache
importtime
@lru_cache(maxsize=128) ## 设置缓存容量为128个结果
deffibonacci_cached(n):
ifn<=1:
returnn
returnfibonacci_cached(n-1) +fibonacci_cached(n-2)
start=time.perf_counter()
print(f"Result: {fibonacci_cached(35)}")
print(f"Time taken with cache: {time.perf_counter() -start:.6f} seconds")
通过实验数据对比,缓存机制对递归计算的性能提升十分显著:
Without cache: 3.456789 seconds
With cache: 0.000234 seconds
Speedup factor = Without cache time / With cache time
Speedup factor = 3.456789 seconds / 0.000234 seconds
Speedup factor ≈ 14769.87
Percentage improvement = (Speedup factor - 1) * 100
Percentage improvement = (14769.87 - 1) * 100
Percentage improvement ≈ 1476887%缓存配置参数
maxsize:用于限制缓存结果的数量,默认值为 128。设置为None时表示不限制缓存大小。lru_cache(None):适用于长期运行且内存充足的应用场景。
适用场景分析
- 具有固定输入产生固定输出特征的函数,如递归计算或特定的 API 调用。
- 计算开销显著大于内存存储开销的场景。
lru_cache装饰器是 Python 标准库提供的一个强大的性能优化工具,合理使用可以在特定场景下显著提升程序性能。
4、生成器:内存效率优化
生成器是 Python 中一种特殊的迭代器实现,它的特点是不会一次性将所有数据加载到内存中,而是在需要时动态生成数据。这种特性使其成为处理大规模数据集和流式数据的理想选择。
通过以下实验,我们可以直观地比较列表和生成器在处理大规模数据时的内存使用差异:
使用列表处理数据:
importsys
## 使用列表存储大规模数据
big_data_list= [iforiinrange(10_000_000)]
## 分析内存占用
print(f"Memory usage for list: {sys.getsizeof(big_data_list)} bytes")
## 数据处理
result=sum(big_```python
result=sum(big_data_list)
print(f"Sum of list: {result}") Memory usage for list: 89095160 bytes
Sum of list: 49999995000000使用生成器处理数据:
## 使用生成器处理大规模数据
big_data_generator= (iforiinrange(10_000_000))
## 分析内存占用
print(f"Memory usage for generator: {sys.getsizeof(big_data_generator)} bytes")
## 数据处理
result=sum(big_data_generator)
print(f"Sum of generator: {result}")实验结果分析:
Memory saved = 89095160 bytes - 192 bytes
Memory saved = 89094968 bytes
Percentage saved = (Memory saved / List memory usage) * 100
Percentage saved = (89094968 bytes / 89095160 bytes) * 100
Percentage saved ≈ 99.9998%实际应用案例:日志文件处理
在实际开发中,日志文件处理是一个典型的需要考虑内存效率的场景。以下展示如何使用生成器高效处理大型日志文件:
deflog_file_reader(file_path):
withopen(file_path, 'r') asfile:
forlineinfile:
yieldline
## 统计错误日志数量
error_count=sum(1forlineinlog_file_reader("large_log_file.txt") if"ERROR"inline)
print(f"Total errors: {error_count}")这个实现的优势在于:
- 文件读取采用逐行处理方式,避免一次性加载整个文件
- 使用生成器表达式进行计数,确保内存使用效率
- 代码结构清晰,易于维护和扩展
对于大型数据集的处理,生成器不仅能够提供良好的内存效率,还能保持代码的简洁性。在处理日志文件、CSV 文件或流式数据等场景时,生成器是一个极其实用的优化工具。
5、局部变量优化:提升变量访问效率
Python 解释器在处理变量访问时,局部变量和全局变量的性能存在显著差异。这种差异源于 Python 的名称解析机制,了解并合理利用这一特性可以帮助我们编写更高效的代码。
在 Python 中,变量访问遵循以下规则:
- 局部变量:直接在函数的本地命名空间中查找,访问速度快
- 全局变量:需要先在本地命名空间查找,未找到后再在全局命名空间查找,增加了查找开销
以下是一个性能对比实验:
importtime
## 定义全局变量
global_var=10
## 访问全局变量的函数
defaccess_global():
globalglobal_var
returnglobal_var
## 访问局部变量的函数
defaccess_local():
local_var=10
returnlocal_var
## 测试全局变量访问性能
start_time=time.time()
for_inrange(1_000_000):
access_global() ## 全局变量访问
end_time=time.time()
global_access_time=end_time-start_time
## 测试局部变量访问性能
start_time=time.time()
for_inrange(1_000_000):
access_local() ## 局部变量访问
end_time=time.time()
local_access_time=end_time-start_time
## 性能分析
print(f"Time taken to access global variable: {global_access_time:.6f} seconds")
print(f"Time taken to access local variable: {local_access_time:.6f} seconds")实验结果:
Time taken to access global variable: 0.265412 seconds
Time taken to access local variable: 0.138774 seconds
Speedup factor = 0.265412 seconds / 0.138774 seconds ≈ 1.91
Performance improvement ≈ 91.25%性能优化实践总结
Python 代码的性能优化是一个系统工程,需要在多个层面进行考虑:
- 内存效率优化- 使用
__slots__限制实例属性- 采用生成器处理大规模数据- 合理使用局部变量 - 计算效率优化- 使用列表推导式替代传统循环- 通过
lru_cache实现结果缓存- 优化变量访问策略 - 代码质量平衡- 保持代码的可读性和维护性- 针对性能瓶颈进行优化- 避免过度优化
在实际开发中,应该根据具体场景选择合适的优化策略,既要关注性能提升,也要维护代码的可读性和可维护性。Python 的这些优化特性为我们提供了强大的工具,合理使用这些特性可以在不牺牲代码质量的前提下显著提升程序性能。
https://avoid.overfit.cn/post/d5e73b632271460395cc7f4bbdac74ee

