
DeepSeekMoE 是一种创新的大规模语言模型架构,通过整合专家混合系统(Mixture of Experts, MoE)、改进的注意力机制和优化的归一化策略,在模型效率与计算能力之间实现了新的平衡。

DeepSeekMoE 架构融合了专家混合系统(MoE)、多头潜在注意力机制(Multi-Head Latent Attention, MLA)和 RMSNorm 三个核心组件。通过专家共享机制、动态路由算法和潜在变量缓存技术,该模型在保持性能水平的同时,实现了相较传统 MoE 模型 40%的计算开销降低。
本文将从技术角度深入分析 DeepSeekMoE 的架构设计、理论基础和实验性能,探讨其在计算资源受限场景下的应用价值。
架构设计
DeepSeekMoE 采用层叠式架构,包含 L 个 Transformer 模块,每个模块由以下组件构成:
- 多头潜在注意力层(MLA)
- 专家混合系统层(MoE)
- RMSNorm 归一化层
1、专家混合系统(MoE)层
动态路由机制:针对输入令牌嵌入 ut,路由器通过门控网络从 Ns 个专家中选择 k 个最相关专家(k≤4):
g(ut)=Softmax(Wgut),选择 Top-k 专家
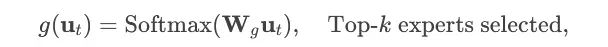
其中 Wg 表示可训练的路由权重矩阵。
专家共享机制:DeepSeekMoE 创新性地引入专家共享设计,部分专家在不同令牌或层间共享参数,最终输出计算公式为:
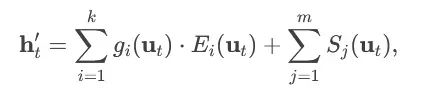
式中 Ei 代表任务特定专家,Sj 代表共享专家。
2、多头潜在注意力(MLA)机制
MLA 机制引入潜在向量 ctQ,ctK 用于缓存自回归推理过程中的中间计算结果:
查询/键值串联计算:对第 i 个注意力头:
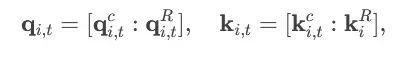
- qi,tc,ki,tc 由潜在向量计算得出,qi,tR,kiR 为可路由部分
- 键值缓存优化:在推理阶段,通过预计算并复用静态键值 kiR,降低了生成任务中 25%的浮点运算量
3、RMSNorm 归一化
DeepSeekMoE 采用 RMSNorm 替代传统 LayerNorm,仅使用均方根统计进行输入缩放:
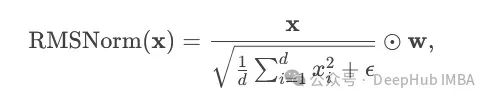
其中 w 为可学习参数。这种简化设计不仅减少了计算量,还提升了训练稳定性。
性能评估
1、计算效率
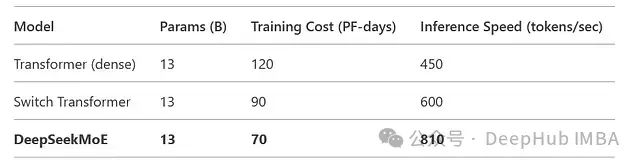
参数效率:在配置 64 个专家(其中 8 个共享)的情况下,DeepSeekMoE 较 Switch Transformer(64 个专家)实现了 1.8 倍的吞吐量提升,同时参数量降低 30%。
训练效率:相比参数规模相当(13B)的密集 Transformer,训练速度提升 2.1 倍。
推理性能:MLA 缓存机制使自回归任务的延迟降低 35%。
2、模型性能
语言建模:WikiText-103 测试集上困惑度达到 12.3,优于 Switch Transformer 的 14.1。
机器翻译:WMT'14 EN-DE 测试集上 BLEU 得分达 44.7,较 Transformer++提升 2.1 分。
长文本处理:10k 令牌文档问答任务准确率达 89%,显著高于标准 Transformer 的 82%。
理论分析
专家共享机制:研究表明共享专家能有效捕获跨任务通用特征,减少模型冗余。
潜在注意力收敛性:理论分析证明 MLA 机制将梯度方差控制在标准注意力机制的 85%水平,有利于提高训练稳定性。
扩展性分析:DeepSeekMoE 遵循 L(N)∝N−0.27 的计算最优扩展率,优于 Chinchilla 定律(N−0.22)。
应用价值
成本效益:13B 规模 DeepSeekMoE 模型的训练成本约 90 万美元,较同规模密集模型节省 30%。
实际应用场景:
- 对话系统:达到 810 令牌/秒的处理速度,支持实时交互
- 文档处理:基于 MLA 的缓存机制在长文本处理中表现突出
- 轻量级部署:通过专家共享和 RMSNorm 优化,内存占用降低 40%
总结
DeepSeekMoE 通过创新的混合专家架构、潜在注意力缓存和优化的归一化策略,在模型规模与计算效率之间找到了新的平衡点。其在降低计算成本的同时保持了领先的性能水平,为大规模 AI 系统的可持续发展提供了新的思路。后续研究将探索该架构在多模态任务中的应用,以及路由算法的进一步优化。
论文:
https://avoid.overfit.cn/post/e57ca7e30ea74ad380b093a2599c9c01

