
在深度学习的背景下,NVIDIA 的 CUDA 与 AMD 的 ROCm 框架缺乏有效的互操作性,导致基础设施资源利用率显著降低。随着模型规模不断扩大而预算约束日益严格,2-3 年更换一次 GPU 的传统方式已不具可持续性。但是 Pytorch 的最近几次的更新可以有效利用异构计算集群,实现对所有可用 GPU 资源的充分调度,不受制于供应商限制。

本文将深入探讨如何混合 AMD/NVIDIA GPU 集群以支持 PyTorch 分布式训练。通过建立 CUDA 与 ROCm 的技术桥接,我们将阐述如何实现以下目标:
- 无需重构训练代码即可充分利用异构硬件资源
- 维持高性能集体通信操作—如
all_reduce和all_gather—通过 UCC 和 UCX 技术框架高效聚合和传输 AMD 与 NVIDIA GPU 节点间的数据(如梯度),实现同步化训练 - 在采用 AWS g4dn (NVIDIA T4)和 g4ad (AMD Radeon V520)实例构建的异构本地及 Kubernetes 集群上部署分布式 PyTorch 训练任务
集群异构性分析
集群异构性呈现从轻度到强度的连续谱系,每个层级在分布式机器学习和高性能计算环境中均需采取差异化的管理策略。这些集群主要依赖 GPU 作为核心计算加速器,同时可能在 CPU 架构、内存配置、存储系统及网络互连技术方面存在差异。本章重点分析 GPU 异构性对 HPC 集群的影响,包括单一供应商生态系统内的轻度差异及多供应商环境下的显著差异。
轻度异构环境
轻度异构环境主要涉及同一供应商生态系统内的技术差异,如 NVIDIA V100 与 A100 或 AMD MI50 与 MI250X 加速器之间的代际差异。在此类场景中,这些 GPU 共享基础架构、驱动程序和通信库,使 PyTorch 等框架能够通过抽象层有效管理这些差异。
轻度异构集群面临的挑战:
- 计算能力不平衡: 老旧 GPU 架构在处理新型模型时性能滞后,形成系统瓶颈。
- 内存容量不匹配: VRAM 容量较小的设备限制了可处理的批量大小。
- 互连性能变化: PCIe Gen3 与 NVLink/NVSwitch 技术在数据传输速率上存在显著差异。
解决方案:
- 参数服务器分布式策略 实现更具容错性的分布式工作负载架构
- 动态负载均衡: 实施智能工作负载分配机制,跟踪设备利用率,将较小批次任务分配至性能较低的 GPU。
- 梯度压缩技术: 减少带宽受限节点的通信开销。
- 容器化部署: 使用针对特定 GPU 架构优化的 CUDA/ROCm 版本构建 Docker 镜像,提高兼容性。
由于 NVIDIA 的 NCCL 或 AMD 的 RCCL 等供应商专用库针对各自生态系统进行了深度优化,因此集体通信在轻度异构环境中仍能保持较高效率。
强度异构环境
强度异构环境涉及来自不同供应商的 GPU 设备组成的混合集群(如 NVIDIA 与 AMD)。
NVIDIA CUDA 与 AMD ROCm 分别为其专有硬件平台设计,采用不同的指令集、内存管理机制和驱动程序接口。这种缺乏统一基础架构的情况导致依赖共享通信后端的负载均衡策略和基于统一内存语义的全分片数据并行(FSDP)技术无法跨平台运行。
目前业界尚未形成标准化解决方案来应对强度异构环境带来的挑战。这一技术缺口需要开发策略,在最小化 AMD 与 NVIDIA GPU 间通信开销的同时,实现混合供应商集群的透明利用,并达到接近原生性能水平。这一目标可定义为:
- 透明资源利用: 执行分布式训练任务无需重写模型代码或按供应商分割集群。
- 接近原生的性能表现: 最小化 AMD 与 NVIDIA GPU 间的通信开销,接近 NCCL/RCCL 原生性能,并利用支持 RDMA 的集体通信和 GPU P2P 通信实现高效分布式计算。
在后续内容中,我将详细阐述为在 AWS G4dn 实例(配备 NVIDIA T4 GPU)和 AWS G4ad 实例(配备 AMD Radeon V520 GPU)上启用 PyTorch 分布式训练的集体通信所进行的技术探索。重点将置于利用现有集体通信库来解决强度异构环境带来的挑战。
NCCL 与 RCCL 的兼容性探索
NCCL (NVIDIA) 和 RCCL (AMD) 是经过 GPU 优化的 集体通信库,集成了直接利用 GPU Direct RDMA 以及必要时使用套接字传输的底层优化机制。
在研究 RCCL 变更日志时,我发现的首个积极信号是—与NCCL <version>的兼容性注释。无论采用何种版本配置或应用何种优化调整,系统始终返回:
NCCL WARN NET/Socket: message truncated: receiving X bytes instead of Y.这一探索最终证实为技术瓶颈,因为尽管 RCCL 是 NCCL 的移植版本,但底层架构差异阻碍了 RCCL 与 NCCL 在异构集群中的协同工作。这些库依赖特定硬件集成,且基于不同的内核级优化、内存层次结构和 IPC 机制,使真正的兼容性实现变得极为困难。
解决这一问题需要高效的通信中间件技术。
统一通信框架技术
在寻找适当解决方案的过程中,我发现了统一通信框架(UCF)—一个由工业界、研究机构和学术界组成的联盟,其使命是统一高性能计算通信标准。
具有前景的解决方案—统一集体通信(UCC)—是一个开源项目,为高性能计算、人工智能、数据中心和 I/O 领域提供集体通信操作的 API 和库实现。该项目旨在通过网络拓扑感知算法、简化软件方法和网络内计算硬件加速,提供高效且可扩展的集体通信操作。
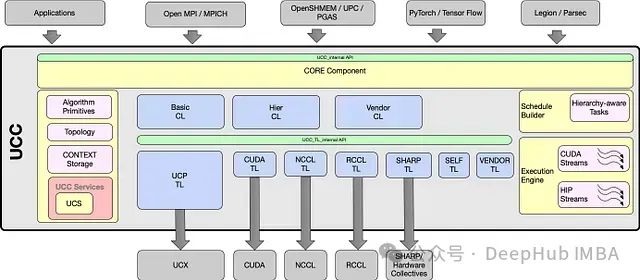
UCC 与传输层中间件—统一通信 X(UCX)协同工作,利用其高性能点对点通信原语和功能组件。UCX 的设计汲取了多个项目的经验,包括 Mellanox 的 HCOLL 和 SHARP、华为的 UCG、开源 Cheetah 及 IBM 的 PAMI Collectives。最为关键的是—UCC 和 UCX 均实现了对 ROCm 和 CUDA 的全面支持。
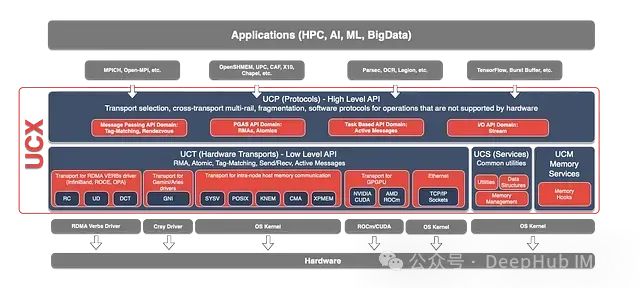
UCC 作为实验性后端已集成到 PyTorch 分布式模块中。它可以作为 PyTorch 分布式模块的直接后端使用,也可以作为 OpenMPI 中集体通信操作的后端。为此需要从源代码构建支持 MPI 的torch库,并使用mpirun启动器执行支持 OpenMPI 的分布式任务。
这一发现是技术突破的关键是成功确定可行配置,并使用 PyTorch 和 MPI 成功运行了多节点分布式数据并行训练任务。
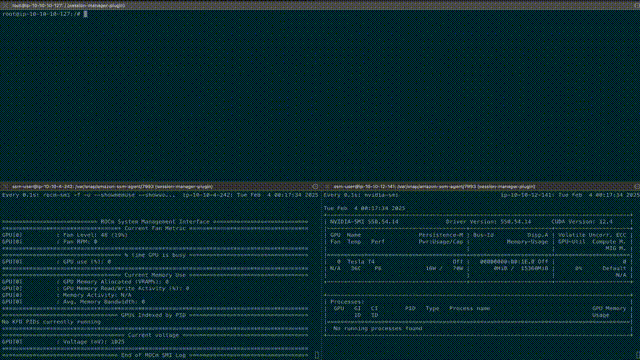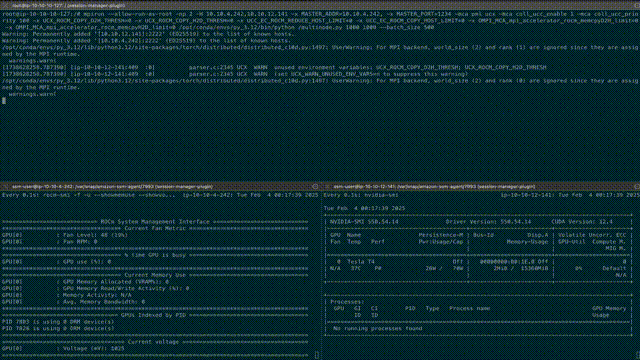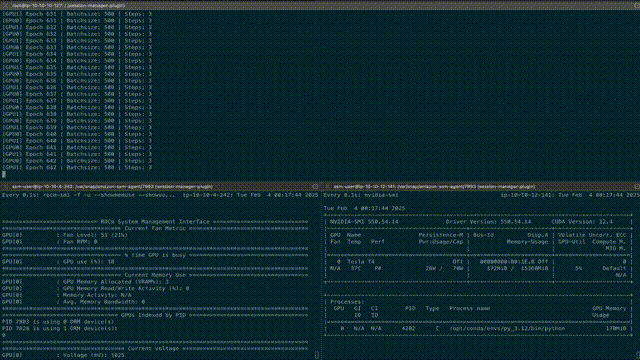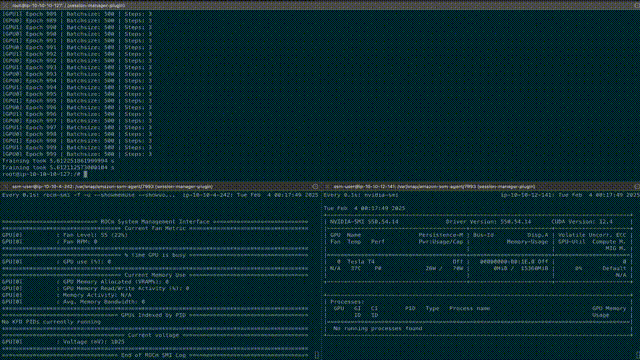
AWS G4ad (AMD GPU)和 G4dn (NVIDIA GPU)实例上运行的分布式数据并行 PyTorch 训练任务。
通过采用 UCC 和 UCX 技术框架,异构 GPU 集群不再是遥不可及的理想,而是可实现的技术目标。这一突破有望使组织能够充分发挥硬件投资价值,将分散的计算资源整合为高效统一的高性能计算环境。
异构 Kubernetes 集群实现
在企业级基础设施管理中,组织面临着如何高效配置资源支持团队需求的挑战。同时还需要支持各种规模的机器学习工作负载的快速高效运行,包括小型实验和长期训练万亿参数级大模型的场景。
Kubernetes 因其强大的资源编排能力以及最大化资源利用率和协调多样化硬件的能力,已成为分布式机器学习的基础平台。
要在 Kubernetes 上调度分布式训练任务,无论使用 Kubeflow MPI Operator 还是 PyTorch operator,任务清单都需要使用 AMD 或 NVIDIA 设备插件提供的特定资源定义:
## NVIDIA
resources:
limits:
nvidia.com/gpu: 1
## AMD
resources:
limits:
amd.com/gpu: 1配置强度异构任务需要自定义资源定义(CRD)或变更准入控制器(mutating webhook handler),以统一资源命名(如heterogenous.com/gpu: 1),或者手动单独部署每个 Pod。
VolcanoJob作为 Volcano 调度器提供的 Kubernetes CRD,简化了这一流程。Volcano 专为高性能批处理工作负载设计,提供组调度(gang scheduling)功能确保分布式任务的原子执行(即所有必需资源可用时所有 Pod 同时启动,否则全部不启动),并提供插件自动化基础设施配置。与 Kubeflow 的 Training Operators(如 MPIOperator)强制所有 worker 使用统一资源模板不同,Volcano 允许按任务定义 Pod,从而实现对异构资源的精确控制。
在异构 Kubernetes 集群上部署混合 GPU 分布式训练工作负载,需配置以下VolcanoJob CRD功能:
自动 SSH 配置
ssh插件生成包含预共享 SSH 密钥的 ConfigMap,实现 Pod 间无密码认证。每个容器中的sshd设置利用这些密钥,无需手动证书管理。
worker pod DNS 解析
svc插件创建无头服务(headless service),分配可预测的 DNS 主机名。Pod 通过 Volcano 注入的环境变量(如VC_MPIWORKER_AMD_HOSTS)识别对等节点,主 Pod 利用这些变量构建mpirun主机列表。
资源特定任务组
每个task定义唯一 Pod 模板:
—mpimaster协调训练过程,使用 MPI 和 UCX 参数优化 GPU 通信。
—mpiworker-nvidia和mpiworker-amd分别指定不同resources和供应商特定容器镜像。
组调度机制
minAvailable: 3确保所有 Pod(1 个 master + 2 个 worker)同时调度,防止异构集群中的资源死锁。
任务完成定义
带有CompleteJob动作键的policies字段允许配置将任务标记为完成状态的事件。此处为mpimaster任务的TaskCompleted事件。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: mpi-training-heterogeneous
namespace: volcano-job-training
spec:
minAvailable: 3 ## Gang scheduling: All 3 pods must be allocated
plugins:
ssh: [] ## Auto-generates SSH keys via ConfigMap
svc: [] ## Creates headless service for stable hostnames
schedulerName: volcano
tasks:
- name: mpimaster
policies:
- action: CompleteJob ## The job is completed when the launcher task completes successfully
event: TaskCompleted
replicas: 1
template:
spec:
containers:
- command:
- /bin/bash
- -c
## Create SSH directories for the plugin to inject passwordless configuration
- mkdir -p /var/run/sshd; /usr/sbin/sshd;
## Volcano injects worker hosts via VC_MPIWORKER_*_HOSTS:
MPI_HOST=${VC_MPIWORKER_AMD_HOSTS},${VC_MPIWORKER_NVIDIA_HOSTS};
NUM_WORKERS=$(($(echo ${MPI_HOST} | tr -cd ',' | wc -c) + 1));
## Launch the training job with mpirun and push the extracted MPI_HOST and NUM_WORKERS content
- mpirun -np ${NUM_WORKERS} --allow-run-as-root --host ${MPI_HOST} -x MASTER_ADDR=${VC_MPIWORKER_AMD_HOSTS} -x MASTER_PORT=29603 \
## Configure OpenMPI to use UCC for collective operation backend
-mca pml ucx -mca coll_ucc_enable 1 -mca coll_ucc_priority 100 \
## Fine-tune UCX transport layer and UCC collectives parameters to support g4ad instances
-x UCX_ROCM_COPY_D2H_THRESH=0 -x UCX_ROCM_COPY_H2D_THRESH=0 \
-x UCC_EC_ROCM_REDUCE_HOST_LIMIT=0 -x UCC_EC_ROCM_COPY_HOST_LIMIT=0 \
-x OMPI_MCA_mpi_accelerator_rocm_memcpyD2H_limit=0 -x OMPI_MCA_mpi_accelerator_rocm_memcpyH2D_limit=0 \
## Point on the MPI-aware PyTorch job execution code
/opt/conda/envs/py_3.12/bin/python 1000 1000 --batch_size 500
/mpijob/main.py --backend=mpi 1000 1000 --batch_size 500
image: docker.io/rafalsiwek/opmpi_ucx_simple:latest
name: mpimaster
ports:
- containerPort: 22
name: mpijob-port
restartPolicy: OnFailure
- name: mpiworker-nvidia
replicas: 1
template:
spec:
containers:
- command:
- /bin/bash
- -c
- mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: docker.io/rafalsiwek/g4dn_distributed_ml:1.0_pytorch_mpi_opperator
name: mpiworker
ports:
- containerPort: 22
name: mpijob-port
- containerPort: 29603
name: torch-port
resources:
limits:
nvidia.com/gpu: "1" ## NVIDIA-specific GPU
restartPolicy: OnFailure
- name: mpiworker-amd
replicas: 1
template:
spec:
containers:
- command:
- /bin/bash
- -c
- mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
image: docker.io/rafalsiwek/g4ad_distributed_ml:1.0_pytorch_mpi_opperator
name: mpiworker
ports:
- containerPort: 22
name: mpijob-port
- containerPort: 29603
name: torch-port
resources:
limits:
amd.com/gpu: "1" ## AMD-specific GPU运行 PyTorch 分布式任务需要具备特定 GPU 类型感知的 UCC、UCX 和 MPI 库环境,以及将分布式模块链接到这些库的 PyTorch 构建。启动器仅需 UCC、UCX 和 OpenMPI 支持,由于其集体操作不涉及 GPU 特定处理,因此不需要 GPU 感知构建。此环境配置需要从源代码构建相关库和 PyTorch。
通过在 Kubernetes 平台上启用混合 GPU 集群,组织能够将分散的硬件资源转化为统一的创新平台。这种方法有效消除了成本高昂的供应商锁定,最大化现有投资价值并提升 GPU 资源利用率。 无论是扩展万亿参数模型训练还是整合具有不同基础设施的团队,异构环境使团队能够以更高效、智能的方式进行模型训练,无需彻底更换硬件平台。
技术局限性
缺乏 RDMA 验证:由于 AWS EFA 对 g4ad 实例的支持状态尚不明确,适当的 RDMA 兼容性尚未得到完全测试。UCX 同样缺乏针对零拷贝 RDMA 操作的官方 AWS EFA 兼容性认证,因此当前实现主要依赖 TCP 传输。
次优通信性能:仅使用 TCP 传输层会显著降低通信带宽和增加延迟,这一点已通过OSU 基准测试结果得到验证。
机器学习框架集成要求:尽管 PyTorch 和 Horovod 支持用于集体操作的 MPI 后端,但 Horovod 在本实现中尚未进行全面测试。此外,大多数框架需要显式的 MPI 后端集成,而这种集成并非在所有框架中普遍可用。
PyTorch 中有限的 MPI 后端支持:PyTorch 的 MPI 风格集体后端功能集相对有限,优先支持 NCCL/Gloo 后端,且仅完全支持分布式数据并行(DDP)模式。全分片数据并行(FSDP)等高级策略依赖于allgather_base等操作,这些操作在 PyTorch 的 MPI 后端中尚未实现。
总结
对于寻求在机器学习和深度学习工作负载中实现快速扩展的组织而言,在多供应商 GPU 集群上执行分布式训练的能力提供了极具战略价值的技术机遇。由于主流机器学习框架缺乏原生支持,目前实现这一目标仍需投入大量工程资源。
开放、标准化实现的发展将有助于实现异构硬件生态系统的民主化访问,从而在不牺牲性能的前提下提供经济高效的技术灵活性。
本文的源代码可以在这个项目中找到:
https://avoid.overfit.cn/post/41b87700f05642b0b0cbd4729274ed1a

