
在人体姿态估计领域,传统方法通常将关键点作为基本处理单元,这些关键点在人体骨架结构上代表关节位置(如肘部、膝盖和头部)的空间坐标。现有模型对这些关键点的预测主要采用两种范式:直接通过坐标回归或间接通过热图(heat map,即图像空间中的密集概率分布)进行估计。尽管这些方法在实际应用中取得了显著效果,但它们往往将每个关键点作为独立单元处理,未能充分利用人体骨架结构中固有的关键点间组合关系。
如果我们转换思路,将姿态表示为一组学习到的、离散的标记(token)组合,这些标记不仅仅编码原始坐标或热图信息,而是捕获关键点之间的共享模式、对称性和结构化关系,会带来怎样的优势?
受 2023 年发表的研究论文《Human Pose As Compositional Tokens》启发,本文构建了一个姿态重建模型,实现了上述概念。我们将详细介绍该方法第一阶段的实现过程:训练组合编码器(Compositional Encoder)、向量量化(Vector Quantization, VQ)码本和姿态解码器(Pose Decoder)——这些组件共同构成了一个用于学习姿态结构紧凑、离散表示的系统。
与传统的热图或坐标回归方法相比,基于标记的表征方法能够有效捕获关键点之间的语义和空间依赖关系。这种表征形式使模型能够更好地泛化到未见过的姿态配置,并且便于将这些离散标记整合到下游任务中,如动作识别或姿态分类。
合成火柴人数据集
为简化实验过程并专注于方法本身,我们创建了一个火柴人的合成数据集。每个火柴人实例由 13 个二维关键点精确定义,这些关键点包括头部、颈部、肩膀、肘部、手部、腰部、膝盖和脚部。该数据集采用即时生成方式,支持随机但符合人体结构约束的肢体配置、微小的姿态变化以及基于旋转的数据增强。

图 1:火柴人示例,其中标注了关键点位置
基于组合编码的 VQ-VAE
本文的核心目标是将每个姿态压缩为一组离散的标记(token),每个标记对应于从共享码本中学习的潜在表示。
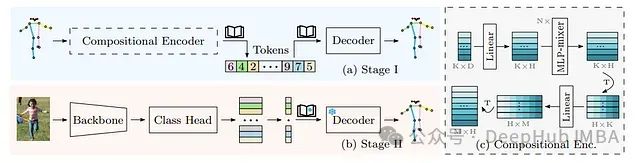
图 2:PCT(Pose as Compositional Tokens)架构的训练阶段 - 来源:https://arxiv.org/abs/2303.11638
辅助模块
class MLPBlock(nn.Module):
def __init__(self, dim, inter_dim, dropout_ratio):
super().__init__()
self.ff = nn.Sequential(
nn.Linear(dim, inter_dim),
nn.GELU(),
nn.Dropout(dropout_ratio),
nn.Linear(inter_dim, dim),
nn.Dropout(dropout_ratio)
)
def forward(self, x):
return self.ff(x)
class MixerLayer(nn.Module):
def __init__(self,
hidden_dim,
hidden_inter_dim,
token_dim,
token_inter_dim,
dropout_ratio):
super().__init__()
self.layernorm1 = nn.LayerNorm(hidden_dim)
self.MLP_token = MLPBlock(token_dim, token_inter_dim, dropout_ratio)
self.layernorm2 = nn.LayerNorm(hidden_dim)
self.MLP_channel = MLPBlock(hidden_dim, hidden_inter_dim, dropout_ratio)
def forward(self, x):
y = self.layernorm1(x)
y = y.transpose(2, 1)
y = self.MLP_token(y)
y = y.transpose(2, 1)
z = self.layernorm2(x + y)
z = self.MLP_channel(z)
out = x + y + z
return outMLPMixer 层是《Human Pose as Compositional Tokens》论文作者提出的用于将关键点信息融合成潜在向量的核心组件。
组合编码器
class CompositionalEncoder(nn.Module):
def __init__(self, numberOfKeypoints=11, dimensionOfKeypoints=2, linearProjectionSize=128, numberOfMixerBlocks=4, codebookTokenDimension=64, internalMixerSize=64, internalMixerTokenSize=32, mixerDropout=0.1):
super(CompositionalEncoder, self).__init__()
self.numberOfKeypoints = numberOfKeypoints # K
self.dimensionOfKeypoints = dimensionOfKeypoints # D
self.linearProjectionSize = linearProjectionSize # H
self.numberOfMixerBlocks = numberOfMixerBlocks # N
self.codebookTokenDimension = codebookTokenDimension # M
self.internalMixerSize = internalMixerSize
self.internalMixerTokenSize = internalMixerTokenSize
self.mixerDropout = mixerDropout
self.initial_linear = nn.Linear(self.dimensionOfKeypoints,
self.linearProjectionSize) # 从BxKxD投影到BxKxH
self.mixer_layers = nn.ModuleList([MixerLayer(self.linearProjectionSize,
self.internalMixerSize,
self.numberOfKeypoints,
self.internalMixerTokenSize,
self.mixerDropout) for _ in range(self.numberOfMixerBlocks)]) # BxKxH
self.mixer_layer_norm = nn.LayerNorm(self.linearProjectionSize) # BxKxH
self.token_linear = nn.Linear(self.numberOfKeypoints,
self.codebookTokenDimension) # BxHxK -> BxHxM
self.feature_embed = nn.Linear(self.linearProjectionSize,
self.codebookTokenDimension)
def forward(self, x):
# 之前: BxDxK
x = x.transpose(2,1)
# 之后: BxKxD
# 之前: BxKxD
x = self.initial_linear(x)
# 之后: BxKxH
# 之前: BxKxH
for mixer in self.mixer_layers:
x = mixer(x)
# 之后: BxKxH
# 之前: BxKxH
x = self.mixer_layer_norm(x)
# 之后: BxKxH
# 之前: BxKxH
x = x.transpose(2,1)
# 之后: BxHxK
# 之前: BxHxK
x = self.token_linear(x)
# 之后: BxHxM
# 之前: BxHxM
x = x.transpose(2,1)
# 之后: BxMxH
# 之前: BxMxH
x = self.feature_embed(x)
# 之后: BXMxM
return x编码器接收一组二维关键点坐标,通过基于 MLP-Mixer 架构设计的网络结构将这些坐标转换为 M 个潜在标记特征。具体而言,关键点首先被嵌入到高维空间,然后在关节和特征维度之间进行混合处理,最终投影到形状为
B × M × D(批量大小 × 标记数量 × 标记维度)的输出特征空间。
EMA 码本(VQ 层)
class CodebookVQ(nn.Module):
def __init__(self, codebookDimension, numberOfCodebookTokens, decay=0.99, epsilon=1e-5):
super(CodebookVQ, self).__init__()
self.codebookDimension = codebookDimension
self.numberOfCodebookTokens = numberOfCodebookTokens
self.decay = decay
self.epsilon = epsilon
self.register_buffer('codebook', torch.empty(numberOfCodebookTokens, codebookDimension))
self.codebook.data.normal_()
self.register_buffer('ema_cluster_size', torch.zeros(numberOfCodebookTokens))
self.register_buffer('ema_w', torch.empty(numberOfCodebookTokens, codebookDimension))
self.ema_w.data.normal_()
def forward(self, encode_feat):
M = encode_feat.shape[1]
B = encode_feat.shape[0]
encode_feat = encode_feat.view(-1, self.codebookDimension) # [B*M, M]
# 计算与码本条目的距离
distances = (
encode_feat.pow(2).sum(1, keepdim=True)
- 2 * encode_feat @ self.codebook.t()
+ self.codebook.pow(2).sum(1)
) # [B*M, num_tokens]
# 找到最近的码本索引
encoding_indices = torch.argmin(distances, dim=1) # [B*M]
encodings = F.one_hot(encoding_indices, self.numberOfCodebookTokens).type(encode_feat.dtype) # [B*M, num_tokens]
# 量化输出
quantized = encodings @ self.codebook # [B*M, M]
quantized = quantized.view_as(encode_feat) # 重塑回原始输入形状
if self.training:
# EMA更新
ema_counts = encodings.sum(0) # [num_tokens]
dw = encodings.t() @ encode_feat # [num_tokens, M]
self.ema_cluster_size.mul_(self.decay).add_(ema_counts, alpha=1 - self.decay)
self.ema_w.mul_(self.decay).add_(dw, alpha=1 - self.decay)
n = self.ema_cluster_size.sum()
cluster_size = (
(self.ema_cluster_size + self.epsilon)
/ (n + self.numberOfCodebookTokens * self.epsilon) * n
)
self.codebook.data = self.ema_w / cluster_size.unsqueeze(1)
quantized = quantized.view(B, M, M)
encoding_indices = encoding_indices.view(B, M)
return quantized, encoding_indices潜在标记通过向量量化层进行离散化处理,该层采用指数移动平均(EMA)方法更新码本。在这一过程中,每个连续的标记向量都被码本中最相近的离散代码向量替换,从而将姿态表示转化为一组符号化的离散表示。具体实现中:
- 码本包含
num_codes个代码向量条目 - 每个输入标记根据 L2 距离独立选择最相近的码本向量
- 码本在训练过程中通过 EMA 机制进行自我更新,确保码本适应训练数据分布
姿态解码器
class PoseDecoder(nn.Module):
def __init__(self, codebookTokenDimension=64, numberOfKeypoints=11, keypointDimension=2, hiddenDimensionSize=128, numberOfMixerBlocks=4, mixerInternalDimensionSize=64, mixerTokenInternalDimensionSize=128, mixerDropout=0.1):
super(PoseDecoder, self).__init__()
self.codebookTokenDimension = codebookTokenDimension
self.numberOfKeypoints = numberOfKeypoints
self.keypointDimension = keypointDimension
self.hiddenDimensionSize = hiddenDimensionSize
self.mixerInternalDimensionSize = mixerInternalDimensionSize
self.mixerTokenInternalDimensionSize = mixerTokenInternalDimensionSize
self.mixerDropout = mixerDropout
self.numberOfMixerBlocks = numberOfMixerBlocks
self.linear_token = nn.Linear(self.codebookTokenDimension, self.numberOfKeypoints)
self.initial_linear = nn.Linear(self.codebookTokenDimension, self.hiddenDimensionSize)
self.mixer_layers = nn.ModuleList([MixerLayer(self.hiddenDimensionSize, self.mixerInternalDimensionSize, self.numberOfKeypoints, self.mixerTokenInternalDimensionSize, self.mixerDropout) for _ in range(self.numberOfMixerBlocks)])
self.decoder_layer_norm = nn.LayerNorm(self.hiddenDimensionSize)
self.recover_embed = nn.Linear(self.hiddenDimensionSize, self.keypointDimension)
def forward(self, x):
# 之前: BxMxM
x = self.linear_token(x)
# 之后: BxMxK
# 之前: BxMxK
x = x.transpose(2,1)
# 之后: BxKxM
# 之前: BxKxM
x = self.initial_linear(x)
# 之后: BxKxH
# 之前: BxKxH
for mixer in self.mixer_layers:
x = mixer(x)
# 之后: BxKxH
# 之前: BxKxH
x = self.decoder_layer_norm(x)
# 之后: BxKxH
# 之前: BxKxH
x = self.recover_embed(x)
# 之后: BxKxD
# 之后: BxKxD
x = x.transpose(2,1)
# 之后: BxDxK
return x解码器模块负责接收量化后的标记并重建原始关键点坐标。其结构设计与编码器形成镜像对称,通过多层 MLP 处理和标记-特征混合操作,最终将离散表示投影回每个关节的二维坐标空间。
预训练码本和姿态解码器
在这一阶段,我们采用自监督重建策略来训练码本和姿态解码器。训练过程中使用两类关键损失函数:姿态重建损失和码本承诺损失: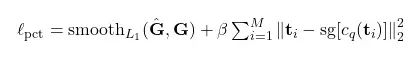
图 3:PCT 模型的损失函数设计 - 来源:https://arxiv.org/abs/2303.11638
重建损失采用目标姿态与预测姿态之间的平滑 L1 距离度量。承诺损失(Commitment loss)则确保编码器输出的连续向量与其被映射到的量化码本条目保持接近,这对于防止编码器忽略码本至关重要。如果缺少承诺损失,编码器可能会生成与实际码本条目相距甚远的任意向量,导致模型无法有效学习离散表示。
初始实验中,我们尝试同时训练组合编码器、码本和姿态解码器:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# --- 数据集 ---
dataset = StickFigureDataset(
num_samples=10000,
image_size=64,
core_radius=1,
limb_radius=5
)
loader = DataLoader(dataset, batch_size=64, shuffle=True)
numberOfKeypoints = 13
dimensionOfKeypoints = 2
linearProjectionSize = 256
numberOfMixerBlocks = 16
codebookTokenDimension = 64
internalMixerSize = 64
internalMixerTokenSize = 32
mixerDropout = 0.1
encoder = CompositionalEncoder(numberOfKeypoints=numberOfKeypoints,
dimensionOfKeypoints=dimensionOfKeypoints,
linearProjectionSize=linearProjectionSize,
numberOfMixerBlocks=numberOfMixerBlocks,
codebookTokenDimension=codebookTokenDimension,
internalMixerSize=internalMixerSize,
internalMixerTokenSize=internalMixerTokenSize,
mixerDropout=mixerDropout).to(device)
codebook = CodebookVQ(codebookDimension=codebookTokenDimension,
numberOfCodebookTokens=codebookTokenDimension,
decay=0.99,
epsilon=1e-5).to(device)
decoder = PoseDecoder(codebookTokenDimension=codebookTokenDimension,
numberOfKeypoints=numberOfKeypoints,
keypointDimension=dimensionOfKeypoints,
hiddenDimensionSize=linearProjectionSize,
numberOfMixerBlocks=numberOfMixerBlocks,
mixerInternalDimensionSize=internalMixerSize,
mixerTokenInternalDimensionSize=internalMixerTokenSize,
mixerDropout=mixerDropout).to(device)
optimizer = torch.optim.Adam(
list(encoder.parameters()) +
list(decoder.parameters()),
lr=1e-4
)
encoder.train()
codebook.train()
decoder.train()
num_epochs = 20
beta = 0.25
for epoch in range(num_epochs):
epoch_loss = 0.0
num_batches = 0
for imgs, gt_keypoints in loader:
keypoints = gt_keypoints.permute(0, 2, 1).to(device)
optimizer.zero_grad()
token_feats = encoder(keypoints)
quantized, _ = codebook(token_feats)
reconstructed = decoder(quantized)
recon_loss = F.smooth_l1_loss(reconstructed, keypoints)
commitment_loss = F.mse_loss(quantized.detach(), token_feats)
loss = recon_loss + beta * commitment_loss
loss.backward()
optimizer.step()
epoch_loss += loss.item()
num_batches += 1
avg_loss = epoch_loss / num_batches
print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")然而,我们观察到学习过程很快趋于饱和,模型仅学习了"平均"二维姿态关键点。深入分析发现,这是因为组合编码器的潜在向量对所有输入姿态都映射到码本中的相同条目,即发生了所谓的"码本崩溃"(codebook collapse)现象。
Epoch 1/20 - Average Loss: 18.5585
Epoch 2/20 - Average Loss: 14.4645
Epoch 3/20 - Average Loss: 11.6697
Epoch 4/20 - Average Loss: 9.7948
Epoch 5/20 - Average Loss: 8.3735
Epoch 6/20 - Average Loss: 7.2084
Epoch 7/20 - Average Loss: 6.5090
Epoch 8/20 - Average Loss: 6.0753
Epoch 9/20 - Average Loss: 5.6844
Epoch 10/20 - Average Loss: 5.4609
Epoch 11/20 - Average Loss: 5.3141
Epoch 12/20 - Average Loss: 5.2014
Epoch 13/20 - Average Loss: 5.1606
Epoch 14/20 - Average Loss: 5.1018
Epoch 15/20 - Average Loss: 5.1005
Epoch 16/20 - Average Loss: 5.0874
Epoch 17/20 - Average Loss: 5.0735
Epoch 18/20 - Average Loss: 5.0267
Epoch 19/20 - Average Loss: 5.0190
Epoch 20/20 - Average Loss: 5.0247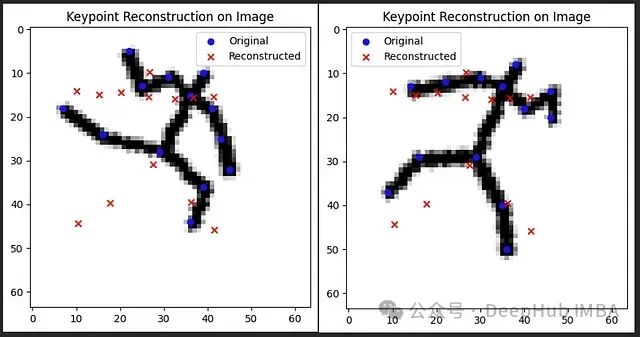
图 4:姿态编码器/解码器的端到端训练结果。注意所有输入都产生相似的解码结果,表明发生了"码本崩溃"现象。
为避免编码器输出被强制映射到单一码本条目的问题,我们采用了分阶段训练策略:首先在不使用码本的情况下训练编码器和解码器,然后冻结编码器权重,并使用码本重新训练新的解码器:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# --- 数据集 ---
dataset = StickFigureDataset(
num_samples=10000,
image_size=64,
core_radius=1,
limb_radius=5
)
loader = DataLoader(dataset, batch_size=64, shuffle=True)
numberOfKeypoints = 13
dimensionOfKeypoints = 2
linearProjectionSize = 256
numberOfMixerBlocks = 16
codebookTokenDimension = 64
internalMixerSize = 64
internalMixerTokenSize = 32
mixerDropout = 0.1
encoder = CompositionalEncoder(numberOfKeypoints=numberOfKeypoints, dimensionOfKeypoints=dimensionOfKeypoints, linearProjectionSize=linearProjectionSize, numberOfMixerBlocks=numberOfMixerBlocks, codebookTokenDimension=codebookTokenDimension, internalMixerSize=internalMixerSize, internalMixerTokenSize=internalMixerTokenSize, mixerDropout=mixerDropout).to(device)
codebook = CodebookVQ(codebookDimension=codebookTokenDimension, numberOfCodebookTokens=codebookTokenDimension, decay=0.99, epsilon=1e-5).to(device)
decoder = PoseDecoder(codebookTokenDimension=codebookTokenDimension, numberOfKeypoints=numberOfKeypoints, keypointDimension=dimensionOfKeypoints, hiddenDimensionSize=linearProjectionSize, numberOfMixerBlocks=numberOfMixerBlocks, mixerInternalDimensionSize=internalMixerSize, mixerTokenInternalDimensionSize=internalMixerTokenSize, mixerDropout=mixerDropout).to(device)
optimizer = torch.optim.Adam(
list(encoder.parameters()) +
list(decoder.parameters()),
lr=1e-4
)
encoder.train()
codebook.train()
decoder.train()
num_epochs = 20
beta = 0.25
skipQuantization = True
print("Encoder pretraining")
for epoch in range(num_epochs):
epoch_loss = 0.0
num_batches = 0
for imgs, gt_keypoints in loader:
keypoints = gt_keypoints.permute(0, 2, 1).to(device) # [B, 2, 11]
optimizer.zero_grad()
token_feats = encoder(keypoints) # (B, M, M)
reconstructed = decoder(token_feats) # (B, K, D)
loss = F.smooth_l1_loss(reconstructed, keypoints)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
num_batches += 1
avg_loss = epoch_loss / num_batches
print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")
# 初始训练后冻结编码器
for param in encoder.parameters():
param.requires_grad = False
# 重置解码器(这一行已经做到了)
decoder = PoseDecoder(codebookTokenDimension=codebookTokenDimension, numberOfKeypoints=numberOfKeypoints, keypointDimension=dimensionOfKeypoints, hiddenDimensionSize=linearProjectionSize, numberOfMixerBlocks=numberOfMixerBlocks, mixerInternalDimensionSize=internalMixerSize, mixerTokenInternalDimensionSize=internalMixerTokenSize, mixerDropout=mixerDropout).to(device)
# 更新优化器,只包括解码器(如有需要,可选择包括码本)
optimizer = torch.optim.Adam(
list(decoder.parameters()),
lr=1e-4
)
print("Codebook and Decoder training")
for epoch in range(num_epochs):
epoch_loss = 0.0
num_batches = 0
for imgs, gt_keypoints in loader:
keypoints = gt_keypoints.permute(0, 2, 1).to(device)
optimizer.zero_grad()
token_feats = encoder(keypoints) # (B, M, M)
quantized, _ = codebook(token_feats) # (B, M, M)
reconstructed = decoder(quantized) # (B, K, D)
recon_loss = F.smooth_l1_loss(reconstructed, keypoints)
commitment_loss = F.mse_loss(quantized.detach(), token_feats)
loss = recon_loss + beta * commitment_loss
loss.backward()
optimizer.step()
epoch_loss += loss.item()
num_batches += 1
avg_loss = epoch_loss / num_batches
print(f"Epoch {epoch+1}/{num_epochs} - Average Loss: {avg_loss:.4f}")分阶段训练策略的训练日志显示了明显改善的学习曲线:
Encoder pretraining
Epoch 1/20 - Average Loss: 18.5178
Epoch 2/20 - Average Loss: 14.1350
Epoch 3/20 - Average Loss: 10.7014
Epoch 4/20 - Average Loss: 8.3755
Epoch 5/20 - Average Loss: 6.5254
Epoch 6/20 - Average Loss: 4.8045
Epoch 7/20 - Average Loss: 3.7144
Epoch 8/20 - Average Loss: 2.9114
Epoch 9/20 - Average Loss: 2.2571
Epoch 10/20 - Average Loss: 1.7662
Epoch 11/20 - Average Loss: 1.4548
Epoch 12/20 - Average Loss: 1.2346
Epoch 13/20 - Average Loss: 1.0853
Epoch 14/20 - Average Loss: 0.9722
Epoch 15/20 - Average Loss: 0.9048
Epoch 16/20 - Average Loss: 0.8413
Epoch 17/20 - Average Loss: 0.7932
Epoch 18/20 - Average Loss: 0.7520
Epoch 19/20 - Average Loss: 0.7124
Epoch 20/20 - Average Loss: 0.6845
Codebook and Decoder training
Epoch 1/20 - Average Loss: 18.7635
Epoch 2/20 - Average Loss: 14.3140
Epoch 3/20 - Average Loss: 10.7931
Epoch 4/20 - Average Loss: 8.4169
Epoch 5/20 - Average Loss: 6.4152
Epoch 6/20 - Average Loss: 4.8894
Epoch 7/20 - Average Loss: 3.9022
Epoch 8/20 - Average Loss: 3.1704
Epoch 9/20 - Average Loss: 2.6313
Epoch 10/20 - Average Loss: 2.1175
Epoch 11/20 - Average Loss: 1.8104
Epoch 12/20 - Average Loss: 1.6105
Epoch 13/20 - Average Loss: 1.4768
Epoch 14/20 - Average Loss: 1.3906
Epoch 15/20 - Average Loss: 1.3409
Epoch 16/20 - Average Loss: 1.2982
Epoch 17/20 - Average Loss: 1.2638
Epoch 18/20 - Average Loss: 1.2331
Epoch 19/20 - Average Loss: 1.2075
Epoch 20/20 - Average Loss: 1.1834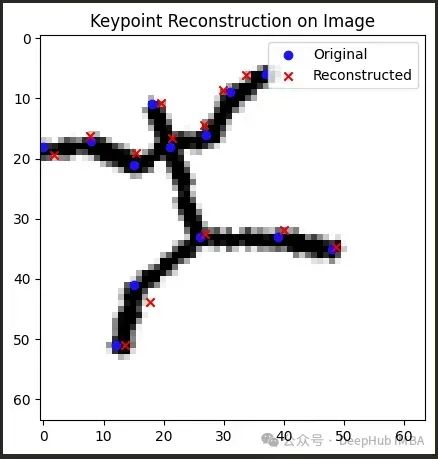
图 5:采用组合编码器预训练策略后的重建结果
这种分阶段训练方法使码本和姿态解码器能够首先学习到有代表性的潜在向量分布,而不必等待编码器同步优化,从而有效避免了码本崩溃问题。
总结
向量量化自编码器(VQ-VAE)为学习离散且紧凑的潜在表示提供了强大的框架,使高效压缩和高质量重建成为可能。然而,这类模型在训练过程中可能面临"码本崩溃"问题,即只有少数码本嵌入被实际使用,从而限制了模型的表达能力。
通过实验验证,采用在引入向量量化之前独立预训练编码器的策略,或结合承诺损失调整与 EMA 更新等技术,可以有效缓解这一问题,确保码本的充分利用和模型的稳健学习。这种基于离散标记的姿态表示方法捕获了关键点之间的结构化关系,为后续的姿态分析和理解任务提供了新的可能性。
https://avoid.overfit.cn/post/87c3039e65974bf693647e4365b55434

