
GTC25 上,老黄拿出了最新也是最强的 BLackWell Ultra GPU(B300),不过这个不是重点,毕竟去年就发布了 B100 和 B200,这个就是小升级。
除了最强 GPU 之外,同时也推出了基于 NV72 互联的 72 卡的机柜。
这是机柜中,GPU 的节点,每层机架上面两组 GB300;
每组 GB300 应该是两个 GPU(B300),和一个 CPU;
所以一个机架应该是,4 个 GPU,2 个 CPU

最上面是 GPU 节点,右边盖子上应该是液冷的走线。

整板的设计图应该如上所示。
这 CPU 和 GPU 以及 NVLINK 连接的图,可以参照如下
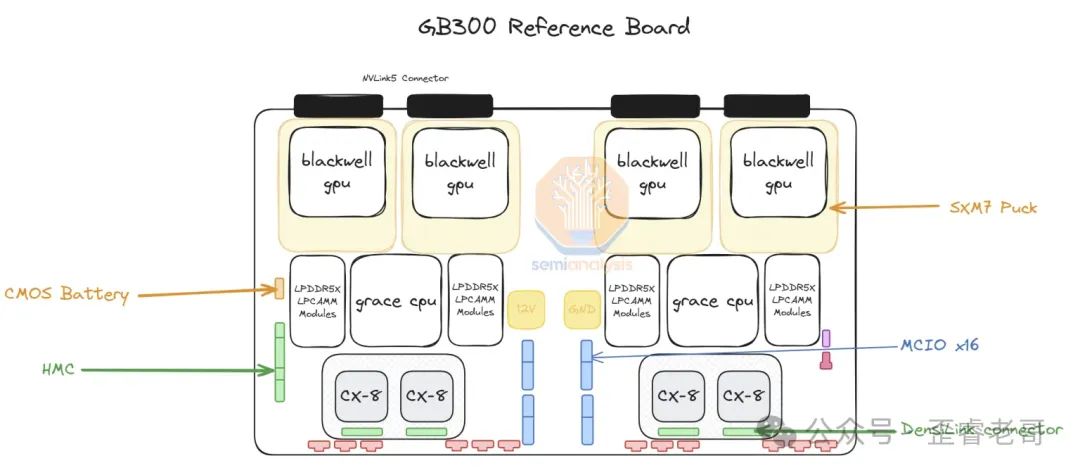
可以看到,除了 NVLINK 之外,还为每个 GPU 配了一个 800G 的网卡,CX-8。
所以,72 个 GPU,需要 18 层。上面 10 层,下面 8 层,中间是 NVLINK 交换机。

中间则是 NV-Switch 的部分。14.4T 的聚合带宽。

除了单个机柜,还有八个机柜的 superpod,里面集成了288 Grace CPU,576 Blackwell Utlra GPU(GB300),300TB HBM3e 内存 288 个 800G 的 CX8;
还有 NVSwich 1.2T 的网络交换机(SpectrumS)

最终达到的效果也比较惊人:11.5 ExaFLOPS FP4。
可以说,通过 8 个机柜就可以达到 E 级别超算能力(只在 FP4)下。
也算一个不小本事。
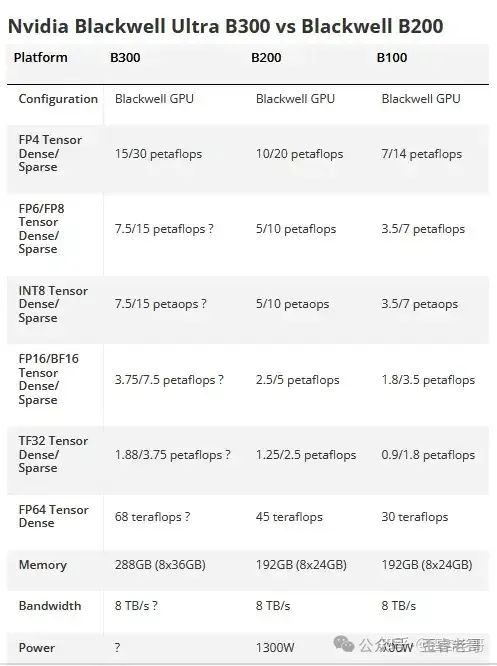
在芯片部分,BLackWell Ultra 也就是 B300。
与现有的 B200 相比,提升了 50%以上的内存和 FP4 计算能力。
整好是 B100 的两倍。
Blackwell Ultra B300 还增加 HBM3e 堆栈的容量。
从 192GB 增加到 288GB。
B300 的实现有两种可能,一种是封装了 4 个 DIE,就是两个 B100(B100 就是两个 DIE)的就计算能力;第二种就是还是 2 个 DIE,只不过每个 DIE 上更多的 SM 核。
就像从 B100 升级到 B200。
具体哪一种,还要看后续,目前有没有更详细的手册。
Blackwell Ultra 可以使用 DeepSeek R1-671B 模型进行了评估。
每秒发送多达 1000 个 token。
(这个应该不是最大的,ISSCC 上的 groq 的 LPU 也能达到上千的 token)。
与之相比,H100 秒只提供最多 100 个 token。
因此,吞吐量增加了 10 倍,将处理较大查询的时间从 1.5 分钟缩短到 10 秒。
并且预告了下一代的 rubin 和在再下一代的 Feynman

其实下一代不是一个芯片,而是一个芯片组。
比如 rubin 的 GPU 预计会换成 HBM4,同时还有更大的计算能力。
NVlink SWITCH 能力也提升了。(3600GB/s)
还有 1.6T 的网卡 CX9,还可以用 CPO 全光的模块和更大容量的交换,102.4T 的交换机。
这一代是 72 个 GPU 的 NVLINK 组合的机柜。
下一代就是 576 个 GPU 的 nvlink 的机柜了。
scaleup 的能力从 72 卷到了 576,这个超节点的能力也没有谁了。
单个芯片太难卷了。
现在就要卷集群。
从单个 GPU 到多个 GPU 的机架,再到多个机架的集群(POD)。
英伟达把系统集成商的活干了,并且管这玩意叫大 GPU。
这种方案,直接对接最终客户,提供交钥匙的方案(turn key)。
还配套发布 Dynamo 推理加速库和 Mission Control 运维平台,并通过 AI 托管服务(Instant AI Factory)降低运维门槛。
从硬件到生态的全栈闭环,有点超越传统芯片厂的范畴,形成软硬一体的生态系统:
这属于 AI factory 的范畴了。
这种芯片厂直接对接客户方的方式。
没有了系统集成厂商。
传统,业界采取是:
芯片商-系统商-客户三级的方式。
(例如 intel 芯片由 DELL 做成服务器卖给 meta)
直接变成了芯片商(nvidia)-客户(meta)两级的方式。
一方面,在 AI 智算时代,这个系统集成的工作非常复杂了不少,我们前面就可以看到。需要 CPU,GPU,NVswitch,NIC,switch 多系统配合,另一方面,AI 系统的调优和优化,很多原厂才能具备的能力或者原厂的能力也不太够。
因为模型在变,各种技术栈和未知点太多了。
AI 大神李沐就吐槽过,用过英伟达的智算集群,在训练时,出了很多问题,给他们解决了很多 BUG。
这种能力,传统的系统集成厂商积累的就更少了。
智算集群这一模式直接冲击传统集成商的两大生存空间。
AMD 收购系统集成商 ZT system,也是要做 AI 智算集群,仿效英伟达提供交钥匙方案。
看来,不论老黄还是苏妈都看上这个市场,不想给中间商赚差价的机会啊。
END
作者:歪睿老哥
文章来源:歪睿老哥
推荐阅读
更多 IC 设计干货请关注IC设计专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

