
AI 加速器对于在边缘设备上部署深度学习模型具有积极的影响,而有效的编译器可以大大减少部署模型的工作量。多级中间表示(MLIR)框架因其可重用和可扩展的编译器基础设施 ,为在 AI 硬件上编译和部署 深度学习模型提供了一种通用且高效的解决方案 。
本工作利用 MLIR 框架来编译 PaddlePaddle 模型,然后使用后端编译器生成目标机器代码(bmodel) ,这些代码随后被部署在 AI 硬件——BM1684X 上 。
实验结果表明,将 PaddlePaddle 框架中的 YOLOv5s 模型编译成 MLIR 文件仅需 4.636 秒,且没有任何精度损失,其时间成本比从 ONNX 编译 YOLOv5s 模型少 20%。使用 FP16 策略的 bmodel 文件在 BM1684X 处理器上执行,从加载模型的输入到输出仅需 6.508 毫秒。
此外,采用局部非量化(即混合精度)策略 可以在损失 1%精度 的情况下将整个计算时间减少 40%。


1. 引言
深度神经网络(DNN)模型已在计算机视觉、语音识别和自然语言处理等各种任务中得到了广泛应用。为了加速深度学习模型的训练过程,工业界和学术界开发了许多框架,如 Caffe、TensorFlow、PyTorch、MXNet 和 PaddlePaddle,这些框架也推动了深度学习在许多领域的进步。然而,每个框架都有其独特的计算图表示,这给在目标 AI 硬件上部署深度学习模型带来了很大的工作量。
与此同时,由于深度学习模型中的矩阵乘法和高维张量卷积操作是复杂的操作,芯片架构师们致力于设计能够在低功耗下实现高性能的通用深度学习(DL)加速器。尽管 GPU 仍然是训练深度模型的主导硬件,几乎所有深度学习框架都在许多任务中支持这种通用硬件,但GPU 并不适合深度学习推理 。因此,许多深度学习加速器,如 Google TPU、Apple Bonic 和 SOPHGO TPU 被探索和设计出来 ,它们比 GPU 更节能 ,并且可以配备在边缘 AI 硬件中以加速深度学习模型的推理,这使得 AI 应用的性能更好。
然而,在将深度学习模型部署到目标 AI 硬件时 ,需要一个统一的中间表示来编译和转换模型 ,从而避免一个框架只能部署到一种 AI 硬件的限制 。
MLIR 具有可扩展的编译器架构,作为不同框架编译模型的统一形式。参考文献[6]支持以 TensorFlow 框架作为输入,并使用 MLIR 将模型编译成可以在 CPU、GPU 和 TPU 上执行的格式。
参考文献[7-8]支持编译像 PyTorch 和 ONNX 这样的机器学习框架,尽管对目标硬件有一些限制。参考文献[9]使用 MLIR 框架编译各种框架,如 ONNX、PyTorch、Caffe 等,支持广泛的算子。转换后的 MLIR 模型通过降低和其他操作生成可以部署在 TPU 设备上的 bmodel 文件。参考文献[10]使用 MLIR 编译 PyTorch 模型,并将其部署在 AI 硬件 AB9 上。
然而,在 PaddlePaddle 框架的模型转换方面仍存在差距,这需要一系列复杂的操作,并且可能存在潜在问题。基于此,本工作提出了一个名为 Paddle-MLIR 的开源深度学习编译器 ,它通过前端编译将 PaddlePaddle 模型转换为 MLIR 文本表示,然后通过降低操作转换为机器代码 。
目前,Paddle-MLIR 已在 CPU 和由 SOPHON 开发的 AI 硬件 BM1684X 上进行了验证。 本文将通过以下内容介绍我们的工作:
- 介绍 Paddle-MLIR 的整体设计和架构 。
- 介绍 PaddlePaddle模型前端编译的过程和优化技巧 。
- 在 BM1684x 上编译和部署 PaddlePaddle 模型,以加速深度学习模型的推理。
2. 背景
A. PaddlePaddle
PaddlePaddle 是由百度开发的一个开源深度学习框架。在构建模型时,神经网络结构由一系列算子(Operators)和变量(Variables)组成。随后,使用“Program”方法,支持三种执行结构:顺序、分支和循环,可以将任何复杂模型的计算过程动态描述出来。
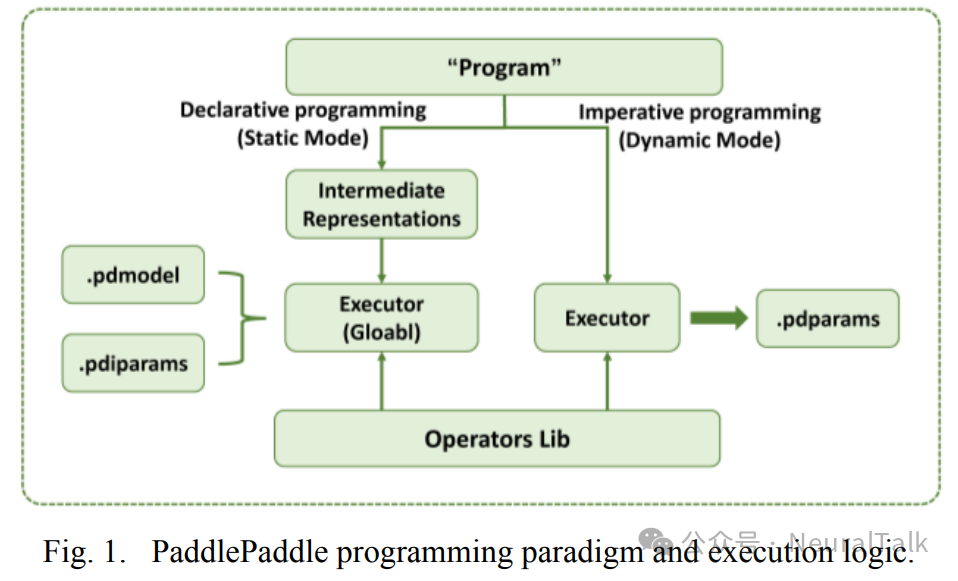
它还支持深度学习模型开发中的两种编程范式:命令式编程和声明式编程。网络编程范式和执行逻辑如图 1 所示。
- 在命令式编程(定义和执行)中,对应动态模式,定义网络结构后直接执行,无需将网络结构编译成中间表示。
- 相反,在声明式编程(执行和定义分离)中,对应静态模式,描述在“Program”中的网络结构首先被编译成中间表示,然后执行。
本工作在编译 PaddlePaddle 模型时专注于模型的静态图模式 。在静态图模式下,模型的表示由两部分组成:一部分是描述网络结构的 pdmodel 文件,另一部分是保存权重文件的 pdiparam 文件。
B. MLIR
MLIR 以其可重用性和可扩展性,为构建特定领域的编译器提供了一种新方法。MLIR 是 LLVM 项目的子项目,与 LLVM 编译架构有许多相似之处。它通过促进不同抽象层次的代码生成器、翻译器和优化的设计与实现,降低了构建特定领域编译器的成本 。
它的操作可以表示从数据流图到特定目标指令,甚至硬件电路的许多不同抽象层次和计算过程 。然而,其后端编译硬件仍在开发阶段。
MLIR 基于静态单赋值形式标准化其中间表示(IR) ,允许人们将一系列概念表示为一级操作。特别是,MLIR 具有操作、属性和类型接口,这些接口提供了一种与 IR 交互的通用方式 。接口可以与操作分开实现,并通过 MLIR 的注册机制混合使用,完全将 IR 概念与转换分开 。
此外,转换可以写成正交的局部“匹配和重写”原语的组合。在将方言从高级转换为低级时,这些通常被进一步分解为重写规则,在将规则转换为低级方言时减少规则。在整个编译过程中,不同的方言可以共存,形成混合程序表示。
C. BM1684X
MLIR 目前仍处于发展阶段,其开放性和可扩展性使其在前端转换中效率很高。然而,目前还没有专门的后端编译器支持目标硬件。因此,我们进行的部署工作是基于使用 MLIR 编译 PaddlePaddle 模型以生成 bmodel 模型 ,从而获得可以在特定 AI 加速器设备(如 BM1684X 处理器)上高效运行的模型文件。
BM1684X 由 SOPHON 开发,作为一种特定的 TPU-AI 加速器芯片,包含一个 TPU 系统和一个 8 核 A53 子系统 CPU ,提供强大的计算能力。因此,BM1684X 在部署和运行深度学习模型时,能够在延迟和功耗效率方面取得更好的结果。
此外,BM1684X 可以应用于 SOPHON 下的各种智能计算产品,实现各种深度学习算法,并支持多种精度类型的推理。在本工作中,使用 MLIR 进行 Paddle 模型的前端编译,然后进行后端编译以生成机器代码,以实现高效部署 。考虑到 BM1684X 的上述优势,本工作使用它来验证我们在部署过程中的前端转换工作。
3. 方法论
本节介绍我们的编译器 Paddle-MLIR。这里将介绍编译过程中的整体架构以及一些转换策略。
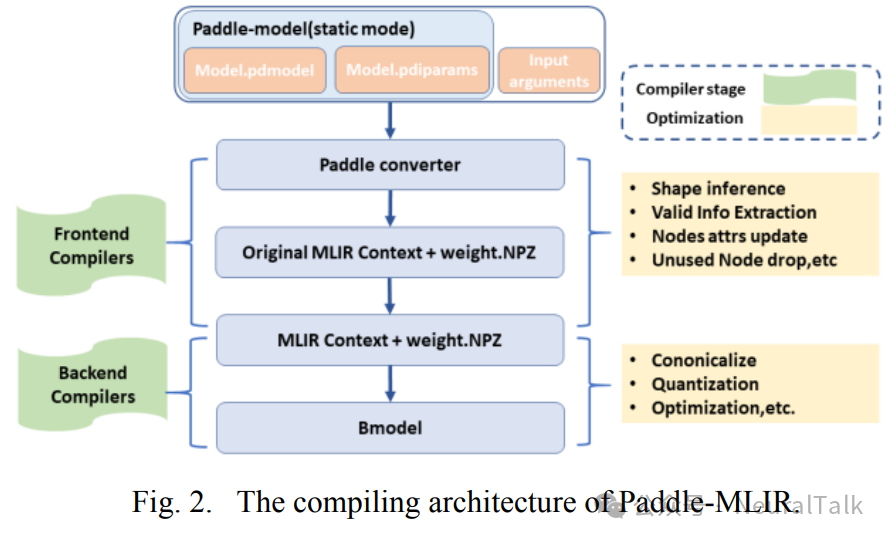
A. Paddle-MLIR 的架构
图 2 展示了 Paddle-MLIR 的整体架构。
首先,输入包括描述 PaddlePaddle 模型的 pdmodel 文件、包含权重信息的 pdiparams 文件以及转换所需的输入预处理参数(例如模型的输入、输出等)。其次,使用 Paddle 转换器(一个 Python 脚本)提取计算图信息,将模型转换为原始的 MLIR 文本描述,并将权重保存在 NPZ 文件中。接下来,使用 SOPHON 的 tpu-mlir 进行优化和其他后端编译过程,生成可以高效运行在特定硬件加速器上的 bmodel 文件 。最后,使用 MLIR 文本描述文件和 bmodel 文件进行推理,以验证我们编译器的有效性。
在 Paddle-MLIR 中,分为前端编译和后端编译两部分 。
- 前端编译:主要使用 paddle-converter 和 TOP 方言将 PaddlePaddle 模型编译为 MLIR 文本表示。
- 后端编译:主要使用 TPU 方言将 MLIR 转换为可以高效运行在特定硬件加速器上的 bmodel 文件。
TOP 和 TPU 方言主要用于验证 Paddle 方言编译的正确性。
B. Paddle 转换器
Paddle 转换器是 Paddle-MLIR 前端转换的一部分 ,它使用 MLIR 语言描述 PaddlePaddle 模型的结构。
Paddle 转换器将导入的 PaddlePaddle 模型编译为 MLIR,生成基于表格的算子定义,以可读文本的形式描述模型中的算子,同时在转换过程中将权重信息保存到 NPZ 文件中。
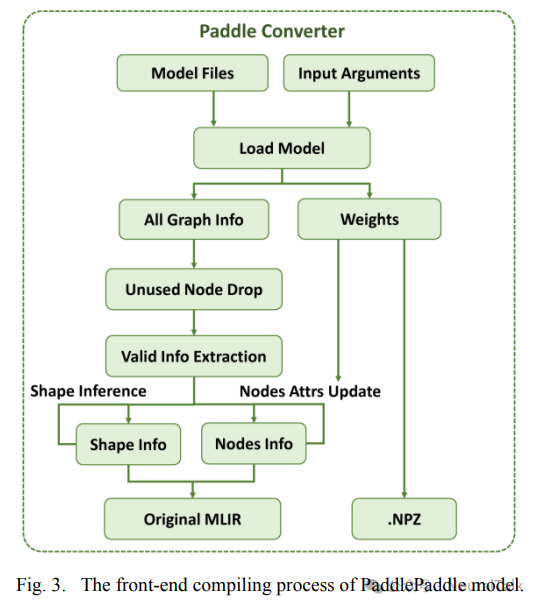
图 3 展示了前端编译过程的流程图 。
- 首先,通过命令行定义必要的输入参数(例如模型输入形状、指定的模型输出节点、模型文件路径、模型定义等)。
- 然后,通过加载模型相关文件提取模型图信息。
- 接下来,使用“节点属性更新策略”(Nodes Attrs Update strategy)更新必要的算子信息,并使用“未使用节点丢弃策略”(Unused Nodes drop strategy)移除模型中的一些后处理算子,只保留从输入到输出的节点,简化模型。
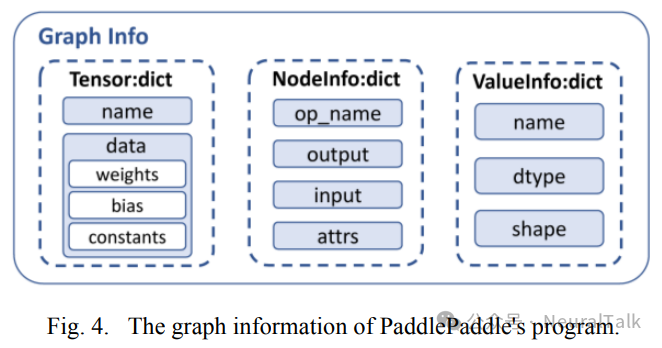
形状推断(Shape Inference)策略可以在转换过程中获取一些节点输入和输出的动态形状的具体信息,并在值字典中更新它们 。此时,已经获得了从输入到输出描述整个 PaddlePaddle 模型结构的所有必要信息,从而将 Paddle 模型转换为初始的 MLIR 文本表示和包含保留权重的 NPZ 文件。图 4 展示了转换过程中程序的图信息的具体内容,包括包含保留权重的张量、包含保留节点信息的字典以及包含每个节点的输入和输出形状的值字典。
C. 优化策略
这里介绍编译过程中为确保模型编译正确性所使用的一些策略。
C.1 节点属性更新(Nodes Attrs Update)
在 MLIR 表示过程中更新算子的必要属性。在 PaddlePaddle 模型中,结构是使用“程序”描述的,程序将描述信息封装在块中 。因此,当提取模型结构信息时,可以从程序的块中获取与整个计算图相关的值和算子。然而,有时某些算子的属性需要通过其他方式获取。
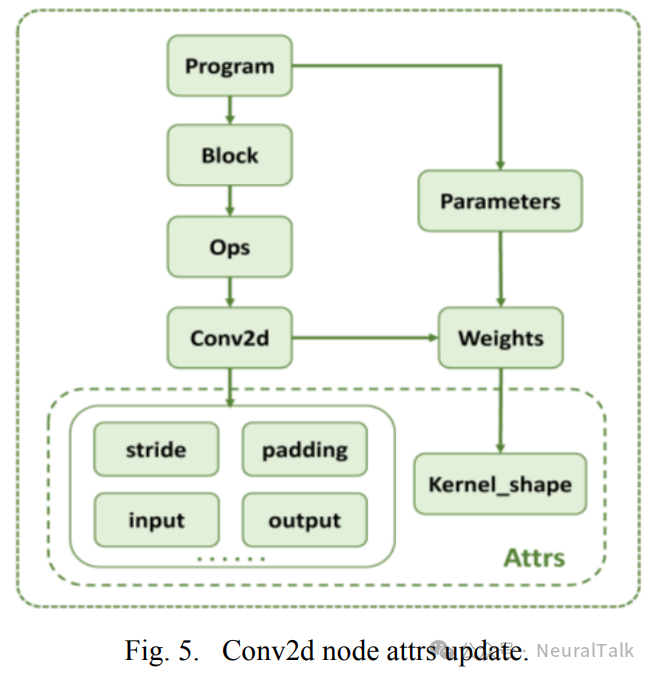
例如,conv2d 算子的卷积核大小可能在模型中加载的算子信息中缺失。通过检索 conv2d 算子的权重形状并将其更新到其属性中,可以获取卷积核的描述。图 5 展示了获取 conv2d 算子相关属性的过程。
C.2 未使用节点丢弃(Unused Node drop)
移除不必要的算子信息 。例如,如果模型包含后处理步骤,这可能会给转换过程带来障碍,因为可能存在复杂的算子,如 where。通过基于输入和输出移除后处理算子,可以简化模型。
C.3 形状推断(Shape inference)
获取 Paddle 模型中未知节点的具体形状。图 6 展示了形状推断的逻辑。
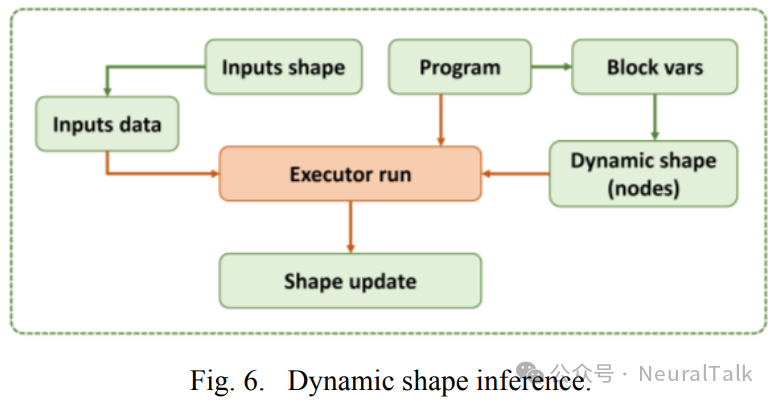
程序描述了模型的结构,在 Paddle 中,每个节点的变量都存储在程序的块中 。因此,通过遍历块中的变量,可以识别出具有动态形状的节点 ,并保存它们的名称。生成与输入形状相同的随机数据作为模型的输入,然后将其传递给执行器以执行模型结构。这个过程可以确定未知的形状,并在相应的节点信息中更新它们。
4. 结果分析
本工作使用 PaddlePaddle 框架中的 YOLOv5s 模型验证 Paddle-MLIR。通过配置输入和输出,我们在装有 BM1684X 处理器的 SE7 微服务器上部署了转换后的模型(bmodel)。
YOLOv5s 模型包含 95 个算子,对应 12 种不同的算子类型,计算量为 16.7GFLOPs。
在介绍相关实验结果之前,让我们先介绍局部非量化(MIX 精度)策略。对于 YOLO 系列模型,最后三个卷积层可以从使用局部非量化中显著受益,以提高模型推理的精度。因此,对于最后三个卷积层,本工作使用了 FP32 量化策略,而其他层仍然使用 INT8 量化策略 。
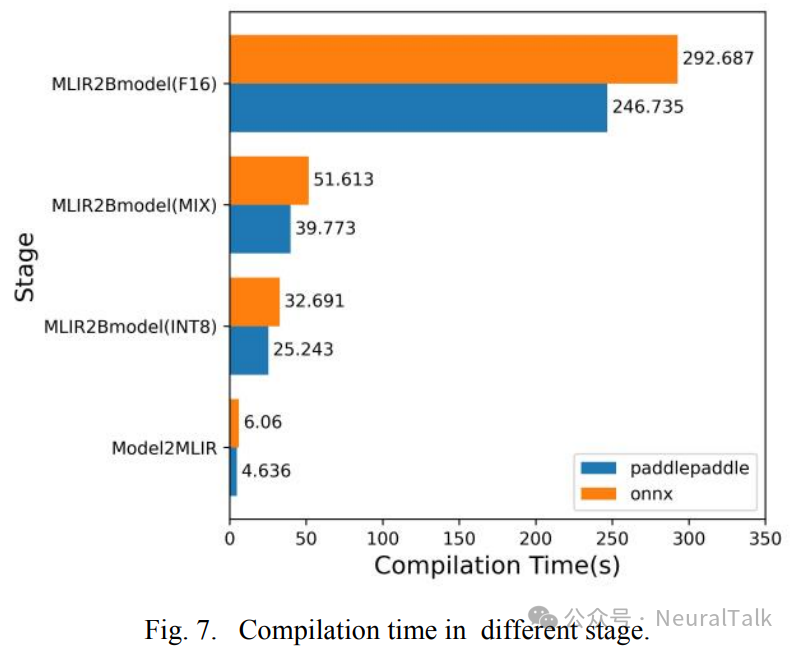
图 7 展示了使用 ONNX 和 PaddlePaddle 框架在 Docker 中编译 YOLOv5s 模型的时间(PC 主机为 core (TM) i7-11700K@3.6GHz),分为四个阶段。
- 第一阶段是从原始模型到 MLIR 文本表示;
- 第二阶段是从 MLIR 文本表示到后端编译时间,量化策略为 INT8 的 bmodel;
- 第三阶段是从 MLIR 文本表示到后端编译时间,量化策略为 MIX 精度的 bmodel;
- 第四阶段是从 MLIR 文本表示到后端编译时间,量化策略为 FP16 的 bmodel。
如图 7 所示,将 PaddlePaddle 中的 YOLOv5s 模型编译为 MLIR 耗时 4.636 秒,而 ONNX 耗时 6.06 秒,这表明PaddlePaddle 的编译时间比 ONNX 少了 20%,这是一个相当显著的减少。
平均精度均值(mAP50-95)是目标检测任务中常用的评估指标之一。它在不同的交并比(IoU)阈值(从 50 到 95,步长为 5)下计算平均精度。在计算 mAP50-95 时,会在不同的 IoU 阈值下计算平均精度(AP),然后取这些 AP 值的平均值以获得最终的 mAP50-95 值。这为评估模型的性能提供了一个全面的评估,因为不同的 IoU 阈值反映了模型在不同精度要求下的性能。表 I 展示了在 COCO 数据集上模型转换的评估结果 。
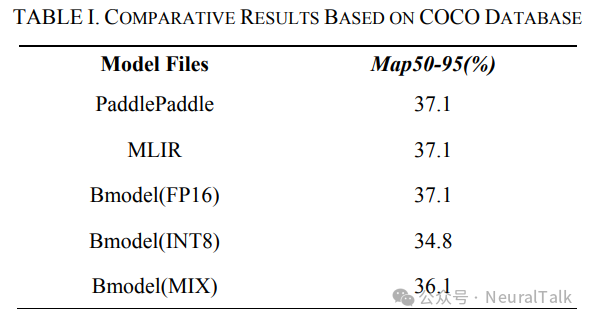
本工作仅讨论不同量化下相应模型的精度 。在FP16 量化策略下,经过 MLIR 转换后的 mAP50-95 为 37.1%,与原始模型的 mAP50-95 一致 ,表明精度基本保持不变。
然而,在 INT8 策略下,精度为 34.8%,下降了 2.3%。因此,本工作使用 MIX 方法将精度提高到 36.2%,增加了 1.4%,这是一个相对较好的结果。
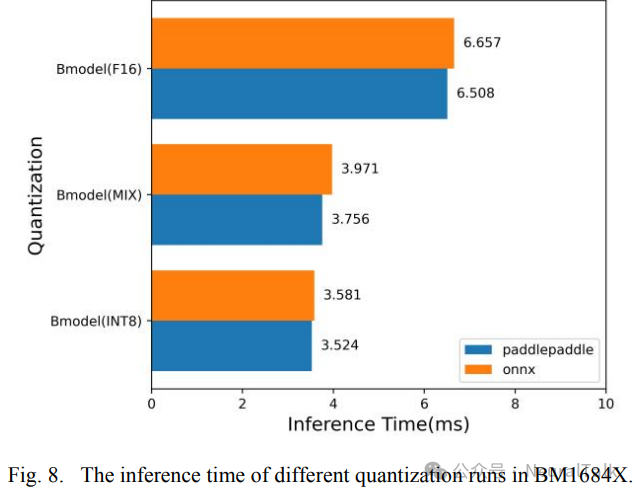
此外,后端转换的 bmodel 文件将部署在装有 BM1684X 处理器的 SE7 微服务器上,图 8 展示了在不同量化方法下模型在 SoC 上的计算时间 。本工作仅考虑时间增加的比例,因为不同的计算能力会导致计算时间的差异。使用 MIX 方法比 INT8 量化方法增加了不到 10%的时间 ,实现了有利的权衡。
5. 结论
为了便于在边缘智能设备上部署 AI 应用,本工作提出了 Paddle-MLIR,它利用 MLIR 框架编译 Paddle 模型,然后生成目标机器代码。随后,这些机器代码在由 SOPHON 开发的边缘智能设备 SE7 上执行。
本文还介绍了前端模型转换中的一些优化策略,以确保编译的正确性。实验结果表明,Paddle-MLIR 可以在 4.636 秒内将 YOLOv5s 从 PaddlePaddle 编译为 MLIR,且没有任何精度损失,与 ONNX 框架相比,编译时间减少了 20%。
最后,将编译后的文件部署在 SE7 上,使用 FP16 量化策略的 YOLOv5s 的计算时间为 6.508 毫秒。此外,通过使用局部非量化策略,计算时间可以进一步减少 40%,仅损失 1%的精度。
参考文献
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012).
[2] Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Hinton, Geoffrey, et al. “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups.” IEEE Signal processing magazine 29.6 (2012): 82-97.
[4] Oh, Kyoung-Su, and Keechul Jung. “GPU implementation of neural networks.” Pattern Recognition 37.6 (2004): 1311-1314.
[5] Lattner, Chris, et al. “MLIR: A compiler infrastructure for the end of Moore's law.” arXiv preprint(2020).
[6] Abadi, Martín, et al. “Tensorflow: Large-scale machine learning on heterogeneous distributed systems.” arXiv preprint (2016).
[7] LLVM(2024). Torch-MLIR [online]. Available: https://github.com/llvm/torch...
[8] Jin, Tian, et al. “Compiling onnx neural network models using mlir.” arXiv preprint arXiv:2008.08272 (2020).
[9] Hu, Pengchao and Lu, Man and Wang, Lei and Jiang, Guoyue. “TPU MLIR: A Compiler For TPU Using MLIR.” arXiv preprint arXiv:2210.15016 (2022).
[10] Kwon, Hyunjeong and Kim, Hyun Mi and Lyuh, Chun-Gi and Kim, Jin Kyu and Han, Jinho and Kwon, Youngsu. “AIWareK: Compiling PyTorch Model for AI Processor Using MLIR Framework.” 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS). IEEE, 2022.
[11] Cho, Yong Cheol Peter, et al. “AB9: A neural processor for inference acceleration.” ETRI Journal 42.4 (2020): 491-504.
[12] Ma, Yanjun and Yu, Dianhai and Wu, Tian and Wang, Haifeng. “PaddlePaddle: An open-source deep learning platform from industrial practice.” Frontiers of Data and Domputing 1.1 (2019): 105-115.
[13] Ao, Yulong, et al. “End-to-end adaptive distributed training on paddlepaddle.” arXiv preprint arXiv:2112.02752 (2021).
[14] LLVM: The LLVM Project, 2024. [online]. Available: https://github.com/llvm/llvm-...
[15] Lattner, Chris, and Vikram Adve. “A compilation framework for lifelong program analysis and transformation.” CGO. Vol. 4. 2003.
[16] Vasilache, Nicolas, et al. “Composable and modular code generation in MLIR: A structured and retargetable approach to tensor compiler construction.” arXiv preprint arXiv:2202.03293 (2022).
[17] PaddlePaddle: PaddleYOLO, 2024. [online]. Available: https://github.com/PaddlePadd...
[18] Krishnamoorthi, Raghuraman. “Quantizing deep convolutional networks for efficient inference: A whitepaper.” arXiv preprint arXiv:1806.08342 (2018).
[19] Jacob, Benoit, et al. “Quantization and training of neural networks for efficient integer-arithmetic-only inference.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[20] Jin, Tian, et al. “Compiling onnx neural network models using mlir.” arXiv preprint arXiv:2008.08272 (2020).
END
作者:深圳大学
来源:NeuralTalk
推荐阅读
- 一起聊聊 Nvidia Hopper 新特性之计算切分
- 为二值神经网络扩展 NPU 二值 GEMM 核心功能单元和编译器
- 一起聊聊 Nvidia Hopper 新特性之 TMA
- LLM 技术报告系列 | Google 团队正式放出 Gemma 3 技术报告
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

