
研究背景
❝ 大型语言模型(LLMs)时代,密集运算(如通用矩阵乘法 GEMM 和多头注意力 MHA)至关重要,且适合用基于 tile 的方法在 GPU 上并行执行。传统 GPU 编程依赖低级接口(如 CUDA 或 SYCL),而 Triton 作为一种新兴的领域特定语言(DSL),提供了更友好且可移植的高层编程方式。当前 Triton 的编译方式存在局限性,本文提出了一种新的,具有多级编译流程和编程接口的 Triton 语言扩展,以更好地利用 GPU 的层次化结构,提升编译器的解耦合性与清洁性,满足内核开发者对最新硬件性能的精细控制需求。

1. 背景知识
1.1 Intel GPU 架构
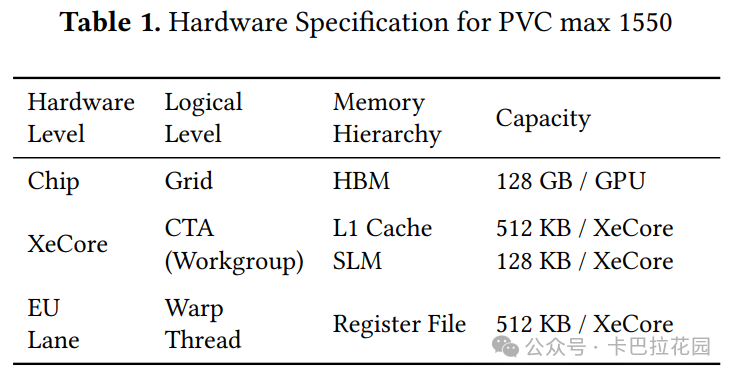
Intel Ponte Vecchio GPU(PVC)是专为 AI 推理和训练工作负载设计的,具有模块化架构:
- 包含两个 tile(瓦片,可以理解为 GPU 的基本构建模块)
- 每个 tile 包含 64 个 XeCore(执行核心,类似于 Nvidia GPU 中的 CUDA 核心)
- 每个 XeCore 包含 8 个执行单元(EU,Execution Unit)
- 每个 EU 支持 8 个硬件上下文,使用原生 SIMD16 指令(单指令多数据指令,一种并行计算指令集)进行操作
PVC 具有先进的内存层次结构,包括全局内存、L2 缓存、共享本地内存(SLM,类似于 Nvidia GPU 中的共享内存)和 L1 缓存,以提高数据访问效率和计算速度。
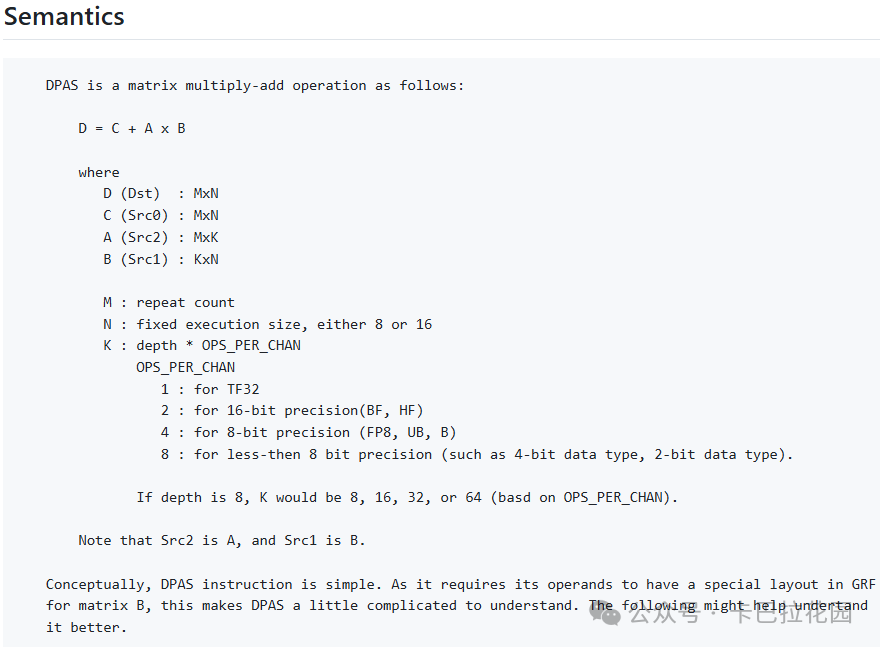
此外,PVC 还支持 1D/2D 块加载/存储/预取指令以及 DPAS 指令(点积累积指令,用于加速矩阵乘法等计算密集型任务,见下图,详见:https://github.com/intel/inte... ),以进一步优化数据传输和计算性能。
❝ 简单来说,PVC GPU 就像是一个超级计算工厂,专门用于处理 AI 模型中的大量计算任务,能够快速、高效地完成复杂的数学运算,从而加速 AI 模型的训练和推理过程。与我们常见的 CPU 不同,它更像是一个专门设计用来处理图形和并行计算任务的艺术家,拥有许多小工作站(核心),可以同时处理大量相似的任务。
1.2 Triton 语言及其编译流程
Triton 是一种专为 GPU 内核开发设计的高性能编程语言,具有 Python 风格的语法和工作组级别(workgroup level,类似于 CUDA 中的线程块级别)编程接口,使 GPU 编程对 AI 研究人员和工程师更加友好。
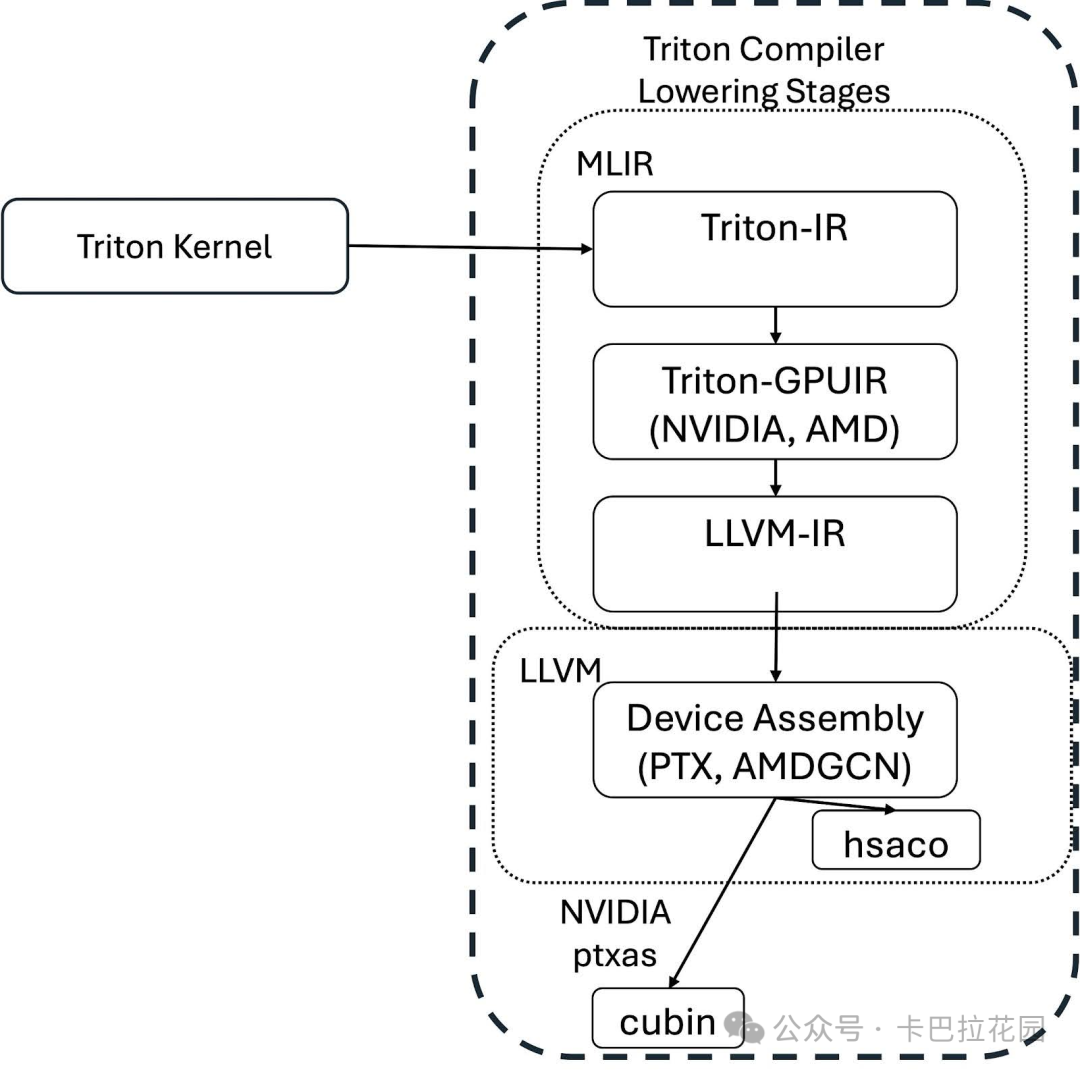
Triton 编译器基于 MLIR(多级中间表示,一种编译器基础设施)构建,其编译流程包括生成 Triton IR(中间表示)、转换为 Triton GPU IR、中间端优化以及最终转换为 LLVM IR(低级虚拟机中间表示)。
1.2.1 Triton Dialect
Triton 方言(Triton dialect)是 Triton 编译器引入的一种特定的语法和操作集合,专门用于描述张量上的块级操作。在 Triton 中,张量(tensor)表示一个 N 维数组,可以是值或指针。默认情况下,Triton 使用指向块的指针(block pointer)作为主要的内存访问机制,这种指针显式地传达了数据的连续性信息,对于密集操作来说,这种方式比默认的指针数组方法更高效。

Triton 方言的主要操作包括获取程序 ID(get_program_id)、加载张量(load)、存储张量(store)、矩阵乘法(dot)、归约操作(reduce)、创建张量指针(make_tensor_ptr)以及调整张量指针的偏移量(advance)等。
1.2.2 Layout Encoding
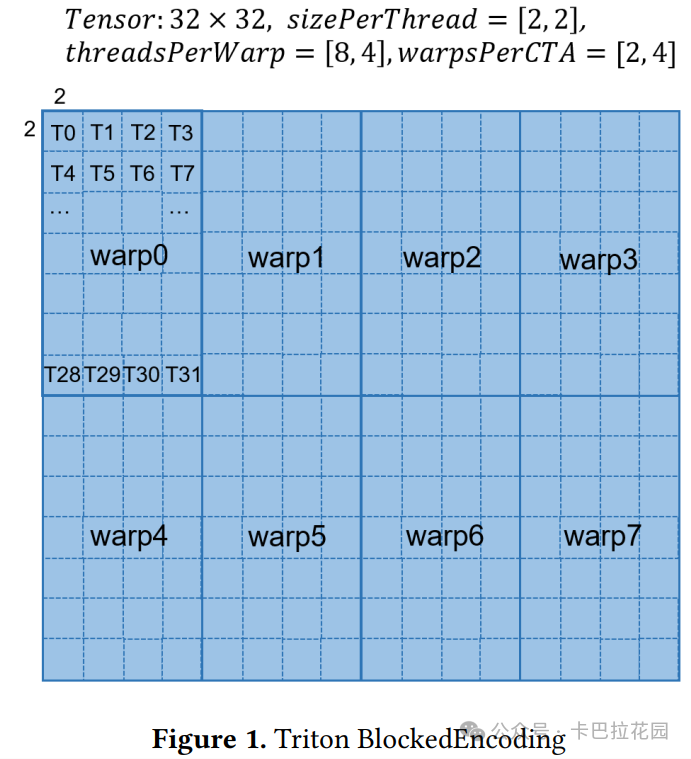
布局编码(layout encoding)是 Triton 中用于描述张量在内存中布局以及数据如何在线程之间分配的一种元数据机制。通过布局编码,可以指定数据在不同线程中的分布方式,从而帮助编译器优化内存访问和计算。

Triton 中的布局编码包括块编码(BlockedEncoding)、点操作数编码(DotOperandEncoding)和切片编码(SliceEncoding)等。
- 块编码表示张量的一个连续部分,其参数包括每个线程操作的块大小(sizePerThread)、线程在 Warp 中的排列方式(threadsPerWarp)、Warp 在 CTA 中的排列方式(warpsPerCTA)以及内存访问顺序(order)。
- 点操作数编码用于点操作的参数,表示其父布局编码和在点操作中的位置。
- 切片编码表示在父布局编码的基础上沿某个维度进行压缩。
❝ 内容补充:CTA(Cooperative Thread Array)和 Warp 的关系 在 GPU 编程领域,CTA(Cooperative Thread Array)和 Warp 是两个重要的概念,它们在并行计算中扮演着不同的角色,但又紧密相关。 CTA(Cooperative Thread Array)
CTA,即协作线程组,是 CUDA 编程模型中线程块(thread block)的实现形式 。它是线程的集合,这些线程被调度到同一个流式多处理器(SM)上执行。CTA 中的线程可以共享同一块内存空间,通过共享内存和同步机制(如__syncthreads() )进行通信和数据交换。CTA 是 GPU 上执行并行任务的基本单位之一,它让一组线程能够方便地一起完成复杂的计算任务。 Warp(线程束) Warp 是 GPU 中执行相同指令的线程集合,作为 GPU 的硬件 SM 调度单位 。在 NVIDIA GPU 中,一个 Warp 通常由 32 个线程组成,它们在同一个时钟周期内并行执行相同的指令,实现了单指令多线程(SIMT)的并行计算模型。Warp 是 SM 中最小的调度单位,一个 SM 可以同时处理多个 Warp。 CTA 与 Warp 的关系
CTA 和 Warp 之间的关系可以理解为一种层次结构: 包含关系:一个 CTA(线程块)由多个 Warp 组成。例如,如果一个 CTA 包含 256 个线程,那么这个 CTA 将被划分为 8 个 Warp(256/32 = 8)。调度关系:CTA 是程序员定义的逻辑分组,而 Warp 是硬件定义的调度单元。在执行过程中,CTA 被分解为多个 Warp,这些 Warp 被调度到 SM 的 Warp 调度器上,等待执行。执行关系:在同一个 CTA 内的 Warp 可以共享同一块内存空间,进行数据交换和同步。而不同 CTA 中的线程则不能直接通过屏障同步,它们必须通过全局内存进行协调。 CTA 和 Warp 是 GPU 编程中不可或缺的概念。CTA 提供了逻辑上的线程组织方式 ,方便程序员管理和协调线程;而Warp 则是硬件实际调度和执行的单位 ,确保了线程能够高效地利用 GPU 的并行计算资源。理解它们之间的关系有助于更好地设计和优化 GPU 上的并行算法。
1.2.3 Compilation Flow
Triton 的编译流程(compilation flow)包括以下几个阶段:
- 首先,内核函数被装饰为 triton.jit ,Triton 编译器会遍历内核函数的抽象语法树(AST)以生成 Triton IR,使用标准的静态单赋值(SSA)构造算法。
- 然后,Triton IR 被转换为 Triton GPU IR,通过添加一个简单的布局编码来指定数据在 Warp 之间的分布。
- 接下来,Triton GPU IR 会经历一系列中间端优化,旨在分析和简化代码,包括内存合并、点积特定增强、软件流水线等优化操作。
- 最后,Triton GPU IR 被转换为 LLVM IR,可以传递给 GPU 后端编译器以生成可执行的二进制代码。
整个流程如下图所示:
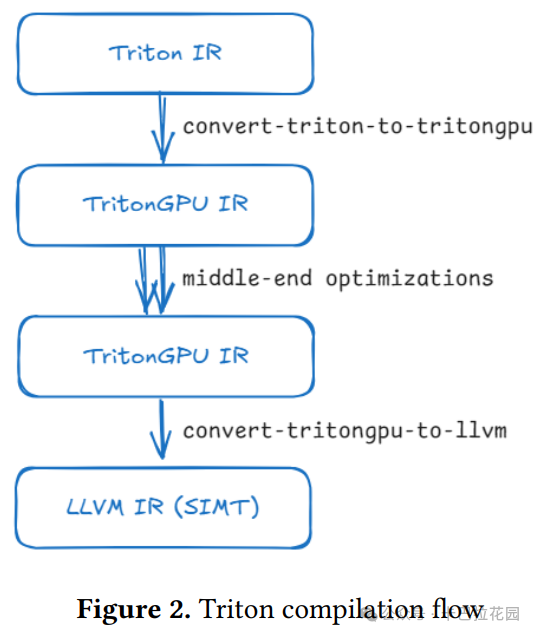
2. ML-Triton 的多级编译流程
而本文,我们提出的编译流程如图 3 所示,通过多级降低来反映 GPU 的层次结构 。
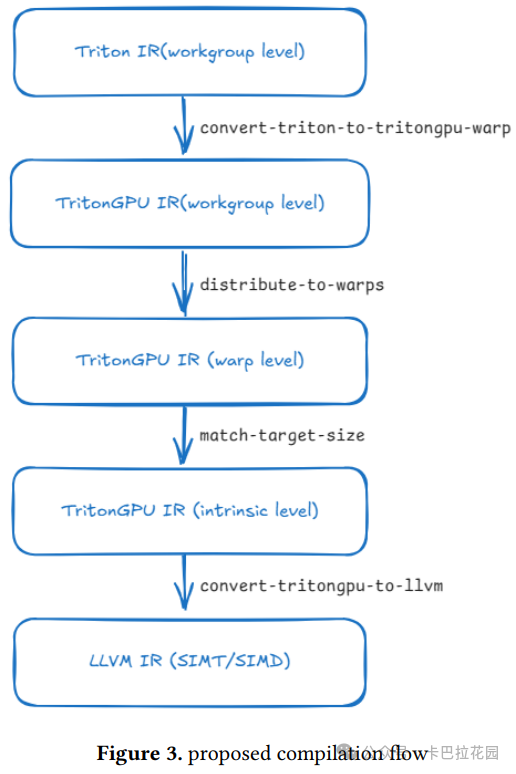
多级逐步降低的编译方法
这种方法将不同层次的考虑因素解耦,使得优化更加高效和有针对性 。最初,Triton IR 在 Workgroup 级别(工作组级别,可以理解为一组线程的集合)上运行,然后我们通过添加适当的布局编码将其转换为 TritonGPU IR,以指定数据在 Warp(warp,一种线程组的逻辑划分)之间的分布。接下来的将工作负载分布到 Warp 的 pass 将把内核工作负载转换为 Warp 级别,即每个 Warp 应该处理的内容。
匹配目标大小的 pass 会进一步拆分操作,以匹配硬件目标支持的 LLVM 固有函数大小,我们将其称为 Intrinsic 级别(固有级别)。最后,TritonGPU IR 被转换为 LLVM IR,采用 SIMT 或 SIMD 风格。


具体编译流程阶段
2.1 Convert-triton-to-tritongpu-warp
❝ 转换 Triton 到 TritonGPU Warp 这一阶段。这个 pass 首先分析内核的工作负载模式 (例如元素级操作、归约操作、GEMM、注意力机制等),然后确定根操作 (如 tt.dot 操作)的最佳布局编码 。随后,我们通过定义-使用链传播来推导出其他所有值的布局编码 。
我们使传播规则变得简单明了:除了之前介绍的 tt.dot 和 tt.reduce 规则外,其他操作(包括 tt.load 、tt.store 、tt.advance 以及 arith/math 的单目/双目操作)要求所有源操作数和结果共享相同的布局编码。
但与上游 Triton 相比,有三个主要区别。
- 工作负载感知。根据工作负载的不同,点操作可能需要不同的分区策略来实现最佳性能。例如,对于典型的 GEMM,方形分区最为有利,而 FlashAttention-2 则更倾向于沿行维度分区,以最小化 Warp 之间的通信并实现峰值性能。
- 一次性布局编码:我们的方法在一步中确定布局编码,而上游 Triton 最初分配一个简单的布局编码,并在后续 pass 中进行细化。
- 关注 sizePerWarp:旨在获取每个 Warp 处理的块大小(sizePerWarp),而不是每个线程的块大小。在一开始就获取每个线程处理的内容是一种过早的下沉(lowering)。
因此,对于 GEMM 示例,首先需要确定根操作 c += tt.dot a, b 的布局编码。
- 已知 c 的工作组大小为[256, 256] ,Warp 数量为 32。
通过在 Warp 之间进行平方分区,我们得到 c 的块编码:
- 每个 Warp 在 CTA 中的排列方式为[8, 4] 。
- 每个 Warp 处理的块大小为[32, 64] (工作组大小除以每个 Warp 在 CTA 中的排列方式)。
然后,a 和 b 分别具有点操作数编码。最后,通过之前描述的传播规则,所有张量类型都被标注了布局编码,如列表 2 所示。注意,我们生成的 Triton GPU IR 保留了与 Triton IR 相同的操作。通常来说,上游 Triton 会引入许多“convert-layout”操作来帮助降低工作负载。
2.2 Distribute-to-warps
❝ 这个 pass根据相应的布局编码将工作组的工作负载分布到各个 Warp 。在这个 pass 之后,我们得到每个 Warp 应该处理的内容。
之前我们修改了块编码以包含每个 Warp 处理的块大小和每个 CTA 中的 Warp 数量,这些参数决定了工作负载如何分布。因此,第一步是获取每个布局编码的等效块编码。对于点操作数编码和切片编码,我们从其父布局编码推导而来。映射规则详细列在表 3 中。

对于 GEMM 示例,图 4 展示了 Warp 之间的数据分布。矩阵 C 被均匀分布,每个 Warp 处理一个 32x64 的块。对于矩阵 A,尽管每个 Warp 处理的第二维度大小已经与工作组大小匹配,但我们仍有 4 个 Warp 需要排列,因此 Warp 0-3 处理 A 的同一个 32x32 子块。
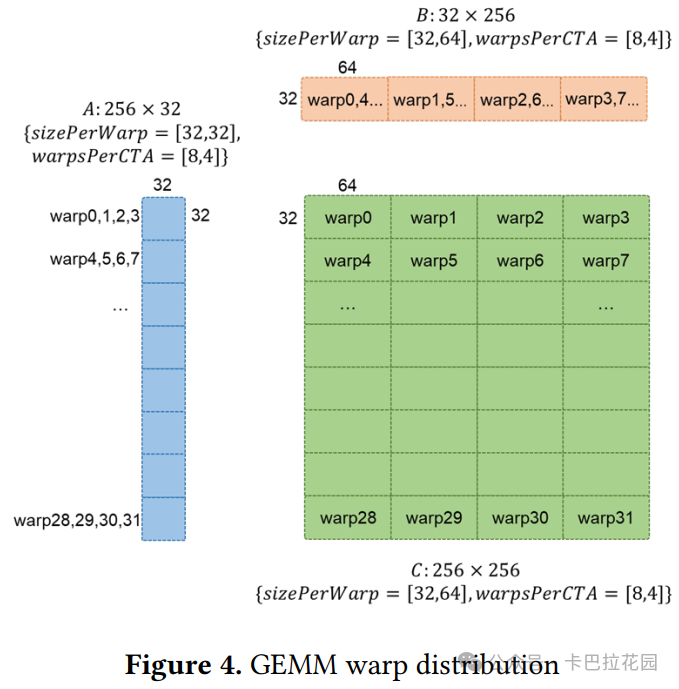
同样,Warp 0,4,8..28 处理 B 的同一个 32x64 子块。在这个 pass 之后,如列表 3 所示,tt.dot 被从 256x256=256x3232x256 转换为 32x64=32x3232x64,tt.make_tensor_ptr 的偏移量也从 tt.program_id 的函数调整为 tt.program_id 和 gpu.subgroup_id (即 warp_id)的函数。
3.3 Match-target-size
❝ 将操作拆分为更小的操作,以匹配目标 LLVM 固有函数(intrinsic)的大小 。所有共享相同布局编码的值将被一致地拆分,除非某个操作需要不同大小。用户可以指定最大加载大小和最大点积大小等选项。
对于 GEMM 示例,PVC 的最大加载大小为 32x32,最大点积大小为8x16=8x16*16x16。数据分区如图 5 所示。
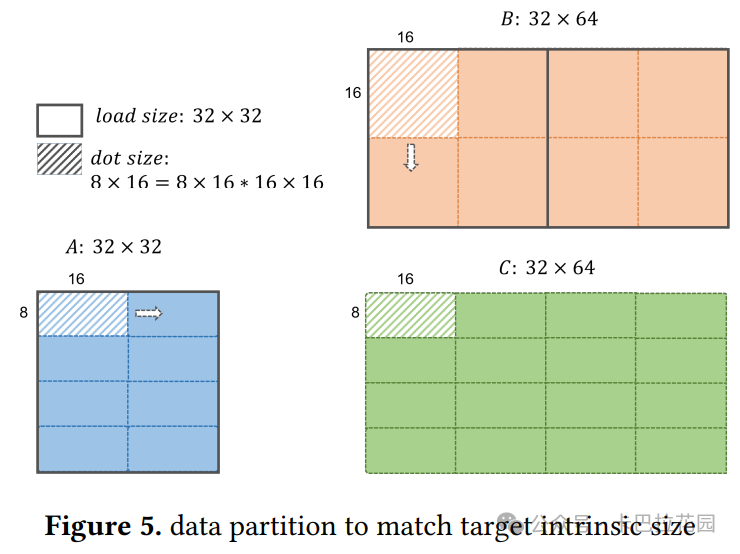
在这个 pass 之后,如列表 4 所示,A 的加载大小为 32x32,已经匹配目标加载大小,因此保持不变。然而,B 的加载大小为 32x64,被拆分为 2 个加载操作。点积操作从 32x64=32x3232x64 拆分为 32 个更小的点积操作,每个大小为 8x16=8x1616x16。
所有在定义-使用链中的加载值都被拆分为处理 32x32 块的操作。由于 tt.dot 需要不同的块大小,添加了 tt.extract 来从 A 中提取 8x16 的子块和从 B 中提取的 16x16 子块,这些子块随后被馈送到点积操作中。注:tt.extract 在实际应用中,被移动到 triton_intel_gpu 方言中。
4.4 Convert-tritongpu-to-llvm
❝ 将所有操作转换为 LLVM IR,利用 PVC GPU 后端编译器提供的固有函数(intrinsic) 。对于SIMT 转换 ,数据将均匀分布到每个线程通道 ,固有函数中的向量大小需要除以每个 Warp 的线程数。
这个 pass 它重用了上游 MLIR 转换对于 arith、math 和 scf 操作的转换模式。对于 Triton 操作,使用单独的转换模式将它们映射到 LLVM 固有函数(intrinsic)。PVC GPU 后端编译器提供了两组固有函数 :用于 SIMD 编程的 VectorCompute 固有函数 和用于 SIMT 编程的 GenISA 固有函数 。
基本上,转换是一个一对一的机械映射,因为我们已经使操作匹配目标支持的固有函数大小。只是对于 SIMT 转换,数据被均匀分布到每个线程通道,意味着固有函数中的向量大小需要除以每个 Warp 的线程数,见表 4。
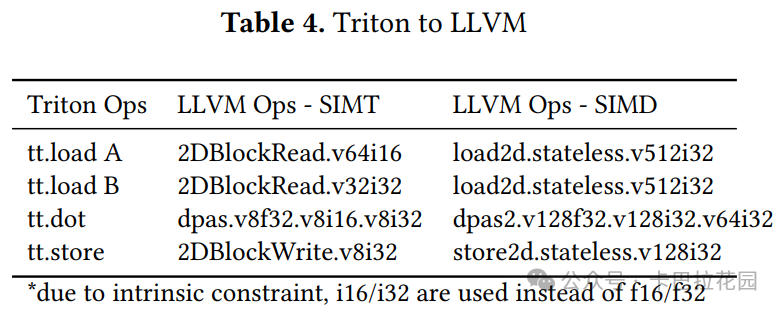
以 tt.load A 为例,工作负载大小 32x32xf16 被展平为 v512i32 ,当除以 PVC 的每个 Warp 的线程数(16)时,结果为 v64i16 。列表 5 显示了转换后的 LLVM IR。

11.5 FlashAttention-2
❝ 正如编译流程中所展示的,每个值的布局编码是关键 。布局编码决定了工作在不同 Warp 之间的分配方式 ,并作为指导,指示每个操作应如何拆分以匹配目标固有函数大小 。一旦每个值都被正确标注了布局编码,后续的 pass 就可以有效地应用。一旦我们确定了根操作的布局编码,所有其他值的编码都可以通过跟踪定义-使用链(use-def chain)来推导 。这种方法自然地促进了操作的预融合和后融合,因为它们可以从根操作无缝扩展。
以 FlashAttention-2 为例。它可以看作是两个背靠背的 GEMM 的融合内核,中间有一个在线 softmax,如算法 1 中概述的。

我们采用了原始论文中的工作分区方式,该方式沿行维度在所有 Warp 之间分布输出矩阵 O,并访问 K/V 。在平衡 Warp 之间共享的数据和寄存器压力后 ,我们得到了 PVC 的以下内核配置:
- O 的工作组大小为[128, 64] ,Warp 数量为 8
- 通过在 Warp 之间进行水平分区,我们得到 O 的块编码:
- 每个 CTA 中的 Warp 排列方式为[numWarps, 1] = [8, 1] ,
- 每个 Warp 处理的块大小为[workgroupSize / warpsPerCTA] = [16, 64]
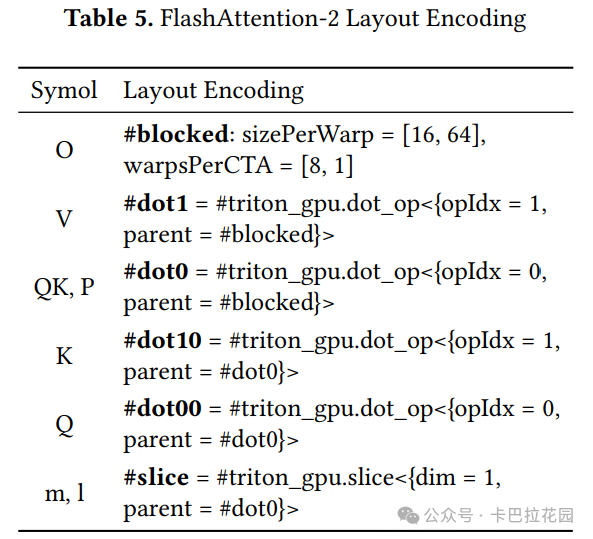
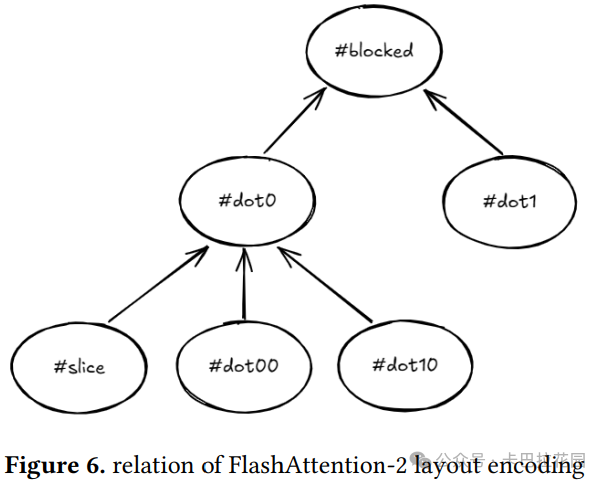
随后,所有其他张量的布局编码通过推导得到,如表 5 中总结的。图 6 展示了它们之间的关系。
3. ML-Triton 的语言扩展
3.1 编译器提示(Compiler Hint)
❝ 在代码生成流程中 ,我们借助一种工作负载感知的 pass 来识别特定模式 ,并确定根操作的 tile 分区 ——布局编码。实际上,这一设置源自专家内核调优经验的最佳实践 。然而,在某些情况下,研究人员可能希望手动定义 tile 分区。例如,FlashAttention-2 明确提出了如何在不同线程组(Warp)之间分配工作以实现最优性能。
因此,我们引入了一种编译器提示,允许用户指定根操作在 tile 分区时的策略 。以下是针对二维张量可用的 tile 选项:
- 水平分区:沿第一维度(行)均匀地将数据划分为多个部分。
- 垂直分区:沿最后一维度(列)均匀地将数据划分为多个部分。
- 方形分区:将数据划分为方形子块。
对于 FlashAttention-2,仅需设置第二个点积的 tile 方式为水平,而无需更改其他源代码。编译器会根据这一提示,自动推导出所有其他值的布局编码 。
示例代码:
o = tl.dot(p, v, o, tiling="horizontal")
3.2 线程组(Warp)级别 API
❝ 尽管在工作组级别编写内核可以减轻开发人员的负担,但性能往往高度依赖于编译器 ,而编译器的优化需要时间来不断发展和完善。与其完全依赖编译器特定的优化,我们认为更有效的方法是赋予开发人员对其代码的细粒度控制权 。
例如,FlashAttention-3 提出了更好的线程组管理方式,以充分利用最新的硬件功能。同样,许多内核库(如 CUTLASS)也提供了线程组级别的 C++ 模板 。因此,我们引入了线程组级别的语言扩展 。
关键特性包括:
- warp_level :元数据,表明这是一个线程组级别的内核。
- tl.warp_id() :返回当前线程组在线程组内的线性 ID。
- tl.alloc(shape, data type) :分配并返回一个指向共享本地内存(SLM)中具有指定形状和数据类型的块的指针。
- tl.reduce(..., cross_warp, dst_warps) :为归约操作(如求最大值、求和等)添加了关键字参数。当 cross_warp 设置为 true 时,表示在所有线程组之间进行归约;否则,表示在当前线程组内进行归约。dst_warps 参数允许将归约结果仅广播到指定的目标线程组。如果未设置,则结果将广播到所有线程组。
通过Warp 级别 API,开发者可以 :
- 分配共享内存:在 GPU 的共享本地内存(SLM)中分配空间,用于存储临时数据 ,这类似于在高速缓存中开辟一块专属的“工作区”。
- 跨 Warp 通信:实现不同线程组之间的数据同步和交换 ,例如在执行归约操作(如求和、求最大值)时,能够高效地整合各个线程组的计算结果。
- 精细控制计算流程:针对每个线程组定制计算逻辑,这对于处理分页注意力(Paged Attention)等复杂任务至关重要,因为它允许开发者明确指定每个线程组的工作内容,避免不必要的计算重复 。
这些功能使得开发者能够以更细粒度的方式优化代码,充分发挥 GPU 的并行计算优势。
大型语言模型(LLM)推理过程通常涉及键值(KV)对的长序列。为了提高吞吐量,Flash Decoding 提出将键和值分开处理。为了高效管理内存,分页注意力(Paged Attention)将请求的 KV 缓存划分为多个块。
列表 6 展示了如何实现分页注意力 Triton 内核。尽管核心算法与 FlashAttention-2 相似,但由于查询序列长度通常仅为 1,线程组(warp)之间的分布存在显著差异。这使得编写分页注意力内核相对容易,但要实现开箱即用的最优性能却颇具挑战。编译器必须进行特定的分析和优化 ,以提升性能。

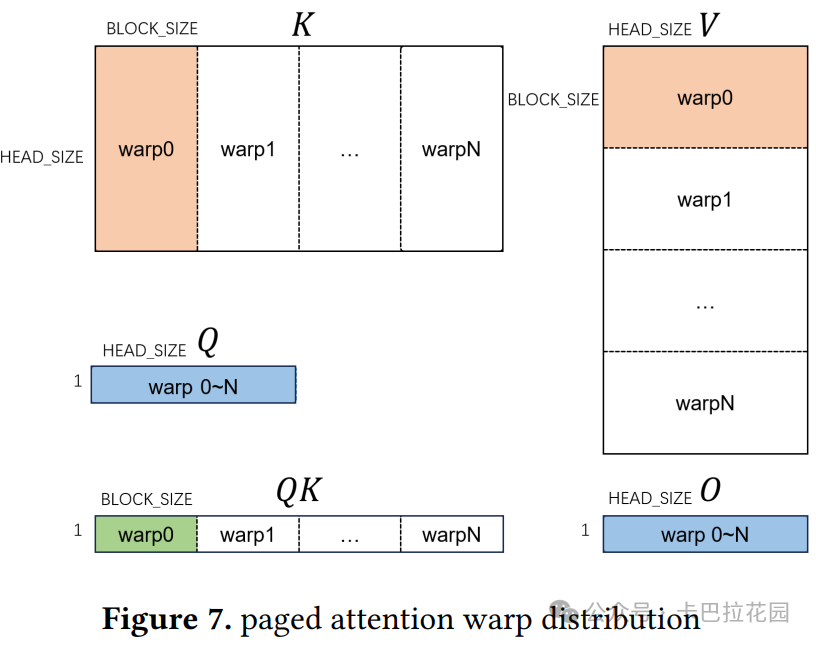
为了确保 GPU 上足够的并行性,一种方法是进一步在 Warp 之间划分 KV 缓存,如图 7 所示。每个 Warp 处理不同的 KV 缓存块,并且需要在 Warp 之间进行归约操作,以同步每个 Warp 的部分结果 。
然而,通过在 Warp 级别编程 Triton,用户可以轻松表达上述分解 。列表 7 展示了 Warp 级别内核的实现方式。

4. 实验结果与分析
实验环境与方法
研究团队在 Intel PVC max 1550 GPU 上进行实验,这是一款专为人工智能推理和训练设计的高性能图形处理器。他们使用 OneAPI 2024.1 作为开发平台,并通过 SYCL 分析事件记录内核的 GPU 执行时间 ,以评估性能表现。为了确保评估的公平性,将 Triton 与 Intel 的 XeTLA(一款针对 Intel GPU 优化的线性代数模板库,类似于 Nvidia 的 CUTLASS)进行对比,并且在两种情况下使用相同的配置参数,包括 tile 大小等,以最小化因配置差异导致的性能差异。
具体实验结果
4.1 GEMM 性能
GEMM(通用矩阵乘法)是 AI 领域中的一个基本操作,构成了大量计算工作负载。研究团队使用了 Triton 教程中的 GEMM 内核进行测试,评估了两种类型的 GEMM 操作:内存受限和计算受限 。所有矩阵形状都来自 LLama-2 和 LLama-3 等 LLM 模型 。
- 计算受限 GEMM:适用于 LLM 训练和推理,当研究人员关注单个 GPU 上的长上下文长度时,测试了从 m=1k 到 16k 的矩阵大小,足够大以充分利用 GPU 并实现峰值硬件吞吐量。结果如图 8 所示,Triton 实现了 XeTLA 性能的 96%的几何平均值 。
- 内存受限 GEMM:在 LLM 推理期间的下一个标记预测阶段很常见。在具有大 m、大 k 和大 n 的案例上进行了评估 ,以展示 Triton 的稳健性。如图 9 所示,Triton 的性能与 XeTLA 相当,几何平均值为 94%。
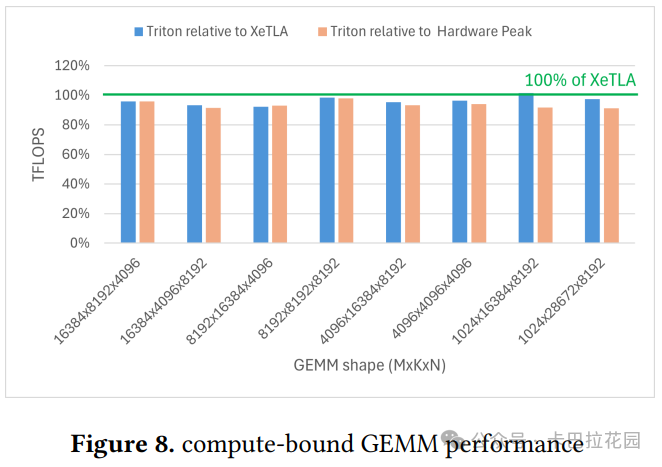
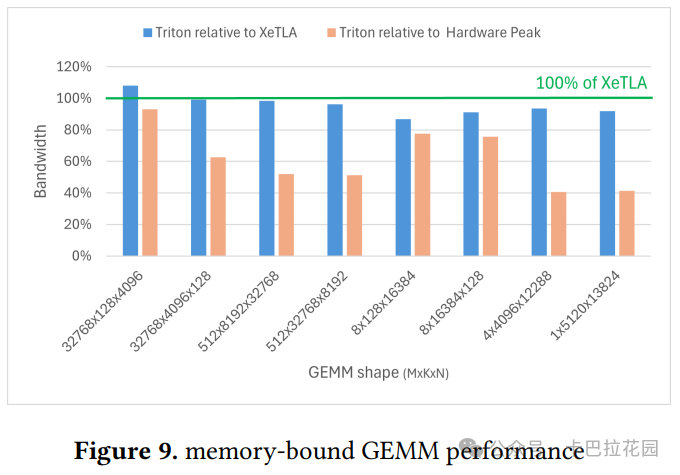
4.2 FlashAttention-2 性能
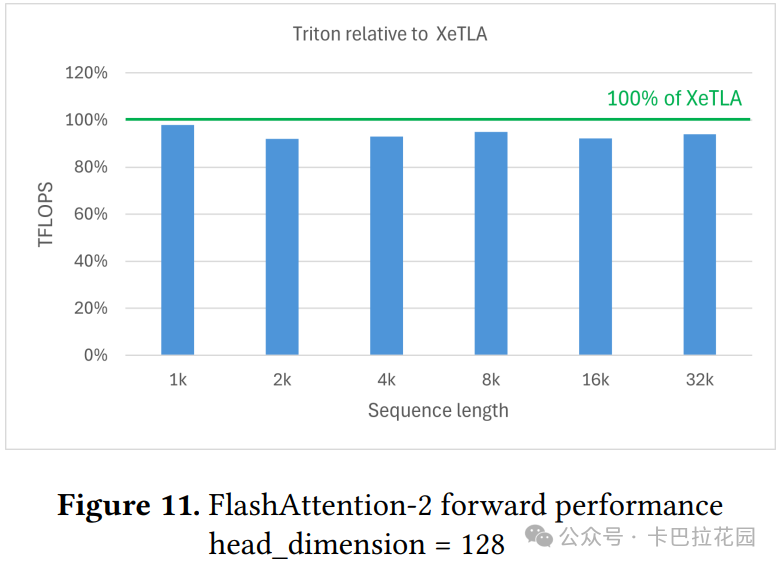
FlashAttention-2 广泛用于现代 Transformer 模型中的多头注意力(MHA)机制。研究团队使用 Triton 教程中的内核进行测试,评估了具有总共 32k 标记和 1k 到 32k 序列长度的前向传递,与大多数流行 LLM 的上下文长度对齐。隐藏维度设置为 2048,头部维度为 64 或 128(即 32 个头部或 16 个头部)。
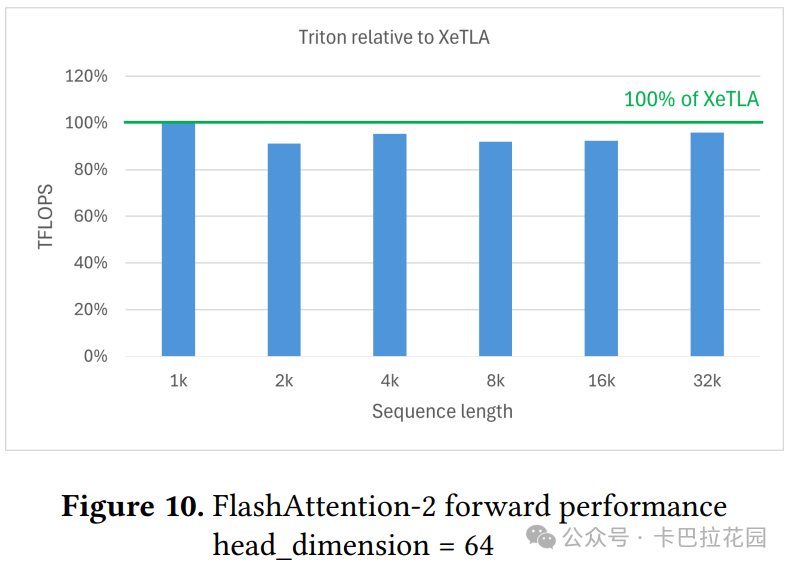
如图 10 和图 11 所示,与专家调优实现相比,ML-Triton 生成的代码性能差距小于 5%, 证明了其代码生成的高质量。
5.3 分页注意力性能
分页注意力广泛用于 LLM 推理引擎。与 FlashAttention 不同,分页注意力中的键/值对不是连续存储的 ,必须通过块表映射进行访问,这增加了内存访问的压力 。
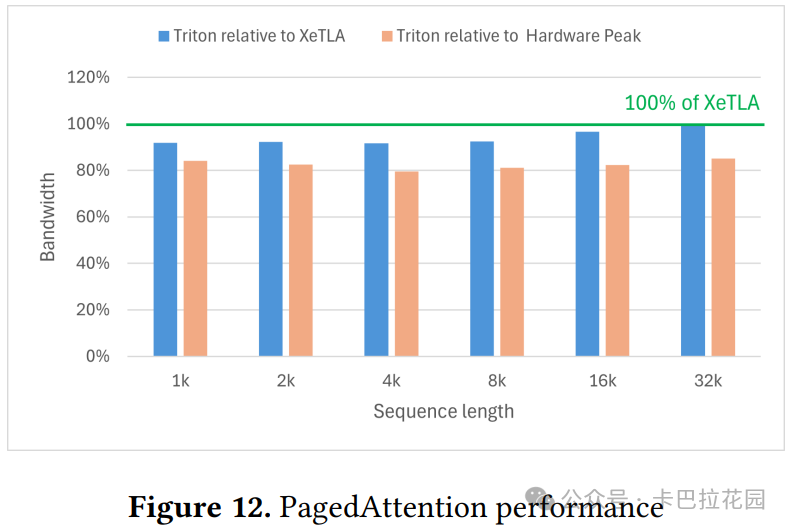
与传统的 Triton 工作组级别实现相比,ML-Triton 的 Warp 级别内核直接表达了 Warp 之间的分布 ,只需添加几行代码。如图 12 所示,Triton 的性能超过 XeTLA 的 95%,证明了其处理复杂内核的能力 。
5. 结论与未来工作
5.1 研究总结
ML-Triton 通过引入多级编译流程和语言扩展,显著提升了 GPU 编程的易用性和性能 。多级编译流程从 Workgroup 级别逐步降低到 Warp 级别和 Intrinsic 级别 ,使编译过程更加高效且具有针对性。
语言扩展部分,编译器提示 允许用户直接指导编译器如何优化关键操作,而Warp 级别 API 则赋予开发者对线程组更精细的控制能力。
实验结果表明,ML-Triton 在 GEMM、FlashAttention-2 和分页注意力等 AI 核心运算 上的性能表现优异,与专家调优的实现相比差距极小 ,充分证明了其设计的有效性和实用性。
5.2 未来展望
随着 AI 技术的飞速发展,计算需求日益增长,ML-Triton 的改进方向也逐渐明晰。首先,研究团队计划持续优化和完善 ML-Triton 的设计,以更好地适应 AI 领域不断涌现的新挑战和新需求。例如,随着模型规模的进一步扩大和计算复杂度的提升,如何在保持易用性的同时进一步挖掘硬件性能潜力,将是重要的研究课题。
其次,团队还期望将 ML-Triton 的编程和编译范式拓展至其他多核架构。现代计算硬件种类繁多,除了 GPU,还有各种专用加速器和异构处理器。将 ML-Triton 的成功经验推广到这些硬件平台 ,有望为开发者提供统一、高效的编程模型,降低跨平台开发的难度 和成本,推动整个计算行业的发展。
END
作者:intel
来源:卡拉巴花园
推荐阅读
- MobilePlantViT 破局边缘 AI | 0.69M 超轻混合 ViT 实现 99% 分类
- Paddle-MLIR:编译时间减少 20%!边缘智能设备 AI 加速的革命性突破
- 一起聊聊 Nvidia Hopper 新特性之计算切分
- 为二值神经网络扩展 NPU 二值 GEMM 核心功能单元和编译器
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

