
在神经网络研究的前沿,我们正面临着模型精度与运行效率之间的权衡挑战。尽管架构优化、层融合和模型编译等技术已取得显著进展,但这些方法往往不足以同时满足边缘设备部署所需的模型尺寸和精度要求。
研究人员通常采用三种主要策略来实现模型压缩同时保持准确性:
- 模型量化:通过降低模型权重的数值精度表示(例如将 16 位浮点数转换为 8 位整数),减少神经网络的内存占用和计算复杂度。
- 模型剪枝:识别并移除训练好的神经网络中贡献较小的神经元或权重,以简化网络架构而不显著影响性能。
- 知识蒸馏(又称教师-学生训练):训练一个更小、更高效的网络(学生模型)来复现更大、更复杂模型(教师模型)的软预测输出。软标签使学生模型获得更好的泛化能力,因为它们代表了类别相似性的高层次抽象理解,而非传统的独热编码表示。
本文将深入探讨模型量化的原理、主要量化技术类型以及如何使用 PyTorch 实现这些技术。
量化技术基础

量化是神经网络优化中最强大且实用的技术之一。它通过将模型数据(包括网络参数和激活值)从高精度浮点表示(通常为 16 位)转换为低精度表示(通常为 8 位整数),从而降低神经网络的计算和内存需求。这种转换带来多方面的优势:
- GPU 可利用更快速、更经济的 8 位计算单元(如 NVIDIA GPU 的 Tensor Cores)执行卷积和矩阵乘法运算,显著提高计算吞吐量。
- 对于受内存带宽限制的网络层,量化可显著降低数据传输需求,减少总体运行时间。这类层的运行瓶颈主要在数据读写而非计算本身,因此从带宽优化中获益最大。
- 模型内存占用的减少不仅节省存储空间,还能减小参数更新大小,提高缓存利用率。
- 数据从内存传输到计算单元的过程消耗能量。将精度从 16 位降至 8 位能使数据量减半,有效降低功耗。
将高精度数值映射至低精度表示有多种方法(如零点量化、绝对最大值量化等),本文不作深入讨论。对此感兴趣的读者可参考 Hao Wu 等人和 Amir Gholani 等人的相关技术论文。
量化方法体系

神经网络量化主要分为两种方法:
1.训练后量化 (PTQ)
PTQ 在模型完成训练后应用,无需重新训练即可将模型转换为低精度表示。该方法使用校准数据集确定最优量化参数,通过收集模型激活的统计信息并计算适当的量化参数,以最小化浮点表示和量化表示之间的差异。
PTQ 具有资源效率高、实现部署快速的优势,适用于无法重新训练的场景。然而,此类模型的准确度相对较低,需要精心校准和参数调优,因此更适合快速原型验证而非正式部署。
训练后量化可进一步细分为两种实现方式:
动态训练后量化
这种方法在推理过程中根据实时输入数据分布动态调整激活值的量化范围。
静态训练后量化
该方法引入额外的校准步骤,使用代表性数据集估计激活值范围。估计过程在完整精度下进行以最小化误差,随后将激活值缩减为低精度数据类型。
2.量化感知训练 (QAT)
QAT 是一种在模型训练过程中模拟量化效应的方法。它通过引入"伪量化"操作来模拟低精度对权重和激活值的影响。本质上模型在量化约束条件下进行训练。网络在训练期间使用直通估计器(STE)等技术计算梯度,学习适应量化引入的噪声,从而在低精度环境中保持高性能。
QAT 通常能获得更高的准确率,因为模型能在训练过程中适应量化效应,特别适用于对量化误差敏感的架构。但这也意味着需要额外的计算资源和训练时间,实现复杂度也相对较高。
量化感知训练原理
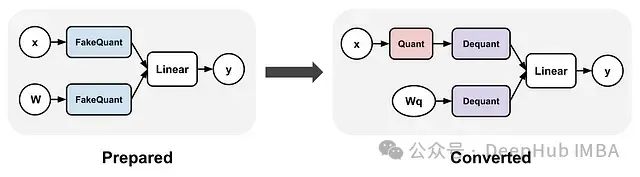
相比于 PTQ 在训练后应用量化,QAT 的优势在于它在训练期间插入"伪量化"模块。这使模型能够"感知"量化噪声并学习如何补偿这种噪声,最终得到一个量化模型,其准确率与全精度对应版本非常接近。QAT 工作流程如下:
准备阶段:用模拟量化的包装器替换网络中的敏感层(如卷积层、线性层、激活函数层)。在 PyTorch 中,这通过
prepare_qat或
prepare_qat_fx函数实现。
训练阶段:在每次前向传播中,权重和激活值都经过"伪量化"处理——即进行类似 INT8/INT4 精度的四舍五入和截断。反向传播采用 STE 技术,使梯度计算如同量化操作是恒等函数一样。
转换阶段:训练完成后,使用
convert或
convert_fx函数将伪量化模块替换为实际的量化运算核心。此时模型已准备好进行高效的
int8/int4推理。
伪量化的数学基础
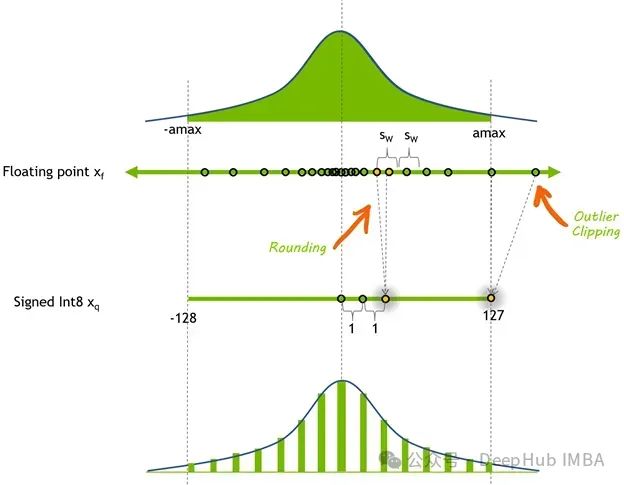
以下是量化过程的简化数学表达。
假设
x_float为实值激活。均匀仿射量化使用:
scale = (x_max – x_min) / (q_max – q_min)
zeroPt = round(q_min – x_min / scale)
x_q = clamp( round(x_float / scale) + zeroPt, q_min, q_max )
x_deq = (x_q – zeroPt) * scale在 QAT 期间,伪量化操作表示为:
x_fake = (round(x_float/scale)+zeroPt – zeroPt) * scale因此
x_fake仍然是浮点数,但被限制在与
int8张量相同的离散格点上。
梯度传播机制 — 直通估计器
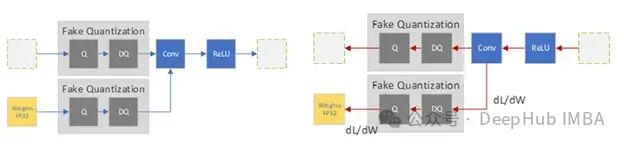
训练前向传播(L)和后向传播(R)中的 QAT 伪量化算子
由于四舍五入操作不可微分,PyTorch 采用如下近似:
dL/dx_float ≈ dL/dx_fake在反向传播中,伪量化模块被视为梯度计算的恒等函数,这使优化器能够调整上游权重以抵消量化产生的噪声。
这一过程引导网络权重自然地向整数中心靠拢,结合优化后的
scale和
zeroPt参数,最小化整体重建误差。
实践实现
PyTorch 提供三种不同的量化模式:
1.Eager 模式量化
这是一项 Beta 阶段功能。用户需要手动执行层融合并明确指定量化和反量化的位置。此外该模式仅支持模块 API 而不支持函数式 API。
以下代码示例展示了从模型定义到 QAT 准备,再到最终
int8转换的完整流程。
import os, torch, torch.nn as nn, torch.optim as optim
# 1. 使用QuantStub/DeQuantStub定义模型
class QATCNN(nn.Module):
def __init__(self):
super().__init__()
self.quant = torch.quantization.QuantStub()
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.relu1 = nn.ReLU()
self.pool = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.relu2 = nn.ReLU()
self.fc = nn.Linear(32*14*14, 10)
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.pool(self.relu1(self.conv1(x)))
x = self.relu2(self.conv2(x))
x = x.flatten(1)
x = self.fc(x)
return self.dequant(x)
# 2. QAT准备
model = QATCNN()
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
torch.quantization.prepare_qat(model, inplace=True)
# 3. 微型训练循环
opt = optim.SGD(model.parameters(), lr=1e-2)
crit = nn.CrossEntropyLoss()
for _ in range(3):
inp = torch.randn(16,1,28,28)
tgt = torch.randint(0,10,(16,))
opt.zero_grad(); crit(model(inp), tgt).backward(); opt.step()
# 4. 转换为真实的int8
model.eval()
int8_model = torch.quantization.convert(model)
# 5. 存储优势
torch.save(model.state_dict(), "fp32.pth")
torch.save(int8_model.state_dict(), "int8.pth")
mb = lambda p: os.path.getsize(p)/1e6
print(f"FP32: {mb('fp32.pth'):.2f} MB vs INT8: {mb('int8.pth'):.2f} MB")预期结果:在类 MNIST 数据上,模型尺寸约减少 4 倍,精度损失不超过 1%。
工作原理:
torch.quantization.prepare_qat函数递归地用
FakeQuantize模块包装每个符合条件的层,默认的
FBGEMMqconfig 配置选择逐张量权重观察器和逐通道激活观察器,特别适合服务器/边缘 CPU 部署场景。
2.FX 图模式量化
这是 PyTorch 中的自动化量化工作流,目前处于维护状态。它通过支持函数式 API 和自动化量化过程增强了 Eager 模式量化功能,但用户可能需要重构模型以确保兼容性。
需要注意的是,由于符号追踪的潜在限制,该方法可能不适用于任意模型结构,使用时需要熟悉
torch.fx框架。使用此方法的代码示例如下:
import torch, torchvision.models as models
from torch.ao.quantization import get_default_qat_qconfig_mapping
from torch.ao.quantization import prepare_qat_fx, convert_fx
model = models.resnet18(weights=None) # 或pretrained=True
model.train()
# 单行qconfig映射
qmap = get_default_qat_qconfig_mapping("fbgemm")
# 图重写
model_prepared = prepare_qat_fx(model, qmap)
# 微调几个周期
model_prepared.eval()
int8_resnet = convert_fx(model_prepared)FX 模式在图级别运行:
conv2d、
batch_norm和
relu等算子会自动融合,从而在 CPU 上产生更高效的计算内核和更优的延迟性能。
3.PyTorch 2 导出量化
PT2E (PyTorch 2 Export)特别适合将导出的计算图交付给 C++运行时环境。这是 PyTorch 2.1 中发布的新一代全图模式量化工作流,专为
torch.export捕获的模型设计。整个过程可通过几行代码实现:
import torch
from torch import nn
from torch._export import capture_pre_autograd_graph
from torch.ao.quantization.quantize_pt2e import (
prepare_qat_pt2e, convert_pt2e)
from torch.ao.quantization.quantizer.xnnpack_quantizer import (
XNNPACKQuantizer, get_symmetric_quantization_config)
class Tiny(nn.Module):
def __init__(self): super().__init__(); self.fc=nn.Linear(8,4)
def forward(self,x): return self.fc(x)
ex_in = (torch.randn(2,8),)
exported = torch.export.export_for_training(Tiny(), ex_in).module()
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
qat_mod = prepare_qat_pt2e(exported, quantizer)
# 微调模型...
int8_mod = convert_pt2e(qat_mod)
torch.ao.quantization.move_exported_model_to_eval(int8_mod)生成的计算图已准备好用于
torch::deploy或提前(AOT)编译到移动端推理引擎中。
4.大语言模型 Int4/Int8 混合精度演示
虽然不属于正式 API,但
torchao/
torchtune也提供了用于极致模型压缩的原型量化器:
import torch
from torchtune.models.llama3 import llama3
from torchao.quantization.prototype.qat import Int8DynActInt4WeightQATQuantizer
model = llama3(vocab_size=4096, num_layers=16,
num_heads=16, num_kv_heads=4,
embed_dim=2048, max_seq_len=2048).cuda()
qat_quant = Int8DynActInt4WeightQATQuantizer()
model = qat_quant.prepare(model).train()
# ––– 简化微调过程 –––
optim = torch.optim.AdamW(model.parameters(), 1e-4)
lossf = torch.nn.CrossEntropyLoss()
for _ in range(100):
ids = torch.randint(0,4096,(2,128)).cuda()
label = torch.randint(0,4096,(2,128)).cuda()
loss = lossf(model(ids), label)
optim.zero_grad(); loss.backward(); optim.step()
model_quant = qat_quant.convert(model)
torch.save(model_quant.state_dict(),"llama3_int4int8.pth")在这种配置下,模型激活以
int8精度运行,权重以
int4精度运行,在单个 A100 GPU 上可实现超过 2 倍的性能提升和约 60%的内存降低,同时困惑度仅增加不到 0.8 个百分点。
有关
torchao和
torchtune进行 LLM 量化的更多信息,推荐阅读 PyTorch 官方博客的相关内容。
量化实践最佳策略
为在最小化精度损失的前提下最大化模型压缩效果,应遵循以下关键策略:
首先应使用 PTQ 技术进行初步量化尝试。若 PTQ 导致的精度损失低于 2%,通常只需进行短期 QAT 微调(5-10 个周期)即可获得理想效果。执行消融分析以识别对量化敏感的网络层是非常必要的,当发现某层量化后性能显著下降时,可考虑保留其原始精度。尽早融合操作(如
Conv + BN + ReLU)能够稳定观察器量化范围并提高精度。
训练几个周期后,应当调用
torch.ao.quantization.disable_observer函数并使用
freeze_bn_stats冻结批量归一化统计数据,防止范围出现振荡。监控量化过程中的权重直方图分布(可通过
torch.ao.quantization.get_observer_state_dict()或使用Netron工具)有助于发现异常值。在 STE 近似有效工作时,较小的学习率(不超过 1e-3)可避免参数过度调整。
对于权重量化,逐通道量化方法相较于逐张量量化能将误差减半,是卷积层的推荐默认设置。如果模型准确率仍有显著下降,考虑采用混合精度策略,将首层和末层保持在
fp16精度以保证安全。最后,根据目标硬件平台选择合适的量化配置:x86 架构使用
FBGEMM,ARM 架构使用
QNNPACK/XNNPACK。
总结
神经网络模型部署需要采取全面的优化策略——构建准确的模型通常是相对容易的部分,而真正的挑战在于实现高效的大规模部署。当标准的 PTQ 方法无法满足精度要求时,QAT 技术提供了有效的解决方案。然而,成功部署量化模型需要充分考虑多方面因素,包括目标平台及其支持的操作集合。PyTorch 凭借其成熟的 QAT 工具链,为用户提供了便捷灵活的模型量化能力,适用于从简单 CNN 到拥有数十亿参数的大型语言模型等各类深度学习应用场景。
https://avoid.overfit.cn/post/c4a82be1e3a84f79912849651c4f4714

