
偏微分方程(PDE)是描述物理现象的基础数学工具。在简化几何形状的理想条件下,某些 PDE 问题可获得精确解析解。然而对于具有复杂边界和多维几何特征的实际工程问题,解析解通常难以获取或根本不存在。
传统求解 PDE 的主流方法是有限元法(FEM)。该方法将计算域离散化为网格单元,通过计算各单元间的相互作用来估算局部区域内的 PDE 残差。求解过程从初始近似解开始,通过迭代优化不断调整节点状态参数(如位置、应力、温度等物理量),直至系统收敛到稳定配置。
尽管有限元法在工程领域取得了巨大成功,但其高度依赖于网格质量和离散化精度,在处理复杂几何形状、多尺度问题或高维空间时面临计算效率和精度挑战。这些局限性促使研究人员积极探索新型求解策略,物理信息神经网络(PINN)作为一种新兴方法应运而生。
物理信息神经网络(Physics-informed Neural Networks, PINN)框架旨在构建满足初始条件和边界条件的偏微分方程近似解。该方法的核心优势在于 PDE 中的偏导数项可通过自动微分技术精确计算,这源于神经网络输出对其可调参数和输入变量天然具备可微特性。
PINN 框架的关键组成是一个特殊设计的损失函数,其中包含微分方程残差项。该残差项量化了神经网络解与 PDE 描述的物理定律之间的偏离程度。损失函数还整合了衡量初始条件和边界条件满足程度的额外项。

本研究聚焦于一维热扩散方程的求解,该方程的标准形式为:
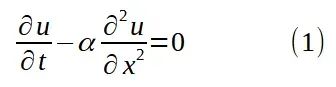
PDE 残差项定义为方程(1)左侧表达式的平方,在(x, t)域中的采样点上进行评估: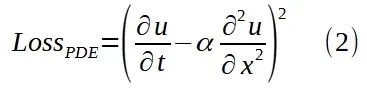
边界损失函数用于度量边界条件的约束满足程度。当温度在 x=0 和 x=L 处固定时,该损失可表示为: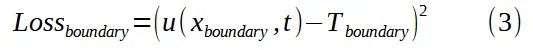
初始损失函数则衡量神经网络输出 u(x, 0)与给定初始温度分布 u₀(x)之间的偏差: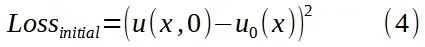
通过上述损失函数组件,我们构建了训练神经网络的完整框架。当总损失函数趋近于零时,网络解将同时满足 PDE 方程、边界条件和初始条件的约束。
值得注意的是,上述损失分量可能具有不同的量纲和数量级,这可通过适当选择权重因子来调整,但这些最优权重通常难以预先确定。在后续实验中,我们采用 λi = λb = 1 的简化设置(见图 1),以便直观展示 PINN 优化过程中的挑战。
神经网络架构设计
激活函数选择分析
首先需要明确指出,仅采用分段线性激活函数(如 ReLU 和 LeakyReLU)的网络架构不适用于本任务。这是因为分段线性激活函数的组合将产生分段线性输出函数,导致其关于输入变量的二阶导数在几乎所有点处为零,仅在线性段连接处存在不定义状态。考虑到一维热扩散方程(1)为二阶微分方程,分段线性解(其中 δ²u/δx² 为零)无法满足非线性初始条件约束,除非是线性温度函数的特殊情况。
Wang 等人(2020)提出的架构
在实验部分,我们将首先测试基本架构如多层感知器(MLP)和残差网络(ResNet)。
Wang 等人在[2]中提出的架构(以下简称 Wang2020 架构)具有更复杂的结构设计。为缓解 PINN 训练中常见的梯度流病态问题,作者设计了一种特殊架构,其中输入对的线性变换通过与前层线性变换的元素级乘法进行组合。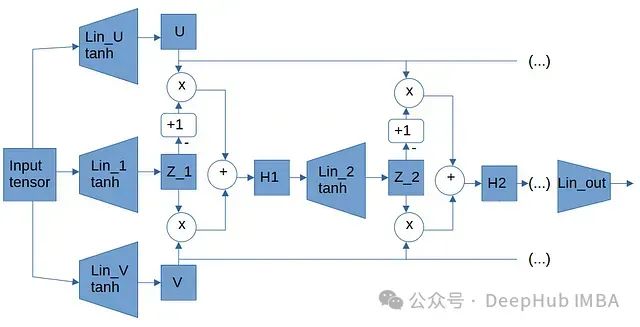
实验设计与结果分析
一维热扩散问题设置
为验证 PINN 的求解能力,我们采用一个标准的一维热扩散问题:金属细杆两端保持恒定温度,具有特定的初始温度分布(如图 3 所示)。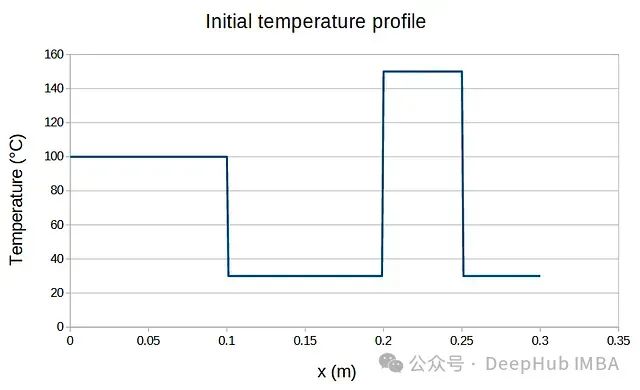
图 3:初始温度分布。
由于该问题存在解析解,我们可以将 PINN 的数值解与精确解进行直接对比,从而评估不同架构的性能表现。
多层感知器(MLP)模型训练结果
首先测试的是最基本的架构:由线性层、tanh 激活函数和输出线性层组成的多层感知器。对于包含 6 层、每层宽度为 24 的网络结构,训练损失变化如图 4 所示: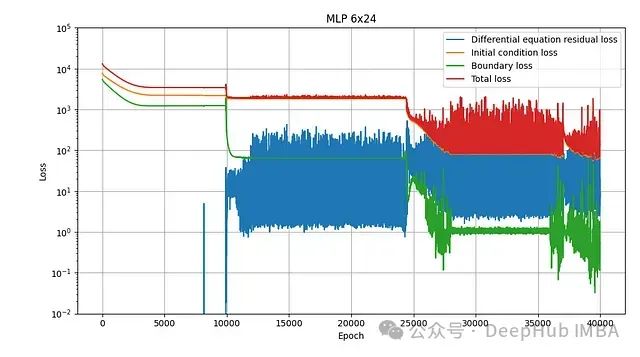
MLP 6×24 网络的训练损失曲线。
从损失曲线可以观察到,优化过程并不平稳。部分损失分量在相邻周期间可能产生数量级的波动。整个训练过程至少可以识别出三个明显阶段,优化器在每次模式突变前似乎陷入局部最小值。
图 5 展示了训练期间实现最低总损失时的网络状态所预测的温度场随时间(0 至 10 秒)的演化,并与解析解进行对比: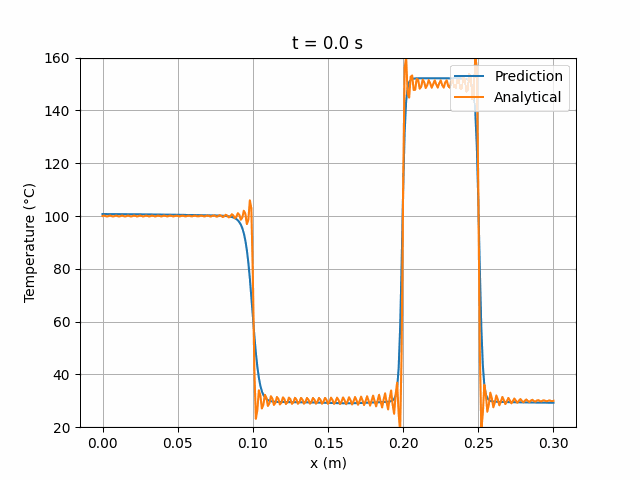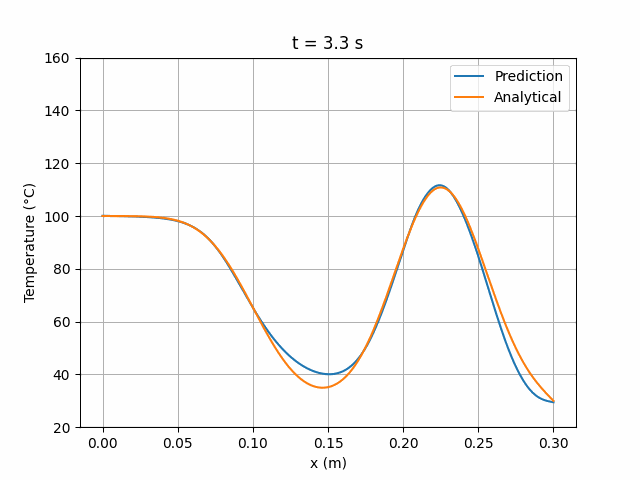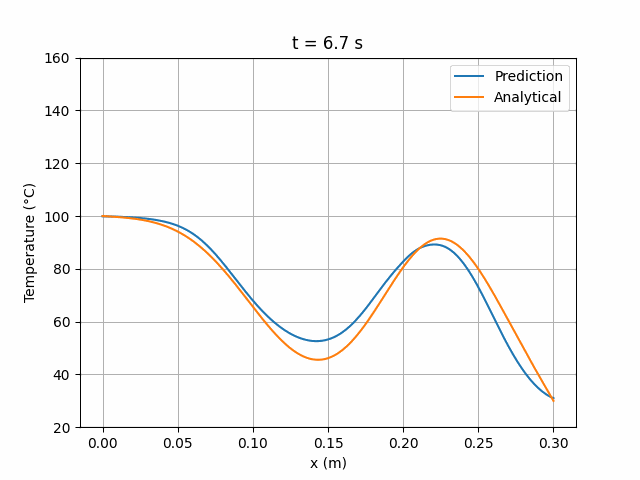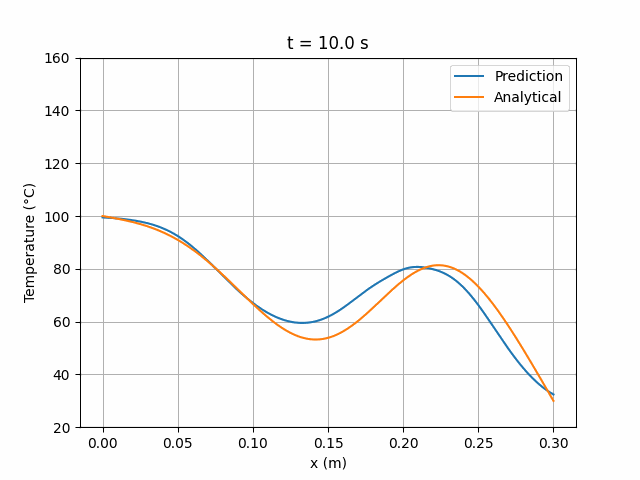
图 5:MLP 6×24 网络预测解与解析解的时间演化对比。
可以看出,预测解与解析解大致吻合,但在某些区域仍存在约 10°C 的偏差。
残差网络(ResNet)模型训练结果
第二种测试架构是残差网络,由 6 个残差块级联组成,每个残差块宽度为 24。
图 6:ResidualNet 6×24 网络的训练损失曲线。
图 6 展示的损失曲线特性与图 4 相似。模拟结果显示与解析解的偏差程度与 MLP 模型相当: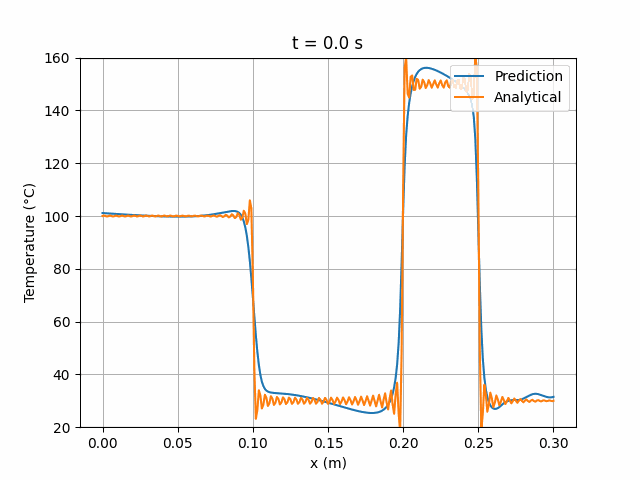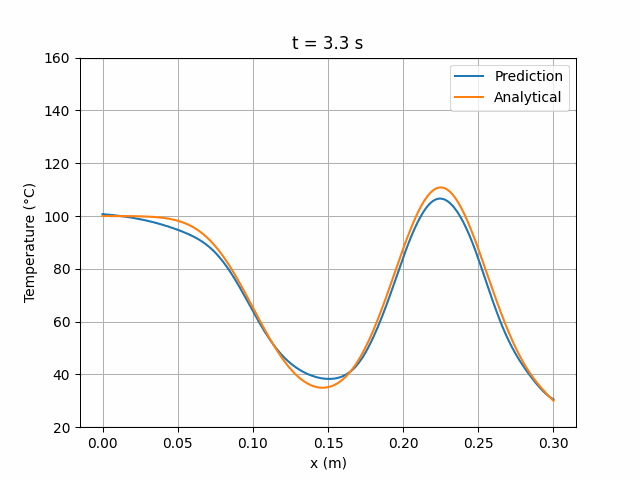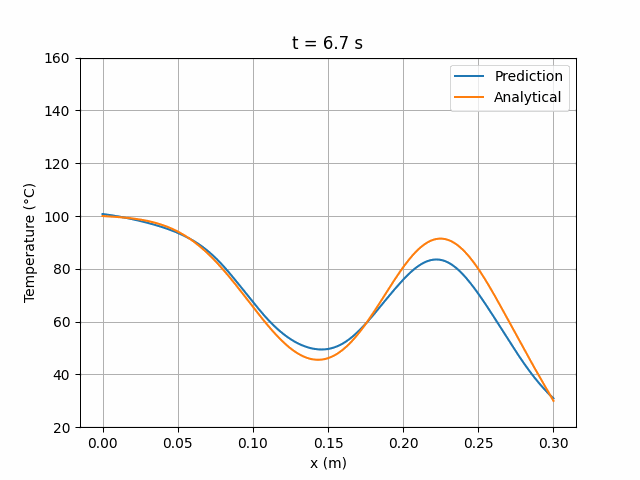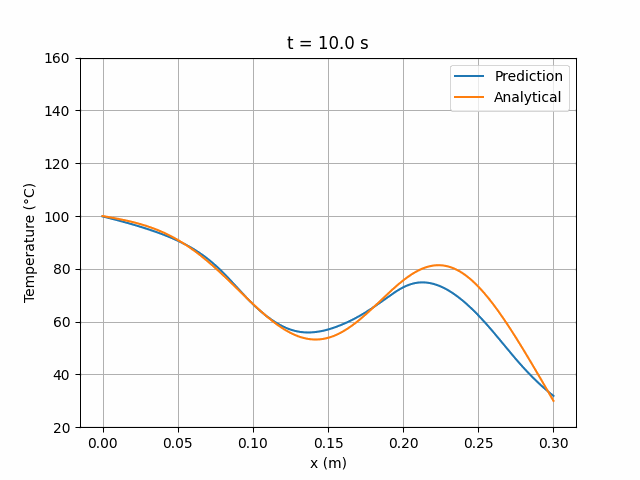
图 7:ResidualNet 6×24 网络预测解与解析解的时间演化对比。
Wang2020 架构模型训练结果
第三种测试架构是 Wang2020 网络,由 6 个宽度为 24 的 U-V 组合级联构成(参见图 2)。图 8 展示了其训练过程: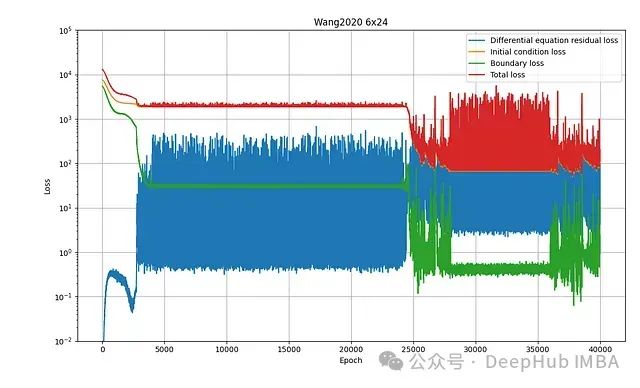
图 8:Wang2020 6×24 网络的训练损失曲线。
模拟结果显示该架构与解析解具有更高的一致性: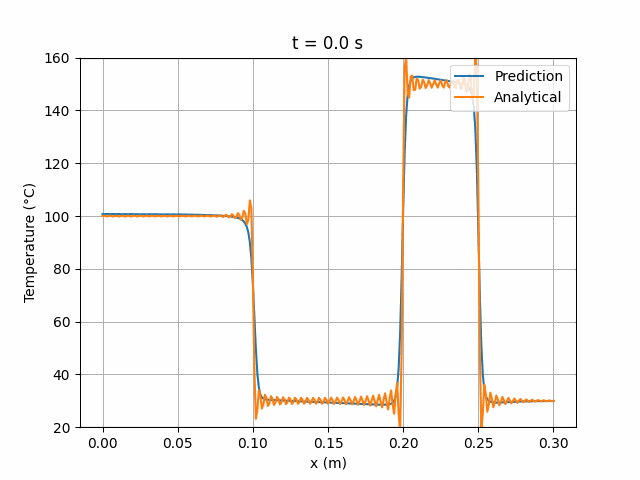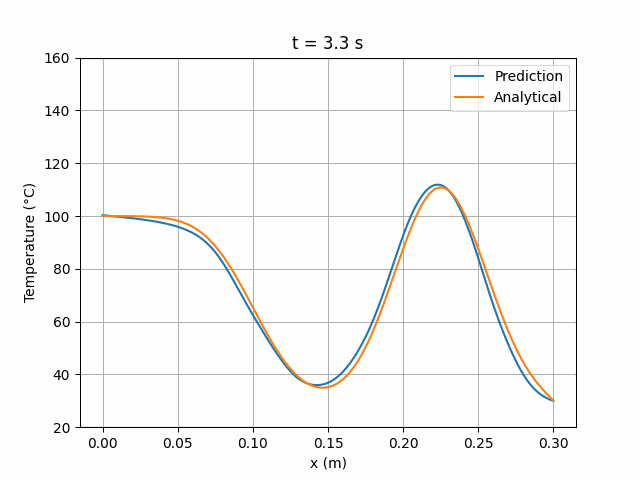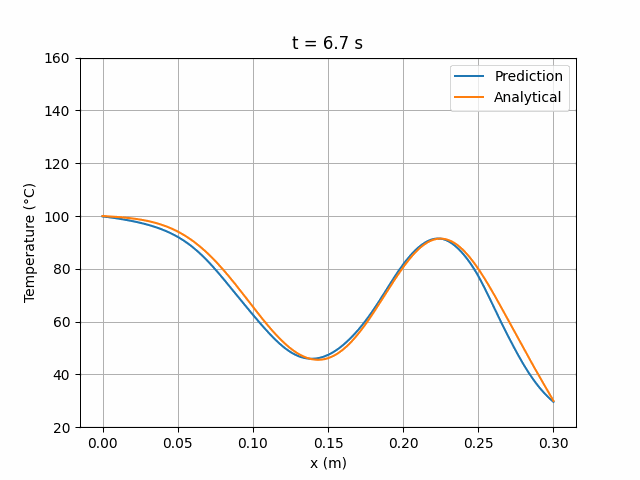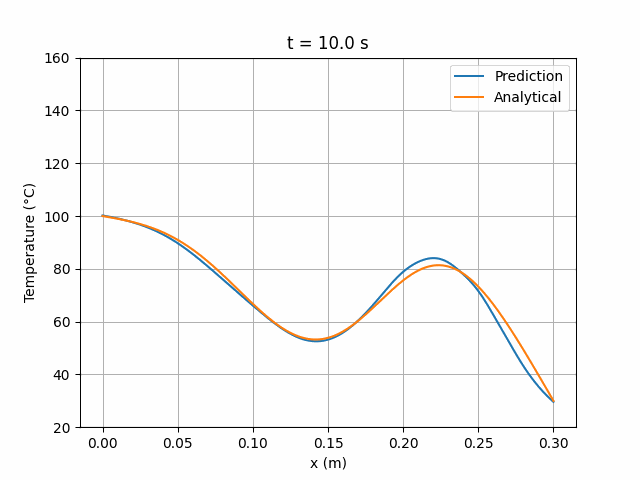
图 9:Wang2020 6×24 网络预测解与解析解的时间演化对比。
总结
本文对比了三种不同 PINN 架构在一维热扩散问题上的求解性能。从训练过程的损失曲线观察到,所有架构均表现出类似的"平台期后突变"模式,表明优化器在寻找到可适应权重空间中的新状态后实现损失的跳跃式下降。这一现象在 PINN 训练中较为普遍,可解释为优化器在多个大型局部最小值区域中的导航过程。
形成这种训练特性的可能原因是,不同损失分量的优化难度存在差异。这为优化器创造了一条"捷径",即优先最小化简单损失分量而暂时忽略其他分量,从而获得较大的梯度下降。然而,为了使解能准确模拟物理系统,所有损失分量必须同时达到最小化。
研究表明,特定架构(如 Wang2020)在应对 PINN 特有挑战方面表现更优,这得益于其针对物理信息学习的专门设计。
缓解多目标优化挑战的一种可行方法是设计一种"通过构造"满足初始条件和边界条件的 PINN 架构。在这种框架下,只需优化单一损失分量,从而避免多目标优化的复杂性。关于这一方向的更多探索有待进一步研究。
本文代码:
https://avoid.overfit.cn/post/26354859615b43f2af35addc1d0aee81
引用:
Physics Informed Deep Learning (Part I): Data-drivenSolutions of Nonlinear Partial Differential Equations (Maziar Raissi, Paris Perdikaris, and George Em Karniadakis)
https://arxiv.org/abs/1711.10561
Understanding and mitigating gradient pathologies in physics-informed neural networks (Sifan Wang, Yujun Teng, Paris Perdikaris)

