
在人工智能技术快速演进的背景下,大型语言模型的架构设计始终围绕仅解码器(decoder-only)的Transformer结构展开。自第一个GPT模型发布以来,该架构已成为主流设计范式。尽管研究人员在效率优化方面进行了诸多改进,但核心架构结构保持相对稳定。
近期大型语言模型的发展呈现出一个重要的架构演进趋势:混合专家(Mixture-of-Experts, MoE)架构在基础模型中的广泛应用。这一变化的根本驱动力在于MoE架构能够在模型质量与推理效率之间实现优于传统密集模型的性能平衡。
基于MoE架构的大型语言模型具有稀疏性特征,即模型的各个组件并非同时处于激活状态。这种设计允许模型扩展至数千亿参数规模,而在推理过程中仅激活部分参数子集。Grok和DeepSeek-v3等最新模型均采用了这一技术路径。
本文将深入分析MoE架构的技术原理,探讨其在大型语言模型中被视为未来发展方向的原因,并详细介绍该架构在当前主要模型中的具体应用实现。
MoE架构技术原理:与Transformer的差异化设计
在标准的仅解码器Transformer架构中,每个token均通过单一的前馈神经网络(FFN)进行处理。该网络通常包含两个线性层,中间插入非线性激活函数。所有token都经由同一网络进行顺序处理。
MoE系统对这一处理流程进行了关键性修改。在前馈模块内部,系统部署多个独立的网络单元而非单一网络。每个网络单元维护独立的权重参数,被称为"专家"。例如一个MoE层可能包含八个前馈网络,即八个专家单元。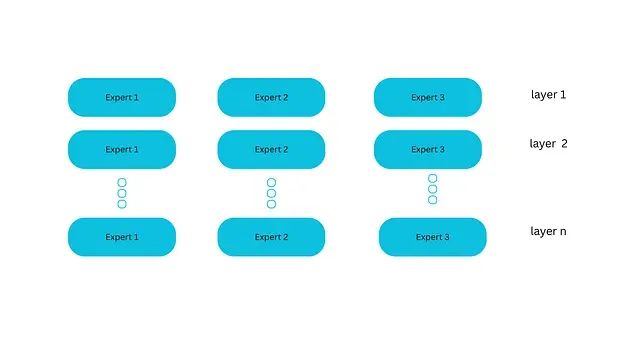
这种设计类似于专业顾问团队,每个顾问具备特定的专业技能。MoE架构的两个核心组件包括专家网络(Experts)和路由机制(Router)。专家网络是指每个FFN层现在包含一组可选择的专家单元,这些专家通常本身就是FFN结构。路由器或门控网络(gate network)负责决策哪些token分配给哪些专家处理。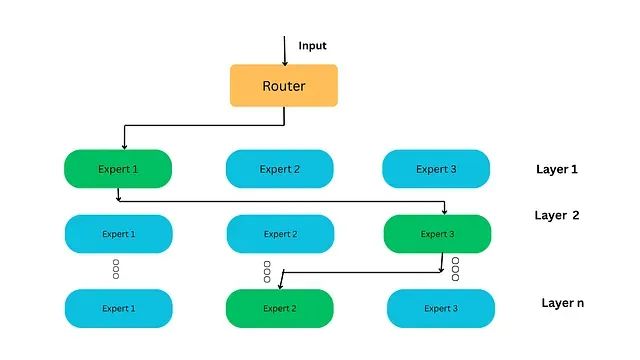
MoE Transformer的构建方法
MoE架构通过将Transformer模块中的特定前馈层替换为MoE层来实现。MoE层中的专家架构与标准前馈网络相似,但在单个MoE层中部署多个专家单元。并非所有层都需要采用MoE设计。大多数模型采用步长参数P,仅在每P层中使用专家结构。这种交错(interleaving)方法在获得专家优势的同时,避免了模型过度复杂化,实现了性能与复杂度的平衡。
根据专家使用策略的不同,MoE可分为密集MoE(Dense MoE)和稀疏MoE(Sparse MoE)两种类型。
密集MoE架构
在密集混合专家(Dense MoE)层中,所有标记为{f₁, f₂, …, fₙ}的专家网络在每次前向传播过程中都会被激活,无论输入内容如何。这种方法在早期模型中被广泛使用,并在EvoMoE和MoLE等最新研究中继续出现。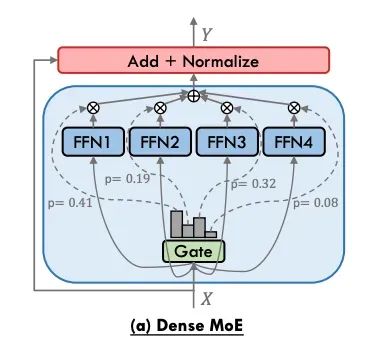
稀疏MoE架构
密集MoE虽然能够提供较高的准确性,但伴随着显著的计算开销。稀疏MoE采用不同的策略,不同时激活所有专家,而是针对每个输入选择前k个专家。这种选择性激活机制大幅降低了计算复杂度。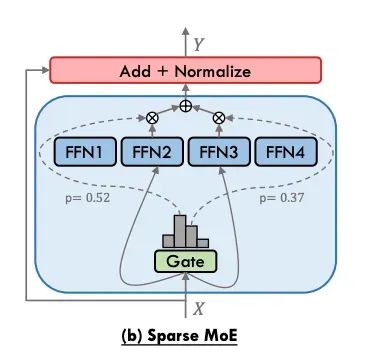
由于稀疏MoE是当前主要采用的MoE类型,本文后续内容将主要聚焦于稀疏MoE的技术实现。
专家选择与路由机制
专家选择过程基于token的d维向量表示,从N个专家中选择k个专家进行处理。具体的选择流程包括:首先对token向量进行线性变换,生成包含N个值的新向量,每个值对应一个专家;然后应用softmax函数将这些值转换为概率分布;最后根据概率值选择前k个专家。
这一策略源于首次引入稀疏MoE层的开创性研究。
TopK(k)函数保留向量中前k个最大值,将其余值设置为负无穷大(−∞)。经过softmax操作后,设置为−∞的条目接近零值。参数k是根据具体任务选择的超参数,常用值为k=1或k=2。
在稀疏MoE层的训练过程中,通常引入噪声项(R_noise)作为正则化技术。这种噪声有助于系统探索不同专家的使用模式,提高训练过程的稳定性。
基础路由方法存在专家使用不平衡的问题。随着训练进行,模型可能持续选择相同的少数专家,导致这些专家获得更多训练机会,进而在未来更容易被选中。这种现象被研究人员称为路由崩溃(routing collapse)。
原始论文对此问题的描述为:"门控网络倾向于收敛到一种状态,即它总是为相同的少数几个专家产生较大的权重。这种不平衡是自我强化的,因为受青睐的专家训练得更快,因此更容易被门控网络选中。"
辅助损失函数的平衡机制
为解决路由崩溃问题,研究人员引入了辅助损失函数(auxiliary losses function)。该机制通过添加奖励工作负载平均分配的损失项来实现专家使用的平衡。
每个专家根据其被选中的频率(路由机制分配的概率总和)获得重要性得分。在批处理过程中,将每个专家的概率进行累加。如果所有专家的得分相近,则损失较小;如果得分差异显著,则损失增加。
通过最小化方差(以变异系数的平方衡量),训练过程促使模型保持重要性得分的平衡。这种"重要性损失(importance loss)"机制帮助路由器更均匀地利用所有专家。
对于包含T个token和N个专家的批次B = {x₁, x₂, …, x_T},基于先前研究,该批次的辅助负载均衡损失计算如下: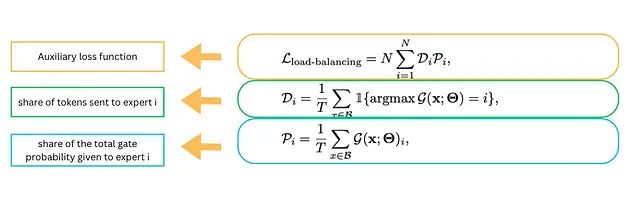
负载均衡损失包含两个组成部分:每个专家接收的路由概率分数,以及实际分配给每个专家的token分数。系统将这两个组件存储为向量,然后计算其点积。当两个组件都趋于均匀分布时,损失值最小化,从而实现重要性和实际负载的双重平衡。
MoE层中的专家容量管理
在MoE模型中,数据处理方式在不同批次间存在变化,这是由于模型在训练和推理过程中使用路由机制决定数据分配。大多数实际部署的MoE模型为每个专家采用固定的批处理大小,以充分利用硬件资源。
专家容量定义为单个专家在一个批次中能够接收的最大token数量。当路由到某个专家的token数量超过其容量限制时,溢出的token将跳过该专家的处理,通过Transformer的残差连接直接传递到下一层。
大多数实现使用容量因子(capacity factor)参数来控制专家容量。当容量因子设置为1时,token在专家间平均分配。将容量因子设置为大于1的值为模型提供处理路由不均匀情况的缓冲空间,允许专家处理超过平均水平的token数量。但是较高的容量因子会增加内存消耗并可能降低系统效率。
研究表明,MoE模型通常在较低容量因子下表现良好,但需要关注因容量限制而丢弃的token数量,过多的token丢弃会影响模型性能。实际应用中,可以为训练和评估设置不同的容量因子。例如,ST-MoE模型在训练期间使用1.25的容量因子,在评估期间使用2.0的容量因子。
MoE层输出生成机制
MoE层的最终输出计算过程包括以下步骤:路由器将每个token分配给一个或多个专家;各专家处理分配给它们的token;来自各专家的输出通过加权平均进行组合,权重由路由器对每个专家的置信度确定;对于每个token,最终结果是其所分配专家输出的加权和。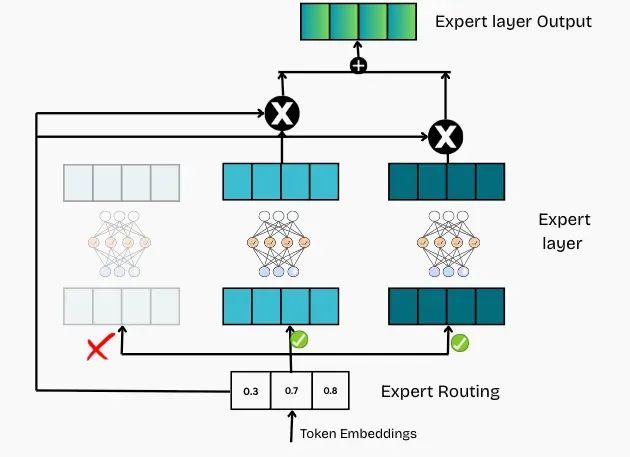
MoE研究中的一个新兴概念是同时使用共享专家(shared experts)和路由专家(routed experts)。共享专家接收所有token,而路由专家根据标准路由机制接收token。共享专家的目标是避免在多个专家间重复存储相同信息,通过集中存储通用知识来提高效率。通常,共享专家的数量少于路由专家,因为过多的共享专家会削弱模型的稀疏性和效率优势。
使用共享专家时,共享专家的输出与路由专家的输出进行简单相加,使模型能够结合通用信息(来自共享专家)和专门处理(来自路由专家)。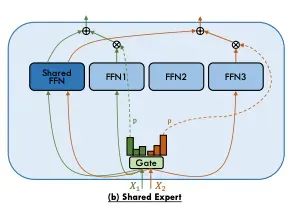
基于MoE层的仅解码器LLM整体架构
在标准仅解码器Transformer模型中,每个模块包含一个前馈网络。而在MoE架构中,通过在模块内部部署多个专家单元而非单个前馈网络来实现修改。每个专家都是原始前馈网络的独立副本。
MoE模块的所有组件,包括自注意力层、专家网络和路由机制,都通过梯度下降法进行联合训练。路由机制通过对token向量进行线性变换来决定专家分配,token通过选定的专家进行处理,专家输出被组合并传递到模型的下一层。
修改后的MoE模块结构包含以下核心组件:自注意力层、残差连接加归一化、为每个token选择专家的路由机制、包含多个独立前馈网络的专家层,以及应用于专家层输出的最终加法和归一化操作。Transformer的其他部分保持不变。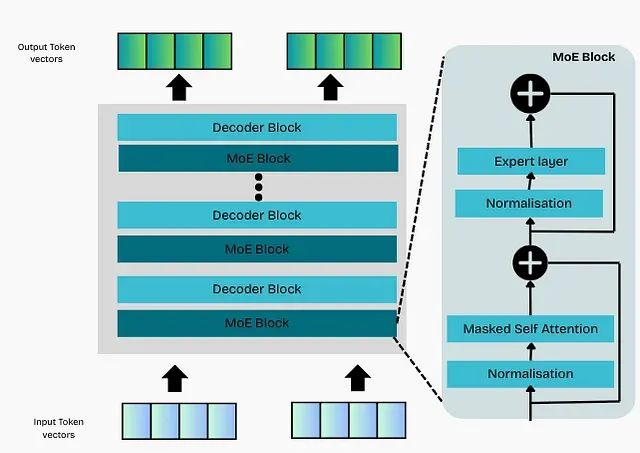
实际实现中,并非需要将每个模块都替换为MoE层。常见做法是仅修改每P个模块中的一个,其余模块保持标准结构。虽然某些模型在每一层都部署专家,但在实践中,每隔一个、三个或五个模块使用MoE层是更常见的方法。这种策略有助于控制模型的总参数数量。
MoE技术实现
(一下代码为演示,如果想查看完整的MOE代码可以搜索我们以前发布的文章)
以下展示专家网络、路由机制和稀疏MoE架构的具体实现:
# 带噪声的 top-k 门控
classNoisyTopkRouter(nn.Module):
def__init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
self.top_k=top_k
# 用于路由器 logits 的层
self.topkroute_linear=nn.Linear(n_embed, num_experts)
self.noise_linear=nn.Linear(n_embed, num_experts)
defforward(self, mh_output):
# mh_output 是多头自注意力模块的输出张量
logits=self.topkroute_linear(mh_output)
# 噪声 logits
noise_logits=self.noise_linear(mh_output)
# 向 logits 添加缩放的单位高斯噪声
noise=torch.randn_like(logits)*F.softplus(noise_logits)
noisy_logits=logits+noise
top_k_logits, indices=noisy_logits.topk(self.top_k, dim=-1)
zeros=torch.full_like(noisy_logits, float('-inf'))
sparse_logits=zeros.scatter(-1, indices, top_k_logits)
router_output=F.softmax(sparse_logits, dim=-1)
returnrouter_output, indices
# 实现来自 https://github.com/AviSoori1x/makeMoE.git
# 最后将所有内容整合起来,创建一个稀疏混合专家语言模型
classSparseMoELanguageModel(nn.Module):
def__init__(self):
super().__init__()
# 每个词元直接从查找表中读取下一个词元的 logits
self.token_embedding_table=nn.Embedding(vocab_size, n_embed)
self.position_embedding_table=nn.Embedding(block_size, n_embed)
self.blocks=nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for_inrange(n_layer)])
self.ln_f=nn.LayerNorm(n_embed) # 最终层归一化
self.lm_head=nn.Linear(n_embed, vocab_size)
defforward(self, idx, targets=None):
B, T=idx.shape
# idx 和 targets 都是 (B,T) 的整数张量
tok_emb=self.token_embedding_table(idx) # (B,T,C)
pos_emb=self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x=tok_emb+pos_emb# (B,T,C)
x=self.blocks(x) # (B,T,C)
x=self.ln_f(x) # (B,T,C)
logits=self.lm_head(x) # (B,T,vocab_size)
iftargetsisNone:
loss=None
else:
B, T, C=logits.shape
logits=logits.view(B*T, C)
targets=targets.view(B*T)
loss=F.cross_entropy(logits, targets)
returnlogits, loss
defgenerate(self, idx, max_new_tokens):
# idx 是当前上下文中索引的 (B, T) 数组
for_inrange(max_new_tokens):
# 将 idx 裁剪为最后的 block_size 个词元
idx_cond=idx[:, -block_size:]
# 获取预测结果
logits, loss=self(idx_cond)
# 仅关注最后一个时间步
logits=logits[:, -1, :] # 变为 (B, C)
# 应用 softmax 获取概率
probs=F.softmax(logits, dim=-1) # (B, C)
# 从分布中采样
idx_next=torch.multinomial(probs, num_samples=1) # (B, 1)
# 将采样到的索引附加到运行序列中
idx=torch.cat((idx, idx_next), dim=1) # (B, T+1)
returnidxMoE模型的技术优势与发展前景
高效扩展策略
传统大型语言模型通过持续增加参数规模来提升性能,但这种方法导致计算成本、能源消耗和部署成本急剧上升。MoE模型采用条件计算(conditional computation)策略,针对每个输入仅激活称为专家的特定模型部分。即使MoE模型可能拥有数万亿参数,也无需在单次推理中激活所有参数,从而显著降低训练和推理的计算开销。
根据相关研究:"MoE已成为一种有效的方法,可以在最小化计算开销的情况下大幅扩展模型容量,受到了学术界和工业界的广泛关注。"
专业化与适应性
MoE模型由多个专家组成,每个专家经过训练后在特定任务领域表现出色,如文本生成、逻辑推理或技术文档处理。这种专业化设计使MoE LLM能够在多个领域和任务中展现优异性能,特别是在多领域或多任务场景中往往超越规模相当甚至更大的密集模型。
该架构具有内在的适应性,可以为新兴领域添加新专家或对现有专家进行微调,而无需重新训练整个模型。这种灵活性对于快速适应新任务需求具有重要价值。
性能提升与容错能力
通过仅激活与给定输入最相关的专家,MoE模型实现了更快的推理速度,并在复杂多样的任务上获得更优的性能表现。这种"分而治之"的方法还增强了系统的容错能力:当某个专家性能下降或出现故障时,其他专家可以提供补偿,从而降低系统出现灾难性错误的风险。
产业应用与技术趋势
主要的技术公司已经开始大规模部署基于MoE的LLM,包括谷歌的Gemini 1.5、IBM的Granite 3.0,以及据报道OpenAI的GPT-4也采用了MoE技术。随着对更大规模、更强性能、更高效率模型需求的持续增长,这一趋势预计将继续发展。
技术挑战
尽管MoE模型具有显著优势,但也面临新的技术挑战。负载均衡与路由优化方面,确保专家得到有效利用且避免过载是一个复杂的系统工程问题。基础设施需求方面,分布式训练和推理需要在硬件资源间进行高级编排。专家冗余控制方面,防止专家间的功能重叠并确保真正的专业化分工是当前活跃的研究领域。
在专家设计、路由机制和训练稳定性方面的持续创新正在快速应对这些挑战,使MoE架构在实际部署中变得越来越实用和稳健。
MoE技术在AI产业中的应用现状
大型语言模型通常在规模扩展时表现出更优的性能,但扩展过程伴随着高昂的成本。MoE模型通过构建更大规模的模型而无需同时激活所有参数来解决这一问题。这种方法在LLM研究中获得了广泛采用,并取得了令人瞩目的成果。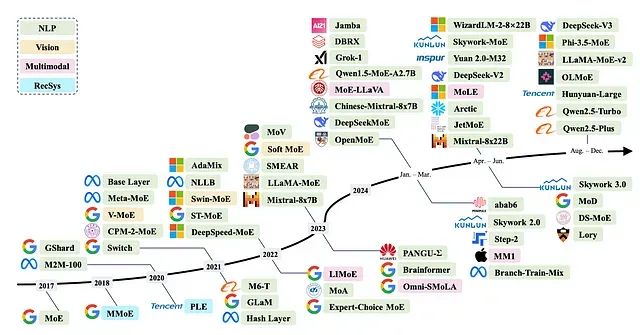
近年来几种代表性混合专家(MoE)模型的按时间顺序概述。
主要MoE模型技术对比
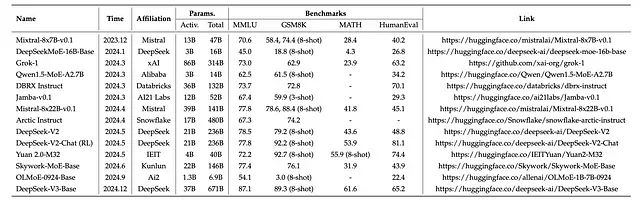
近期开源模型的集合,详细说明了激活参数和总参数数量,以及 MMLU [177] (5-shot)、GSM8K [178] (5-shot)、MATH [179] (4-shot) 和 HumanEval [180] (0-shot) 等性能基准(除非另有说明)。
由于大型语言模型在规模扩展中受益显著,MoE技术已被广泛采纳,并在LLM研究领域取得了重大突破。
Mixtral模型技术解析
Mixtral 8×7B,即Mixtral of Experts,是基于开源Mistral-7B模型开发的MoE版本。Mixtral和Mistral均在Apache 2.0许可下开源发布,并提供详细的技术报告。
Mixtral 8x7B由八个专家组成,每个专家包含70亿个参数。由于某些参数在专家间共享,模型总参数量为467亿个,而非理论上的560亿个(8×70亿)。在每一层中,针对每个token仅激活两个专家,这意味着每个token仅使用129亿个活跃参数。虽然模型总参数达到467亿,但其计算成本和推理速度与129亿参数的模型相当。
该模型支持32,000个token的上下文长度,是原始Mistral模型的四倍。在性能评估中,Mixtral在几乎所有任务领域都优于Mistral,特别是在代码生成、数学计算和多语言处理任务方面表现突出。在某些测试中,其性能甚至超越了规模更大的LLaMA-2–70B模型。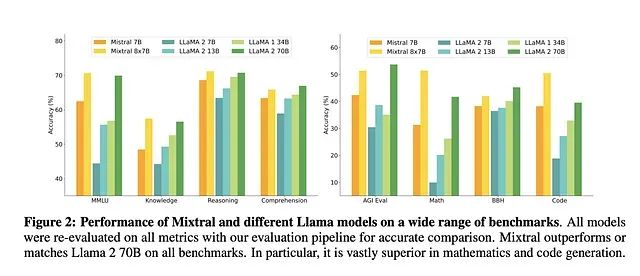
Mixtral保持了与Mistral-7B相同的基础架构(仅解码器Transformer),但引入了关键的技术改进。分组查询注意力(Grouped-Query Attention, GQA)机制通过在注意力头组间共享特定计算来提高效率。滑动窗口注意力(Sliding Window Attention, SWA)机制允许模型在固定窗口内查看token,有助于以较少计算资源处理长序列。
由于采用SWA技术,Mixtral能够利用滚动缓冲区和分块预填充等内存优化技术来加速推理并节省内存资源。在路由策略方面,Mixtral针对每个token采用简洁的方法:对来自线性层的K个最高分进行softmax处理,以确定使用的专家。
Mixtral在多语言数据集上进行训练,因此能够理解和生成多种语言的文本。在多语言基准测试中,其性能持续优于LLaMA系列模型。
研究人员对token到专家的分配模式进行了深入分析,发现并不存在明确的基于主题的分配模式。然而,确实存在某些结构性规律。例如,代码中的特定词汇(如Python中的"self")或重复性token(如缩进)通常被路由到同一个专家。这表明专家并非按主题进行专门化,但路由确实遵循基于语法或token结构的特定模式。
Grok模型技术特点
Grok是另一个基于MoE架构的大型语言模型实例。第一版Grok-1于2024年初发布,拥有3140亿个参数,但每个token仅激活约700-800亿个参数(约25%)。基础模型及其权重在Apache 2.0许可下开源,但其预训练后的微调细节未公开披露。
随后发布的Grok-1.5版本在推理能力方面有所改进,并支持更长的上下文处理。Grok-1.5在数学和编程任务上表现更优,能够处理多达128,000个token,即使在长而复杂的提示下也能良好地遵循指令。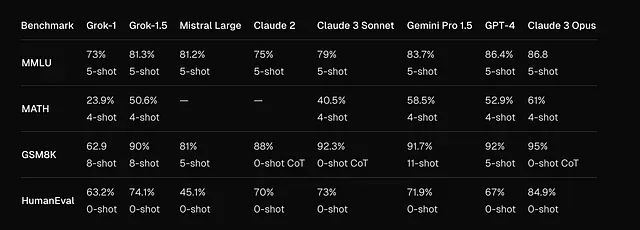
DBRX模型创新
DBRX是Mosaic开发的最新开源LLM,提供基础模型和名为DBRX Instruct的微调版本。两个版本均在Databricks开放模型许可下开源。DBRX采用以下规格的MoE架构:总参数1320亿,每次激活360亿;每个MoE层包含16个专家,每个token激活4个专家;在12万亿高质量文本token上进行预训练;预训练效率提升4倍。
DBRX采用"细粒度(fine-grained)"MoE层设计,即每层包含更多但规模更小的专家。相比之下,Mixtral和Grok-1每层使用8个专家(每个token激活2个)。DBRX的方法为每层提供了更多可能的专家组合,从而提高了模型质量。
DBRX团队特别注重数据质量优化。其预训练数据不仅规模庞大,而且经过精心筛选。这使得训练效率显著提升——使用更少的token获得更高的准确性。团队发现其数据效率是标准数据的两倍,即可以用一半的token获得相同的结果。
DBRX还采用了课程学习(curriculum learning)策略,即训练数据的组合在训练过程中动态调整,在后期更多地关注规模较小的高质量数据集。这一策略在困难基准测试中带来了显著的性能提升。
DBRX支持32,000个token的上下文窗口,使用GPT-4分词器,该分词器效率高,有助于加速训练和推理过程。在效率方面,DBRX表现突出。与类似模型相比,其MoE架构在训练期间所需的FLOPS减少约1.7倍。其他优化措施,如RoPE、GLU激活和GQA,也有所贡献。总体而言,DBRX的训练流程比以前的模型减少约4倍的计算量。推理速度同样快速——在某些测试中比LLaMA-2–70B快两倍。该模型在总参数和活跃参数方面也远小于Grok-1。
训练MoE模型面临诸如不稳定性和通信瓶颈等挑战。DBRX团队通过进行大量细致的实用改进,成功构建了稳定高效的训练流程。
在开放基准测试中,DBRX Instruct显著领先于Mixtral。其在编程方面表现强劲,甚至优于Grok-1(其规模是DBRX的两倍多)和CodeLLaMA-70B等专门模型。其在推理和数学方面也表现良好。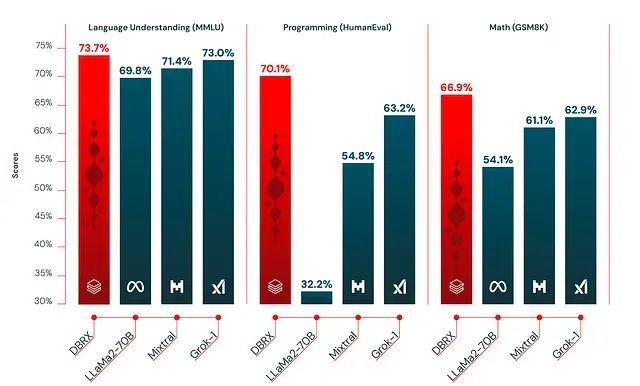
与封闭模型相比,DBRX的性能超越了GPT-3.5,并与Gemini-1.0 Pro具有竞争力。其仅在少数任务上略逊于Gemini-1.0 Pro。总体而言,DBRX在编程、数学、常识推理和信息检索方面表现强劲。
DeepSeek模型系列
DeepSeek模型系列,特别是DeepSeek-v2和DeepSeek-v3,在LLM研究社区引起了广泛关注。其卓越性能的关键因素之一是混合专家(MoE)架构的应用。这些模型向公众开放权重,创建者提供了详细的技术说明,使研究人员更容易在其基础上进行后续开发。最重要的是,这些模型在提供与顶级封闭模型相当性能的同时,实现了更低的训练成本。
DeepSeek-v2是一个拥有2360亿参数的混合专家模型,每个任务约使用210亿活跃参数。
DeepSeek-v2的重大创新是多头潜在注意力(Multi-head Latent Attention, MLA)机制。在常规Transformer中,多头注意力虽然性能强大,但会消耗大量内存。借助受MoE启发的MLA技术,DeepSeek-v2将键向量和值向量压缩成更小的"潜在"向量,仅在需要时进行扩展。通过在大多数时间仅保留较小的表示,DeepSeek-v2大幅减少了内存使用——与类似的密集模型相比减少了93%以上。如果没有MoE实现的灵活路由机制,这种效率提升是不可能实现的。
DeepSeek-v2构建其MoE层以包含许多细粒度的"专家",其中一些专家在层间共享。这种结构使每个专家都有机会专注于不同的任务,允许模型将计算资源集中在最需要的地方,从而消除冗余。
在多设备训练MoE模型时,有时会导致系统某些部分过载。DeepSeek-v2通过引入负载均衡技术来解决这一问题。这些技术使用额外的损失函数帮助模型更均匀地分配任务负载,确保每个专家和设备都得到有效利用。最终结果是更平滑的训练过程和更强的性能表现。
DeepSeek-v3在这些理念基础上进一步发展,将MoE扩展到6710亿总参数(每次激活370亿个)。该模型在近15万亿token上进行训练。这种由MoE实现的规模扩展,使DeepSeek-v3能够在不显著增加内存或计算成本的情况下提高模型容量。
MoE架构还赋予DeepSeek-v3在训练后进行调整的灵活性。例如,其上下文长度分阶段扩展,最终能够处理多达128,000个token的序列,同时保持高效性。
DeepSeek-v3保留了v2的MLA效率特性,并引入了多token预测(Multi-Token Prediction, MTP)以进一步利用MoE结构。MTP使模型能够一次处理多个未来token,而不仅仅是预测下一个token。由于这些基于MoE的技术进步,DeepSeek-v3不仅在性能上与领先的LLM相当,而且实现了经济高效的训练——没有资源浪费,没有训练不稳定性。该架构证明,通过正确的MoE设计,模型可以实现规模扩展、高效运行并取得令人瞩目的成果。
总结
人工智能技术正在快速发展,对模型智能化、高效性和实用性的需求不断提升。混合专家(MoE)模型正在推动这一发展趋势,提供了更智能的扩展策略——在实现大规模参数的同时保持高效性。
MoE模型在多个技术领域都表现出色,从科学计算到日常语言处理。由于其架构灵活性,可以在不重新开始的情况下进行更新或扩展。科技公司和开源社区已经开始广泛采用混合专家模型。
展望未来,MoE模型很可能推动新的技术突破,有助于将先进的人工智能工具普及到更广泛的用户群体,而不仅限于大型技术公司。这些模型将塑造语言模型构建和使用的未来发展方向。
https://avoid.overfit.cn/post/0ff0fcf6d65c42cfb0fa430a845553be
作者:Vivedha Elango

