本文为大家介绍一篇入选ICCV 2023的论文,《Occ2Net: Robust Image Matching Based on 3D Occupancy Estimation for Occluded Regions》,一种基于3D 占据估计的有效且稳健的带有遮挡区域的图像匹配方法。

在最近结束的 NTIRE 2023 比赛中,旷视研究院在 Efficient Super-Resolution 赛道脱颖而出,击败 40 余支队伍,夺得全球冠军。这也是旷视连续第三年在 NTIRE 的图像超分辨率赛道上夺冠。

在使用自动驾驶 3D 目标检测算法时,你是否困扰于“既想也想”的问题?既想用单模态检测器以节省传感器成本,并且加快检测速度,也想获得其它模态的知识以得到更高的检测精度。为此,旷视研究院 AI 计算组提出了统一的跨模态知识蒸馏框架——UniDistill,它克服了传统知识蒸馏框架的缺陷,不仅支持多种模态组合的蒸馏路径,...

近日,CVPR 2023 论文接收结果出炉。近年来,CVPR 的投稿数量持续增加,今年收到有效投稿 9155 篇,和 CVPR 2022 相比增加 12%,创历史新高。最终,大会收录论文 2360 篇,接收率为 25.78 %。本次,旷视研究院有 13 篇论文入选,涵盖3D 目标检测、多目标跟踪、模型压缩、知识蒸馏等多个领域。以下为入选论文简介 :
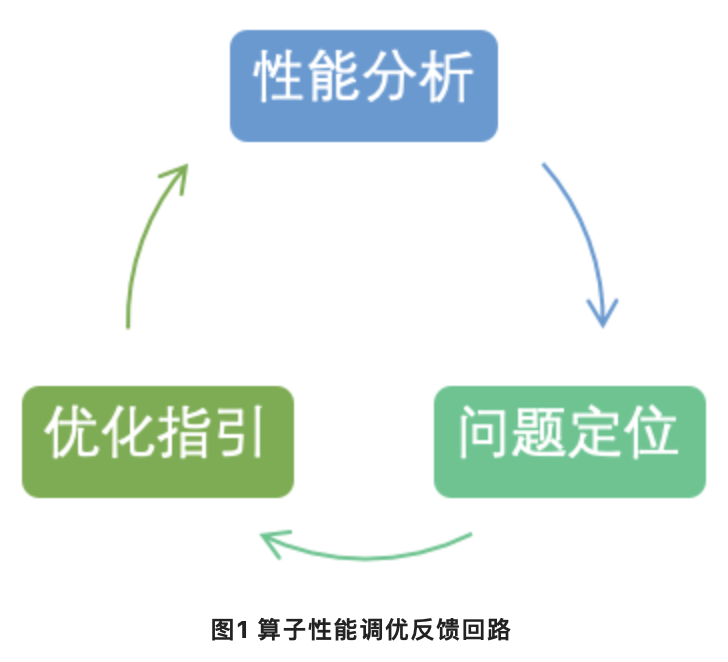
在移动/嵌入式平台,为了最大程度发挥硬件算力,对算子极致性能的追求变成必然,不同于桌面/服务器平台,移动/嵌入式平台在算子性能调优方面可选择的工具很少。
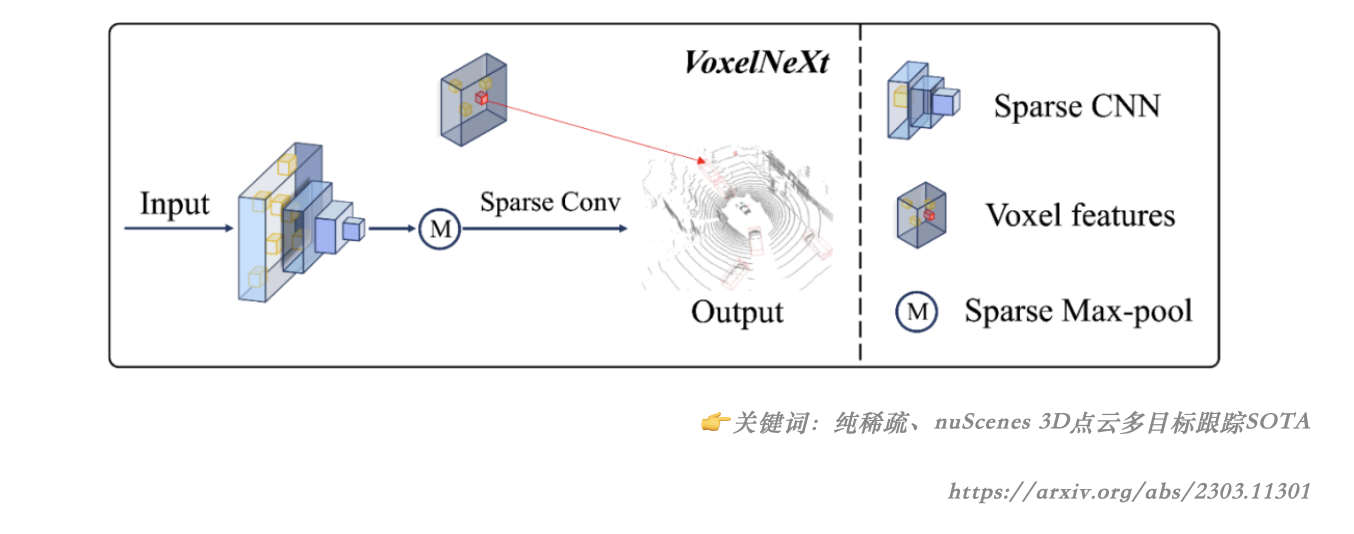
在 2022 年的 Tesla AI Day 上, Tesla 将 Bev(鸟瞰图) 感知进⼀步升级,提出了基于 Occupancy Network 的感知⽅法。这种基于 Occupancy Grid Mapping 的表示⽅法,⼜叫体素(Voxel)占据,在 3D 重建任务中已经是一个“老熟人”了。它将世界划分成为⼀系列 3D ⽹格单元,然后定义哪个单元被占⽤,哪个单元是空闲的,并且...

自 ViT 时代到来之后,由一叠 blocks 堆起来构成的基础模型已经成为了广泛遵循的基础模型设计范式,一个神经网络的宏观架构由width宽度(channel 数)和 depth 深度(block 数)来决定。有没有想过,一个神经网络未必是一叠 blocks 组成的?可能是 2 叠,4 叠,或者…16 叠?

最近,ChatGPT掀起了一场AI在大众圈的话题热潮,全民热聊中也对AI发展方向和未来发展趋势提出了很多问题,也有许多人想问以ChatGPT为代表的AIGC的兴起,对计算机视觉、AIoT的产业发展有何种启发。我们邀请了旷视研究院基础科研负责人张祥雨做客这次的对话,分享他的思考和观点。

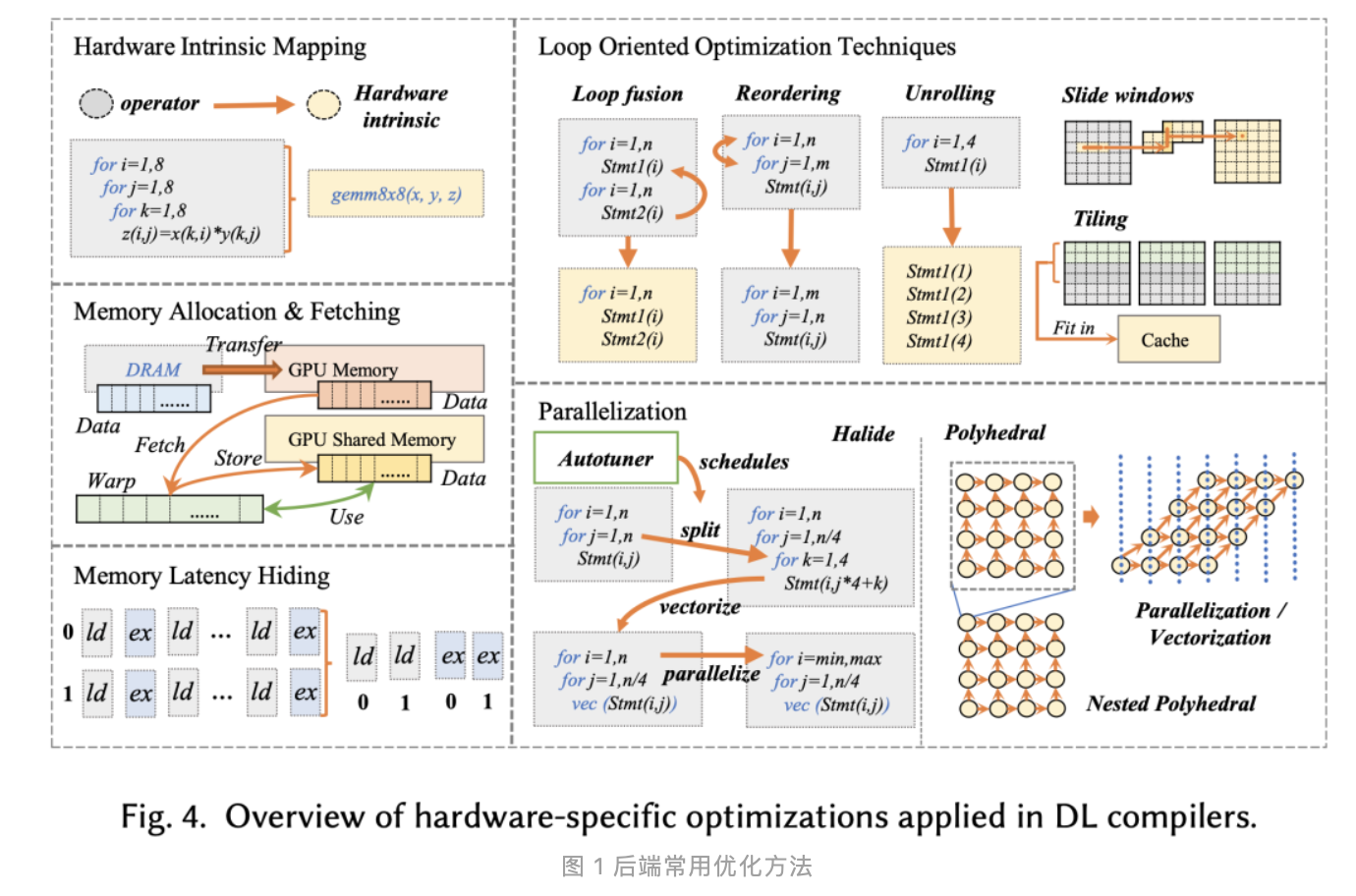
编译器本质上是一种提高开发效率的工具,将高级语言转换为低级语言(通常是二进制机器码),使得程序员不需要徒手写二进制。转换过程中,首要任务是保证正确性,同时需要进行优化以提升程序的运行效率。传统意义上的编译器的输入通常是某种高级语言,输出是可执行程序。在实际工作中接触到了深度学习编译器开发,其设计...
该 repo 提供了一些经典的检测 SOTA 模型以及相关组件,欢迎大家按需取用~~GitHub:[链接]MegStudio 使用示例:[链接]本篇整理自知乎《BaseDet: 走过开发的弯路》作者:王枫 | 旷视算法研究员 @Fatescript

近日,国际人工智能顶级会议 AAAI 2023 (Association for the Advancement of Artificial Intelligence)公布了录用结果。本届会议共收到来自全球的 8777 篇论文投稿,其中 1721 篇论文被录用,论文录用率为 19.6%。
目前社区中存在着不少个移动端深度学习推理框架(比如NCNN、MNN),它们为社区用户在移动端部署深度学习提供了相当多的便利,但是这些推理框架有一个共性问题:随着不断迭代以及性能优化,运行时库会逐渐增大,尤其是不同算子 fuse 时,会导致大量长尾算子,使 App 或 SDK 体积变得尾大不掉。

多目标跟踪和分割任务是指在视频中定位和关联感兴趣的目标,是视频内容理解和人机交互等许多应用中的基础技术。现有的计算机视觉系统在简单场景中取得了良好的跟踪和分割性能,但是在复杂环境中表现一般。

图像恢复任务,是指将受损(如带噪声/模糊)的图像恢复为清晰图像。这在日常生活中广泛出现,如手机拍摄的照片通常需要经过图像恢复算法对其进行去噪/去模糊等一系列处理之后,再显示给用户。

近年来,基于深度学习的图像降噪/去模糊的算法,在图像恢复领域取得了显著的进展。但与此同时,这些方法的系统复杂度相应的也在上升,如图1. 所示。

本文提出了一种基于实时中间流估计的视频插帧算法 RIFE,包括一个端到端的高效的中间流估计网络 IFNet,以及基于特权蒸馏的光流监督框架。RIFE 支持在两帧之间的任意时刻点插帧,在多个数据集上达到了最先进的性能且不依赖于任何的预训练模型。

「沈向洋带你读论文」CV系列专栏,本次邀请到旷视研究院基础模型组的负责人张祥雨,为大家讲解论文Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs,重新审视CNN中大卷积核问题。

论文地址:[链接]开源代码:[链接]Introduction近年来, 基于深度学习的光流算法实现了很高的性能和运算效率。实现这些深度学习方法的一个关键因素是其训练数据集。我们认为, 光流的数据集应具有以下四个关键特性: 1) 有标签数据对的数量多; 2) 光流标签的准确性高; 3) 图像的真实性高;4) 运动的真实性高。然而, 我们发现...

随着深度学习的发展,其应用场景也越发的广泛与多样。这些多样化的场景往往会对实际的部署提出更加“定制化”的限制。例如,自动驾驶汽车对人体识别的精度要求肯定比图像识别动物分类的精度要求更加严苛,因为二者的应用场景和错误预测带来的后果截然不同。这些“定制化”带来的差异,对于实际部署的模型在精度、速度、空间...

自监督学习由于可以从未标注的数据中学习到任务无关的通用表征[10], 成为近些年深度学习领域一个研究热点。特别是一系列基于对比学习工作的出现[3, 4, 6, 7], 使得自监督预训练模型在下游任务的表现与有监督学习之间的差异日益减小, 甚至实现超越。这些下游训练的模型经常要被部署到不同资源限制的设备(e.g. 服务器, 手...



