
该文是原SID团队(UIUC+HKUST+Intel)在SID基础上提出的一种适用于暗光视频的方法。
深度学习已在极限低光成像领域取得了难以置信的效果。尽管在图像处理领域取得了成功,但在极限低光视频处理领域仍极为棘手(这是由于raw数据采集的难度)。按照SID中的方式收集长曝光视频GT是不可行的。
作者提出一种低光(低于1lux)raw视频处理方法。为支持该方向的工作进展,作者收集了一个低光raw视频数据集。这个层面的数据具有非常低的信噪比(以dB度量时甚至为负),传统的图像处理框架基本难以处理。通过精心的设计网络架构并引入一种新的损失(促进时序稳定性),作者在静态raw视频上训练了一个孪生网络。作者通过实验验证了所提方法优于其他burst processing、逐帧以及盲运动一致性方法。首发知乎:https://zhuanlan.zhihu.com/p/81912061
文章作者: Happy
相关链接:http://vladlen.info/papers/DRV.pdf https://github.com/cchen156/Seeing-Motion-in-the-Dark
Abstract
低光视频(如月光下广场舞、烛光晚餐下的亲密交流、夜间动画觅食等)增强尚未得到更多的研究,难度有两点:(1)raw视频训练数据的难以获取;(2)时序一致性问题。
为更好研究该问题,作者构建了一个raw低光视频数据(202静态raw视频)并提出一种深度孪生网络与特殊损失函数(促进时序稳定性)。作者认为:静态视频训练的网络可以很好的拓展到动态场景。最后作者海通实验验证了所提方案的有效性。
Method
Dark Raw Video Dataset
由于有限的数据问题,raw视频处理很少被进行研究。为弥补该空白,作者构建了一个新的DRV数据集。它采用Sony RX100 VI相机采集(该相机可以以16-18fps采集raw图像序列,大概可以缓存110帧,这大概等价于5.5s@20fps数据)。Bayer图像的分辨率为$3672 \times 5496$。该视频包含室内与室外场景。
raw视频处理的另一个挑战在于:难以收集低光无噪视频。SID中采集低曝光和长曝光图像的数据采集方式并不适合于raw视频。作者采集两个视频集:一个包含长曝光GT的静态视频,一个不包含长曝光GT的动态视频。下图给出了所构建数据样例,供参考。

作者采用三脚架以及APP遥控采集静态视频以确保短曝光和长曝光视频的完没对齐,共计包含202个视频,其中64%用于训练,12%用于验证,24用于测试。另外,作者还收集了另外一个动态视频序列,视频序列中的运动源自场景运动、相机抖动或者共存。该动态视频序列无长曝光GT,仅用于感知评估。
作者还分析了DRV数据的噪声分布,并将其与合成数据的噪声模型进行对比。在合成数据中,其噪声模型分布为:
其中,




Raw Video Processing Pipeline
raw图像/视频处理包含完整的图像处理流程,已有论文表明:精心设计的raw图像处理系统可以改进原有网络结构而无需更改网路架构与损失函数。作者认为以下准则对于低光raw视频处理系统很有必要:
- 以raw数据为起始点(14bit的raw数据);
- 模拟图像处理流程,避免多步优化时的误差累积问题;
- 同时考虑时序与空间噪声;
- 泛化性能;
- 时序一致性。
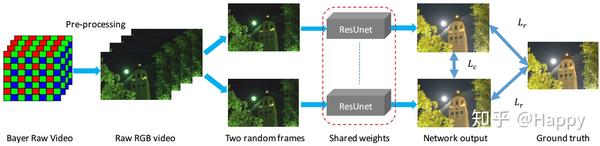
为对标上述需求,作者采用深度网络设计了一种新的流程以处理低光视频。上图给出了作者所涉及的框架。它包含以下几个步骤:
- 首先,对raw视频数据进行预处理,该过程包含bayer2rawRGB、black level subtraction, binning以及全局数字增益;
- 然后,预处理rawRGB数据被送入到深度网络中得到最终期望的RGB输出。在测试过程中,该网络以单帧作为输入;在训练时,随机输入两者到孪生网络中并统计如下两个损失:(1)重建损失;(2)自一致性损失。他们分别定义如下:

其中, 

Experiments
在训练过程中,作者采用完整图像而非块作为输入(全局统计一致性),硬件设备为Tesla V100 GPU(32G),优化器为Adam,学习率为0.0001,经500epoch后西江为0.00001,共计训练1000epoch。
真实的图像处理流程是商业秘密,因此,作者采用了Rawpy进行模拟。长曝光raw视频经由Rawpy(调用raw数据中的元数据)得到sRGB作为GT。
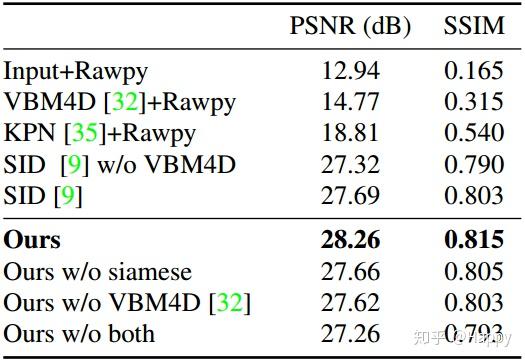
对于SID与SMD,采用预处理的raw数据作为输入,而无需元数据,直接输出RGB;作为对比,作者还训练了一个KPN用于时序和空域降噪,去噪结果采用Rawpy处理得到RGB输出。下面给出了不同处理流程的效果对比。其他更多实验结果与分析详见原文。

Conclusion
作者构建一个新的数据集与一种新的方法用于处理低光视频。作者提出一种孪生网络用于保持色彩同时抑制时序与空域噪声。该模型采用静态视频进行训练但其可泛化到动态视频中。最后作者通过实验验证了所提方法的性能。
代码
作者有提供相关代码,只是简简单单的UNet+跳过连接架构,极为简单,故而这里不再赘述,感兴趣者请查看作者提供的code。
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

