
DeblurGAN是乌克兰天主教大学的Orest Kupyn等人提出的一种基于GAN方法进行盲运动模糊移除的方法。
受启发于SRGAN与CGAN的成功,将图像模糊移除视为一种特殊的Image2Image任务,DeblurGAN基于wGAN以及内容损失进行训练学习,在SSIM与视觉效果方面,它取得了SOTA性能。
首发知乎:https://zhuanlan.zhihu.com/p/81911266
文章作者: Happy
相关链接:https://arxiv.org/abs/1711.07064 https://github.com/KupynOrest/DeblurGAN
Abstract
受SRGAN以及CGAN启发,DeblurGAN基于WGAN以及内容损失进行训练学习。它的贡献主要包含以下三点:
- 提出一种损失与框架,它在运动模糊移除方面取得了SOTA性能;
- 提出一种基于随机轨迹的动模糊数据制作方法;
- 构建一个新的数据集与评价方法(基于目标检测结果提升)。
Method
盲去模糊的目标是:在没有关于模糊核信息的前提下,给定模糊图像 ,复原清晰图像 。DeblurGAN采用生成器进行去模糊,在训练过程中引入辨别网络通过对抗方式进行训练学习。
生成器

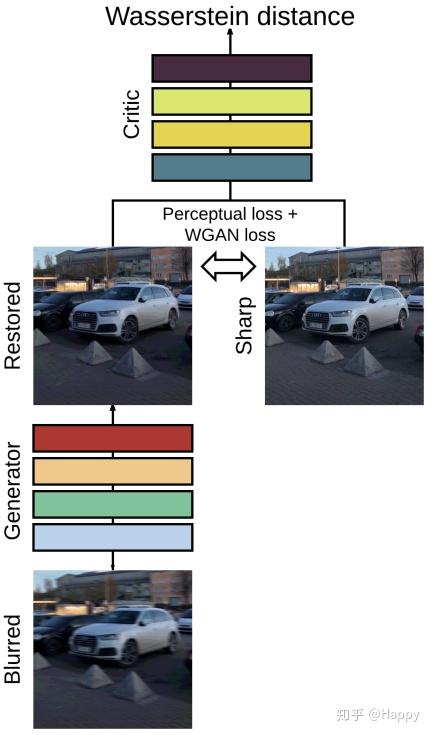
上图给出了生成器的架构示意图。它包含两个下采样卷积模块、9个残差模块(包含一个卷积、IN以及ReLU)以及两个上采样转置卷积模块,同时还引入全局残差连接。因此,该架构可以描述为:
除了上述生成器外,在训练过程中,还定义了一个判别器(该判别器架构类似于PatchGAN),采用带梯度惩罚项的Wasserstein GAN进行对抗训练。
损失函数
由于选则了GAN以及内容进行训练,因而它的损失函数包含两个部分,定义如下:

在实验中,
关于对抗损失,作者在论文中提到,WGAN-GP对于生成器更为鲁棒(作者尝试了多种架构证实了这点发现)。对抗损失定义为:

作者提到:不采用GAN训练的网络生成器得到的结果比较平滑且模糊。
关于内容损失,有两种可供选择:像素级的L1与L2损失。但是这两种损失函数均会导致最终生成的模型结果比较平滑或存在伪影。因而,作者选择了感知损失,特征空间的L2损失。定义如下:

另外,作者还提供了曾尝试添加TV正则项进行训练,但所得结果反而变差。下图给出了简单的损失函数计算示意图。
随机轨迹方法

上图给出了论文所提的基于随机轨迹的模糊数据制作方法。简单描述如下:
- 采用马尔科夫过程生成随机轨迹,下一位置点基于前一点随机生成;
- 两个随机点之间的轨迹通过亚像素插值方式生成;
- 基于得到的随机轨迹核,将其应用于清晰图像即可得到模糊图像。
Experiments
作者训练了三个模型,分别是基于GoPro数据的模型,基于所提模糊数据制作方法的模型以及基于混合数据(2:1)的模型。
在训练过程中,采用Adam优化器,学习率为$10^{-4}$,前150循环学习率保持不变,后150循环学习率线性下降到0,BatchSize=1。
下图给出了所提方法与其他方法在测试数据集(Kohler)的效果对比。

下图给出了去模糊后图像采用YOLO进行目标检测时的效果以及性能对比。作者认为:就辅助YOLO目标检测任务而言,其方法明显优于其他去模糊方法。

小结
作者提出一种盲去模糊方法,它采用GAN与内容损失进行训练;除此之外,作者还提出一种随机轨迹模糊数据制作方法;最后,作者引入一种新的评价基准:辅助提升其他任务在模糊图像上的性能(如目标检测)。
参考代码
class ResBlock(nn.Module):
def __init__(self, inc):
super(ResBlock, self).__init__()
block = [nn.Conv2d(inc, inc, 3, 1, 1, bias=False),
nn.InstanceNorm2d(inc),
nn.ReLU()]
self.net = nn.Sequential(*block)
def forward(self, x):
return x + self.net(x)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# n64
model = [nn.Conv2d(3, 64, 7, 1, 3),
nn.InstanceNorm2d(64),
nn.ReLU(True)]
# n128s2 + n256s2
model += [nn.Conv2d(64, 128, 3, 2, 1, bias=False),
nn.InstanceNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 256, 3, 2, 1, bias=False),
nn.InstanceNorm2d(256),
nn.ReLU()]
# 9 resblocks
for _ in range(9):
model += [ResBlock(256)]
# n128s2 + n64s2
model += [nn.ConvTranspose2d(256, 128, 3, 2, 1, output_padding=1, bias=False),
nn.InstanceNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, 3, 2, 1, output_padding=1, bias=False),
nn.InstanceNorm2d(64)
nn.ReLU()]
# n64
model += [nn.Conv2d(64, 3, 7, 1, 3),
nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, x):
out = x + self.model(x)
out = torch.clamp(out, -1, 1)
return out
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

