
DeblurGANv2是乌克兰天主教大学的Orest Kupyn等人提出的一种基于GAN方法进行盲运动模糊移除的方法。它在第一版DeblurGAN基础上进行改进而来,通过引入Feature Pyramid Network与轻量型backbone等使得DeblurGANv2取得更快、更优的性能。
作者首次将FPN引入到去模糊中作为生成器的核心模块。FPN可以与大量的backbone协作,可以轻松的在性能与效率方面取得均衡。FPN-Inception-ResNet-v2集成取得了SOTA性能,而FPN-MobileNet系列取得10-100倍的速度提升同时具有媲美其他SOTA方法的性能,可以达到实时性需求。除了在去模糊领域,DeblurGANv2取得了SOTA性能,它同时适用于其他图像复原任务。首发知乎:https://zhuanlan.zhihu.com/p/81911679
文章作者: Happy
相关链接:https://arxiv.org/abs/1908.03826 https://github.com/TAMU-VITA/DeblurGANv2
Abstract
作者将FPN架构引入到去模糊问题中,同时采用了不同的backbone进行网络设计,配合GAN以及内容损失的训练学习,DeblurGANv2取得了更快更优的性能。论文的创新点包含:
- 框架层面。作者构建了一个基于FPN的去模糊框架,判别器方面选用了relativistic形式并配以最小二成损失,在全局与局部两个尺度方面进行度量;
- 骨干层面。在上述框架基础下,骨干网络的选择直接影响最终的去模糊质量与效率。在追求更高质量时可以考虑选用Inception-Resnet-v2骨干网络;在追求更快速度时可以考虑选用轻量型网络,如MobileNet系列。
- 实验层面。作者在三个流程基准数据集上进行了充分的实验对比,DeblurGANv2均取得了SOTA性能;同时作者也表明该框架同样适用于更广义的图像复原任务。
Method
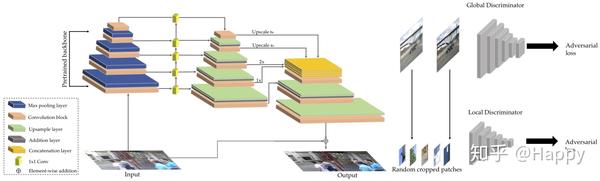
上图给出了DeblurGANv2的架构示意图。下面将从不同的方面对其进行简单的介绍。
FPN
现有的图像复原任务往往采用类ResNet架构,或者采用多尺度输入方式进行图像去模糊。然而,多尺度方式较为耗时且占用过多内存。作者将目标检测中的FPN引入到图像去模糊应用中。
作者所设计的FPN包含5个尺度的特征输出,这些特征被上采样到原始输入四分之一大小并拼接作为一个整体(它包含多尺度信息),后接两个上采样模块以复原到原始图像大小并减少伪影。类似DeblurGAN,它同样引入了全局残差连接。输入图像归一化到[-1, 1],在输出部分添加tanh激活以确保生成图像的动态范围。FPN除具有多尺度特征汇聚功能外,它还在精度与效率之间取得均衡。
Backbone
该FPN框架支持多种backbone选择,基于该即插即用属于,可以根据性能与效率需求设计各式各样的网络架构。作者默认采用基于ImageNet预训练(包含更多语义相关特征)的模型的骨干网络。以Inception-ResNet-v2作为骨干网络追求更高的性能,其他如SE-ResNeXt同样有效。
为追求更高效以切合终端设备应用,作者选择将MobileNetv2及其变种作为骨干网络,这两个网络命名为:FPN-MobileNet,FPN-MobileNet-DSC。
除了上述提到的骨干网络外,其他相关骨干网络均可作为该架构的选择。
双尺度判别器
不同于DeblurGAN选择了WGAN-GP,作者在LSGAN基础上适配了relativistic,该RaGAN-LS损失定义如下所示。相比WGAN-GP,它可以使得训练更快、更稳定,同时生成的结果具有更高的感知质量、更优的锐利度。

作者提到:对于高度非均匀模糊图像,尤其是包含复杂目标运动的图像,全局尺度有助于判别器集成全空间上下文信息。为充分利用全局与局部特征,作者提出了采用双尺度判别器进行训练(它使得DeblurGANv2可以处理更大更复杂的真实模糊)。
最终,作者构建的损失函数定义如下:

Experiments
在实验过程中,采用了GoPro、DVD以及NFS三个数据。在制作数据时,将原始240fps视频通过视频插帧方法变为3840fps视频,然后再同一时间窗下采用均值池化方式制作模糊数据。这种方式可以产生更为平滑而连续的模糊(可参考下图ac为无插帧模糊,bd为插帧模糊)。

在训练过程中,相关训练参数配置如同DeblurGAN,但前三个epoch过程中固化骨干网络参数,大概花费5天时间得到收敛。下图给出了在GoPro测试集上的性能对比。

上表中数据看出:DeblurGANv2取得了SOTA性能。SRN在PSNR指标上稍优,这是因为DeblurGANv2的不是基于纯MSE训练,但DeblurGANv2具有更高的SSIM指标同时更低的计算量,节省了约78%的推理耗时。相比其他两个次之去模糊方法,轻量型版本取得了类似性能但具有超100倍更快速度。值得一提的是,MobileNet-DSC仅需0.04s,近乎达到了实时性要求,这是截止目前仅有的更快且具有高性能的去模糊算法。
下图给出了Kohler数据及上的效果以及指标对比。尽管SRN具有更高的指标,但DeblurGANv2具有更快的速度以及视觉效果,而SRN甚至出现了彩色伪影。


小结
作者提出一个有力且高效的图像去模糊框架,同时具有更高性能、更快速。该框架可以根据性能、算力需求而调节不同的骨干架构以适配不同场景。作者提到有计划将其适用于视频增强领域以更好处理混合降质问题。
参考代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import mobilenet_v2 as MobileNetV2
class FPN(nn.Module):
def __init__(self):
super(FPN, self).__init__()
net = MobileNetV2(pretrained=True)
self.features = net.features
self.enc0 = nn.Sequential(*self.features[0:2])
self.enc1 = nn.Sequential(*self.features[2:4])
self.enc2 = nn.Sequential(*self.features[4:7])
self.enc3 = nn.Sequential(*self.features[7:11])
self.enc4 = nn.Sequential(*self.features[11:16])
self.lateral4 = nn.Conv2d(160, 128, 1, bias=False)
self.lateral3 = nn.Conv2d(64, 128, 1, bias=False)
self.lateral2 = nn.Conv2d(32, 128, 1, bias=False)
self.lateral1 = nn.Conv2d(24, 128, 1, bias=False)
self.lateral0 = nn.Conv2d(16, 128//2, 1, bias=False)
self.td1 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU())
self.td2 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU())
self.td3 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU())
def forward(self, x):
enc0 = self.enco(x)
enc1 = self.enc1(enc0)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
enc4 = self.enc4(enc3)
lateral4 = self.lateral4(enc4)
lateral3 = self.lateral3(enc3)
lateral2 = self.lateral2(enc2)
lateral1 = self.lateral1(enc1)
lateral0 = self.lateral0(enco)
map4 = lateral4
map3 = self.td3(lateral3+F.upsample(map4,scale_factor=2))
map2 = self.td2(lateral2+F.upsample(map3,scale_factor=2))
map1 = self.td1(lateral1+F.upsample(map2,scale_factor=2))
return lateral0, map1, map2, map3, map4
class FPNHead(nn.Module) :
def __init__(self, inc, midc, outc):
super(FPNHead, self)
self.blk0 = nn.Conv2d(inc, midc, 3, 1, 1, bias=False)
self.blk1 = nn.Conv2d(midc, outc, 3, 1, 1, bias=False)
def forward(self, x):
x = F.relu(self.blk0(x))
x = F.relu(self.blk1(x))
return x
class FPNMobileNet(nn.Module):
def __init__(self):
super(FPNMobileNet, self).__init__()
self.fpn = FPN()
self.head1 = FPNHead(128, 128, 128)
self.head2 = FPNHead(128, 128, 128)
self.head3 = FPNHead(128, 128, 128)
self.head4 = FPNHead(128, 128, 128)
self.fusion1 = nn.Sequential(nn.Conv2d(512, 128, 3, 1,1),
nn.BatchNorm2d(128),
nn.ReLU())
self.fusion2 = nn.Sequential(nn.Conv2d(512, 64, 3, 1,1),
nn.BatchNorm2d(128),
nn.ReLU())
self.output = nn.Conv2d(64, 3, 3, 1, 1)
def forward(self, x):
map0, map1, map2, map3, map4 = self.fpn(x)
map4 = F.upsample(self.head4(map4), scale_factor=8)
map3 = F.upsample(self.head3(map3), scale_factor=4)
map2 = F.upsample(self.head2(map2), scale_factor=2)
map1 = self.head1(map1)
fusion = torch.cat([map4, map3, map2, map1], dim=1)
fusion = self.fusion1(fusion)
fusion = F.upsample(fusion, scale_factor=2)
fusion = self.fusion2(fusion + map0)
fusion = F.upsample(fusion, scale_factor=2)
output = torch.tanh(self.output(output)) + x
output = torch.clamp(output, -1, 1)
return output
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

