
本文作者通过实验证实:相比模拟数据,基于RealSR的SISR具有更好的视觉效果。
作者同时还提到:尽管该数据集仅采用了两个相机采集(Canon 5D3, Nikon D810),但其训练模型在其他相机(Sony a7II)和手机采集的数据上的泛化性能仍然很好。
现有大多SISR方法是在模拟数据集(LR通过对HR执行简单的双三次下采样得到)上进行训练与评估。然而,真实世界的LR图像往往更复杂,因此在模拟数据集上训练的模型应用到真实数据是性能会出现下降。
作者构建了一个真实超分数据集(LR-HR通过调整数码相机的焦距得到,然后采用图像配准算法进行不同分辨率图像的对齐)。考虑到该数据中的降质核的非均匀性,作者提出一个机遇拉普拉斯金字塔的核预测网络(LP-KPN),它可以有效的学习逐像素核以重建HR图像。
首发知乎:https://zhuanlan.zhihu.com/p/80552632
文章作者: Happy
相关链接:https://github.com/csjcai/RealSR
https://link.zhihu.com/?target=https%3A//csjcai.github.io/papers/RealSR.pdf
Abstract
有鉴于已有模拟数据训练的SISR模型在真实场景的性能受限问题,作者认为构建一个真实超分数据集很有必要性。作者采用一种灵活而易于复现的方法构建了一个真实的RealSR数据集,对于同一场景采用同一相机以不同的焦距采集数据。
然而,除了视场角变化外,调整焦距还会导致其他挑战:比如关心漂移,尺度因子变化、曝光时长以及光学畸变等。为解决这类问题,作者还提出一种有效的图像配准算法以逐渐对齐图像对,方便用于SISR模型的端到端训练。
该RealSR数据集包含两个数码相机(Canon 5D3, Nikon D810)拍摄不同的室内与室外场景,为SISR的实际应用提供一个好的训练与测试基准。相比已有的模拟数据集,RealSR数据的降质模型更为复杂(降质核实空间可变的,它随景深变化而变化)。
在此基础上,作者还训练了一个基于核预测网络的SISR模型。核预测网络已被广泛应用与图像降噪、图像去模糊以及视频插帧领域。KPN的内存占用为随着核尺寸增大而指数提升,在KPN基础上,作者引入图像处理中拉普拉斯金字塔方案得到本文的LP-KPN模型,它可以用小尺寸核学习更丰富的信息。下图给出了所提数据集以及方法的效果示意图。

该文的贡献主要包含以下两个方面:
- 构建了不同缩放尺度的RealSR数据集,首个具有更通用目的的真实SISR训练与测试基准;
- 提出了LP-KPN模型,并在RealSR数据及上验证了其他有效性与高效性。
Method
RealSR
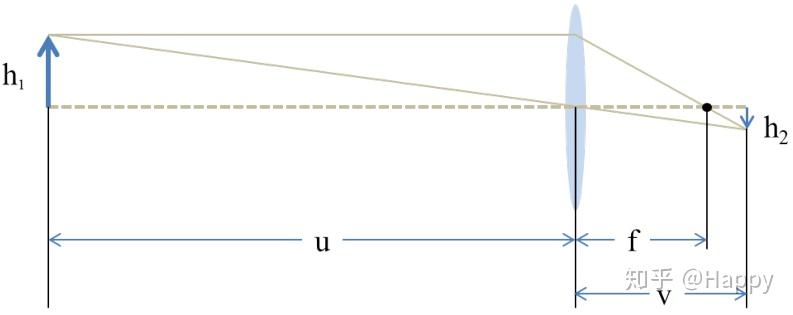

上图给出了透镜成像原理,按照公式有以下: $$ \frac\{1\}\{f\} = \frac\{1\}\{u\} \+ \frac\{1\}\{v\} $$ 数据采集过程中,固定$h\_1$与u,考虑到$u\gg f$,此时有: $$ h\_2 = \frac\{f\}\{u\-f\}h\_1 \approx \frac\{f\}\{u\}h\_1 $$ 因此,$h\_2\,f$之间近似存在线性关系,通过提升焦距$f$,相机可以采集更大更清晰的图像,理论上可以通过控制合理的焦距选择不同的尺度。
在实际数据采集过程中,作者采用了4个不同的焦距:$105mm, 50mm, 35mm, 28mm$。最大焦距用于采集HR图像,其他焦距用于采集不同尺度因子的LR图像。作者还提到,采用28而非24焦距是因为$24mm$焦距时的镜头畸变难以通过后处理校正。为确保数据的泛化性,该数据集同时包含室内与室外场景,数据包含丰富的纹理(超分的主要目的是复原/增强图像的细节)。
图像对齐
数据的采集是比较容易的,但因镜头焦距缩放会导致许多难以控制的畸变,这会导致像素不对齐问题。不同焦距采集的图像往往存在不同程度的镜头畸变与不同的曝光,而且还会存在光心漂移线性。由于上述因素,现有的图像配准方法难以直接得到不同角度图像的像素级的对齐,为此,作者设计一种渐进对齐的图像对齐方法,如下图所示。

在图像对齐过程中,裁剪中心区域(畸变比较轻,容易校正)校正其对应的LR图像。由于不同焦距图像的亮度、尺度差异,基于SURF、SIFT的图像对齐方法难以得到像素级对齐。为得到精确的图像对配准,作者设计了一种同时考虑亮度调整的像素级对齐方法。假设$I\_H\, I\_L$分别表示对应的HR图像与LR图像,它通过优化如下目标函数得到: $$ \mathcal\{min\}\_\{\tau\} \\\|\alpha C\(\tau \circ I\_L\) \+ \beta \- I\_H\\\|\_p^p $$ 其中,$\tau$表示仿射变换矩阵,C表示裁剪操作(确保LR与HR具有相同尺寸),$\alpha\, \beta$为亮度调整参数。
LP-KPN
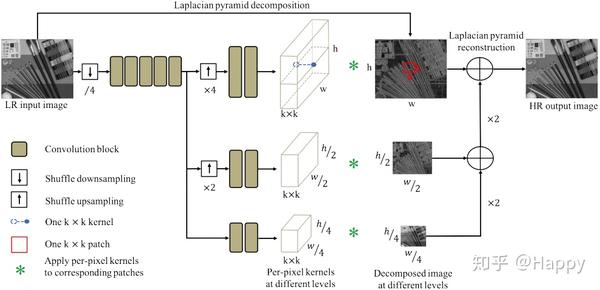

上图给出了作者所提出的网络架构。假设$I\_L^A\, I\_H$分别表示LR与HR图像,KPN以$I\_L^A$未输入,输出核张量$T \in R^\{\(k \times k\) \times h\times w\}$,它在通道方向的向量$T\(i\,j\) \in R^\{\(k\times k\)\}$可以变换为$k\times k$的卷积核$K\(i\,j\)$,将其作用于LR图像的每个像素的局部近邻以生成HR输出。该过程可以描述为: $$ I\_H^P\(i\,j\) = \<K\(i\,j\)\, V\(L\_L^A\(i\,j\)\)\> $$ 其中,$V\(L\_L^A\(i\,j\)\)$表示LR图像在$\(i\,j\)$处的局部近邻,$<\cdot\>$表示内积运算。上式表明:输出图像的每个像素是其在输入图像对应位置的近邻像素的加权线性组合。为获得更好的性能,大尺寸核有助于利用丰富的近邻信息,另一方面,核张量会随着核尺寸增大而指数增加,进而导致高计算量与内存需求。
为得到Effective and Efficient的KPN,作者提出一种基于拉普拉斯金字塔的KPN架构。如同已有诸多SR方法,该方法仅处理YCbCr空间的Y通道。拉普拉斯金字塔将图像分解为了不同层级的子图像(不同的分辨率大小),这些分解的子图像可以精确的重建原始图像。基于该特性,LR图像的Y通道被分解为三个尺度图像金字塔$\{S\_0 \in R^\{h\times w\}\, S\_1 \in R^\{h/2 \times w/2\}\, S\_2 \in R^\{h/4 \times w/4\}\}$\,该LP-KPN以三尺度LR图像作为输入,输出对应的三个核张量$\{\mathbf\{T\}\_0\, \mathbf\{T\}\_1\, \mathbf\{T\}\_2\}$\,该可学习核张量按照前述公式作用于三个输入图像以复原HR图像在不同层级的拉普拉斯分解子图像。最后,采用拉普拉斯金字塔重建得到HR图像。受益于拉普拉斯金字塔,这里的$k\times k$核尺寸等价于原始分辨率的$4k \times 4k$感受野,相比于直接学习$4k \times 4k$核,这种方法可以极大的降低计算复杂度。
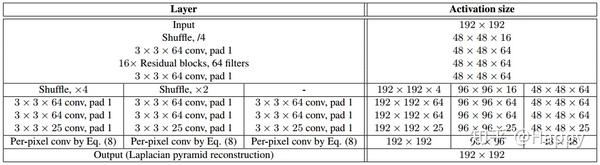
LP-KPN的骨干部分把汗17个残差模块,为提升有效性,作者采用shuffle操作进行图像下采样与上采样操作,首先以因子$1/4$进行下采样,将其送入到骨干网络中。需要注意的是:除了最后的基层,该网络的大部分卷积模块被三个尺度共享,这可以极大的减少模型的参数量。为得到不同尺度的核张量,在网络的末端添加不同因子的上采样单元以生成合适的核张量。该LP-KPN共计包含46的卷积层(远少于其他SISR方法),相关层参数配置如下所示。
Experiments

上表给出了作者所构建的RealSR数据集的信息,随机从每个相机每个尺度数据对中选择15对作为测试集,其他作为训练集。评估指标选用PSNR/SSIM,评估YCBCr中的Y通道。在训练过程中,输入图像块为192x192,采用了随机旋转、随机镜像进行数据增广,BatchSize=16,优化器选择Adam,学习率为0.0001,共计训练1000K迭代,训练框架为Caffe+Matlab。
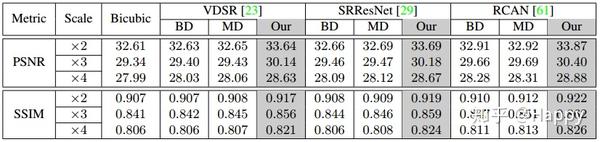
为验证数据集的重要性,作者以DIV2K采用不同的降质方式(双三次、多种降质)外加RealSR构成了三个数据集,同时采用了VDSR、SRResNet、RCAN三个有代表性模块,在三个尺度层面进行超分,共计得到27个模型。其性能对比与视觉效果见下表与下图。从中可以看出:相比其他两种降质模型,采用相同超分模型下在RealSR数据集上训练所得模型具有更好的性能。

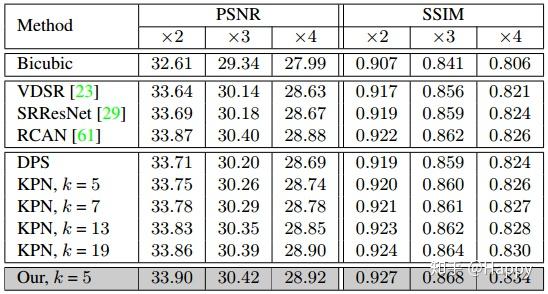
为验证所提网络架构LP-KPN的有效性,作者将其与其他8个超分网络进行了对比。其性能对比如下所示。从中可以看出:(1) 直接像素生成方法中RCAN下过最佳;(2) LP-KPN取得了最优的效果,甚至优于核尺寸为19的KPN网络,同时具有更少的计算复杂度更快的推理速度。更多的实验结果与数据分析详见原文,这里不再过多赘述。

Conclusion
模拟数据训练的超分模型难以泛化到真实图像上是一个存在已久的问题。作者在这个方向上进行了探索与尝试,构建了真实退化的超分数据集,采用Canon与Nikon相机采集了595对超分数据对,同时设计一个有效的图像配准算法以确保图相对之间的像素级对齐。
作者还基于拉普拉斯金字塔提出一个LP-KPN网络架构,作者首先验证了RealSR数据集的的重要性,同时在RealSR数据及上验证了其所提架构的SOTA性能。
截止目前,作者所构建的RealSR数据集已经拓展到了V3版本,感兴趣者可以去作者的开源代码网络下载。
参考代码
作者所提供的代码为caffe框架的prototxt以及相应caffemodel,都2109年了,现在还在用caffe的人真的很少了,故而本人参考其caffe代码,将其用pytorch进行了架构重建,后面有时间的话还会花点时间将其预训练模型转为pytorch格式,暂时仅提供pytorch的架构,没有相关预训练模型。
import torch as th
import torch.nn as nn
# shuffle下采样计算单元
# [图像去模糊:ECPeNet](https://zhuanlan.zhihu.com/p/79410449)
# 跟本人先前的实现有点区别,为适配作者matlab版本进行微调调整
def shuffle_down(inputs, scale):
N, C, iH, iW = inputs.size()
oH = iH // scale
oW = iW // scale
output = inputs.view(N, C, oH, scale, oW, scale)
output = output.permute(0,1,5,3,2,4).contiguous()
return output.view(N, -1, oH, oW)
# shuffle as realsr<matlab>
def shuffle_up(inputs, scale):
N, C, iH, iW = inputs.size()
oH = iH * scale
oW = iW * scale
oC = C // (scale ** 2)
output = inputs.view(N, oC, scale, scale, iH, iW)
output = output.permute(0,1,4,3,5,2).contiguous()
output = output.view(N, oC, oH, oW)
return output
class ResBlock(nn.Module):
def __init__(self, inc, ksize):
super(ResBlock, self).__init__()
pad = (ksize - 1)//2
self.net = nn.Sequential(nn.Conv2d(inc,inc,ksize,1,pad),
nn.ReLU(),
nn.Conv2d(inc,inc,ksize,1,pad))
def forward(self, x):
return x + self.net(x)
# core1: pixel_convolution
def pixel_conv(feat, kernel):
N, k2size, H, W = kernel.size()
ksize = np.int(np.sqrt(k2size))
pad = (ksize-1)//2
feat = F.pad(feat, (pad, pad, pad, pad))
feat = feat.unfold(2, ksize, 1).unfold(3, ksize, 1)
feat = feat.permute(0, 2, 3, 1, 5, 4).contiguous()
feat = feat.reshape(N, H, W, 1, -1)
kernel = kernel.permute(0, 2, 3, 1).unsqueeze(-1)
output = torch.matmul(feat, kernel)
output = output.reshape(N, H, W, -1)
output = output.permute(0, 3, 1, 2).contiguous()
return output
# core2: laplasian pyramid write as original code
# https://github.com/csjcai/RealSR
class LaplacianPyramid(nn.Module):
def __init__(self):
super().__init__()
kernel = np.float32([1, 4, 6, 4, 1])
kernel = np.outer(kernel, kernel)
kernel = kernel[:,:,None,None] / kernel.sum()
kernel = th.from_numpy(np.transpose(kernel,(3,2,0,1)))
self.downconv = nn.Conv2d(1, 1, 5, 2, 2, bias=False)
self.downconv.weight = nn.Parameter(kernel)
self.upconv = nn.Conv2d(1, 1, 5, 1, 2, bias=False)
self.upconv.weight = nn.Parameter(kernel*4)
def zeroup(self, x):
N, C, H, W = x.size()
output = th.zeros(N, C, H*2, W*2)
output[:,:,::2,::2] = x
return output
def forward(self, input_list, up=False):
if up:
s4lo = input_list[2]
s2hi = input_list[1]
s1hi = input_list[0]
s2 = self.upconv(self.zeroup(s4lo)) + s2hi
s1 = self.upconv(self.zeroup(s2)) + s1hi
return s1
else:
output = []
img = input_list[0]
# scale1-hi
s2lo = self.downconv(img)
s1hi = img - self.upconv(self.zeroup(s2lo))
output.append(s1hi)
# scale2-hi
s4lo = self.downconv(s2lo)
s2hi = s2lo - self.upconv(self.zeroup(s4lo))
output.append(s2hi)
# scale4-low
output.append(s4lo)
return output
# framework
class LPKPN(nn.Module):
def __init__(self, ksize=5):
super().__init__()
self.conv = nn.Conv2d(16, 64, 3, 1, 1)
backbone = [ResBlock(64, 3) for _ in range(16)]
backbone += [nn.Conv2d(64, 64, 3, 1, 1)]
self.backbone = nn.Sequential(*backbone)
self.sk1 = nn.Sequential(nn.Conv2d(4, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64,ksize**2,3,1,1))
self.sk2 = nn.Sequential(nn.Conv2d(16, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64,ksize**2,3,1,1))
self.sk4 = nn.Sequential(nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(64,ksize**2,3,1,1))
self.lapPyramid = LaplacianPyramid()
# x1, x2, x4分别表示laplacian金字塔3尺度分解输出
def forward(self, x):
lap1, lap2, lap4 = self.lapPyramid([x], up=False)
feat = shuffle_down(x, 4)
feat = self.conv(feat)
feat = feat + self.backbone(feat)
sk1 = self.sk1(F.pixel_shuffle(feat, 4))
sk2 = self.sk2(F.pixel_shuffle(feat, 2))
sk4 = self.sk4(feat)
out1 = pixel_conv(lap1, sk1)
out2 = pixel_conv(lap2, sk2)
out4 = pixel_conv(lap4, sk4)
output = self.lapPyramid([out1, out2, out4], up=True)
return output
def demo():
x = torch.randn(4, 1, 192, 192)
model = LPKPN()
model.eval()
with torch.no_grad():
out = model(x)
print(out.size()) # [4, 1, 192, 192]
if __name__ == "__main__":
demo()本人花费半天时间将作者的CAFFE模型转为了Pytorch,两者结果完全一致。经亲测,利用作者提供的模型超分的效果并不好(并未达到作者论文中的效果,经多次核对,两者结果却是一致,无论是用matlab+caffe输出结果,还是用转换后pytorch模型输出的结果均如下),见最终的对比效果图。
20190828补充:
经与作者沟通发现,作者所提供的模型仅限于对比PSNR/SSIM指标,如需更好的视觉效果需要调整三个head分支的损失比例(作者原文损失比例为16:4:1,而提供的模型则为1:1:1),或者更换感知损失。
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

