
20200423补充:中午吃饭时间看到了一篇为ResNeSt“正名”的文章,链接如下。可能@Amusi没有深入去对比分析ResNeSt之前的代码与最新代码的区别。就在9个小时之前,作者对本文发提到的“不一致”问题进行了纠正,添加了rSoftMax实现(该实现与本文提供的正确代码实现一致,有兴趣的小伙伴可以去对比一下,^\_^),同时添加了不同实现方式的对比。所以本文关于ResNeSt的疑惑点基本到此结束!虽然torch版本实现存在瑕疵,不过该文还是一个非常不错的工作。
ResNeSt: Split-Attention Networks
该文是亚马逊&UC Davis联合写的一篇关于改进ResNet的paper。ResNet自提出后引起了非常大的轰动,同时得到太多太多的应用与研究。单单其变种就有几十种,其中最知名的当属ResNeXt, SENet,GENet, SKNet,CBAM等等。其中尤以ResNeXt, SENet与SKNet最为人知。而亚马逊出品的这篇ResNeSt一经开源同样引起了不小的轰动:ResNet最强改进版来了!ResNeST: Split-Attention Networks。但相应的,存在的额疑惑点也不少,比如@打酱油的疯子提出的疑点:
看了下实验setting,用了标签平滑,auto数据增强,大batch,cos learning rate decay,大epoch,混合样本训练等各种涨点手段,对比的resnet却是15年的最基本的训练方法得到正确率。这个实验并不能证明模型更改对效果提升的带来的价值。起码需要补充resnet等模型使用同样的训练手段的正确率,或者使用与resnet相同的方法训练模型的结果,才能有说服力。如果不能证明在同等训练条件下,这个模型比resnet等模型好,那这个结果仅有工程价值,而不具有学术价值。充其量只是一个好的backbone。另外是不是好的backbone这件事情也有待商榷,目测实际的latency不会太好,总之疑点太多。
笔者在github上首次看到该ResNeSt的代码时,还存在一个疑惑:它与SKNet的相似性。相关提问可见链接
ResNeXt
ResNeXt是FAIR的大神们(恺明、Ross、Piotr等)对ResNet的改进。其关键核心模块如下所示。 尽管ResNeSt与ResNeXt比较类似,不过两者在特征融合方面存在明显的差异:ResNeXt采用一贯的Add方式,而ResNeSt则采用的Cat方式。这是从Cardinal角度来看,两者的区别所在。这点区别也导致了两种方式在计算量的差异所在。

SKNet
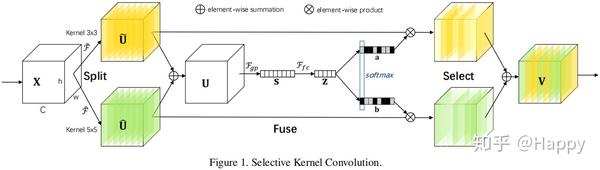
SKNet全称为Selective Kernel Network,其核心在于所提出的Select Kernel。作者关于Select Kernel的解释为:
We propose a dynamic selection mechanism in CNNs thatallows each neuron to adaptively adjust its receptive field size based on multiple scales of input information. A building block called Selective Kernel unit is designed, in which multiple branches with different kernel sizes are fused using softmax attention that is guided by the information in these branches.敲黑板,请注意:Selective Kernel的重点是多分支且不同分支采用不同尺寸的卷积核。这里就对应了作者@张航在知乎上的一个回复
这篇文章主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。SKNet 缺点是多分支,不模块化
诚然,Selective Kernel的多尺度是其的关键核心所在。SKNet的官方代码SKNet50采用的是两分支的Selective Kernel,为减小计算量一个分支设置为kernel_size=3的标准卷积核,一个分支设置为kernel_size=3, dilation=2的扩张卷积。@张航所提到的SKNet的缺点是多分支,不模块化适用于训练阶段;而在推理阶段,两个分支计算事实上可以采用策略进行合并(比如合并为kernel_size=5,groups=2的标准卷积),具体效率如何呢?笔者没有具体去测,就不下结论了。
另,ResNeSt中的Split-Attention可以视作Select Kernel的一个特例(双分支的卷积核尺寸相同)。
ResNeSt
回到正文,我们结合前面的对比分析再来看一下ResNeSt的关键架构,见下图。 各位小伙伴有没有觉得:ResNeSt是ResNeXt与SKNet的组合?。其实这样说并没有错,作者@张航也提到了这篇文章主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。
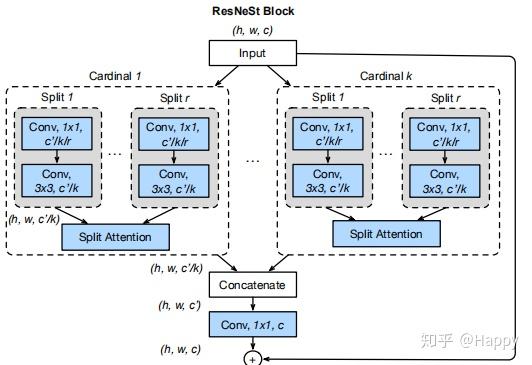
原理方面的东西就不再过多介绍,前面提到的知乎链接、作者原文已经介绍的非常清楚了。这里仅结合作者提供的代码以及相关模块示意图进行简单的分析与说明,以下图为例进行说明,该图也与作者提供的SplAtConv2d模块代码相对应。
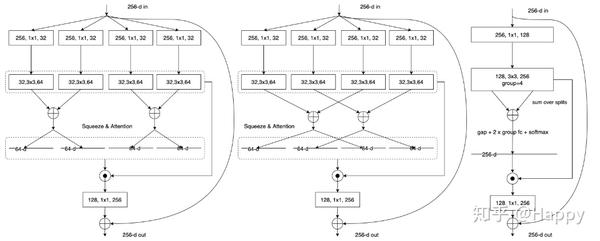
左图是作者提的SplAtConv2d最朴素的实现,但是这种实现方式包含过多的细粒度分支,执行效率比较低。这也对应着作者提到的SKNet的不模块化问题。写到这里,突然觉得作者应该再加一个图对比更好:(1) 不同尺寸卷积核的Selective Kenel模式;(2)同尺寸卷积核的Selective Kernel模式,也就是上图的左图;(3) 上图中;(4) 上图右。通过这样的对比,就更容易说明ResNeSt是如何一步步的改进而来。
20200422补充:上面的中图到右图的第一个1x1卷积同样不存在等价关系,图示中1x1同样应该是groups=4才是等价。不过这块不是重点,可以忽略。第一个1x1与3x3的串联卷积是否可以替换为(1x1和3x3)或者(3x3和3x3-dilation=2)的并行卷积。这样采用相同粒度的卷积达到类似的目的,这个也许会是个不错的工程改进思路。
回到正题,上图中的左图与中图等价应该无需多言,而中图到右图则是简单的组卷积的替换,更是无需多言。这里给出一个简单的演示图。 该图结合作者的代码和论文原图进行流程归纳(左图为作者源码输出流程图,右图为理论上的流程图,很简单的草图,应该容易理解),事实上,**图中的红色区域作者的实现是有问题的**。

存在问题的代码行:
atten = self.fc2(gap).view((batch, self.radix, self.channels))
这里的处理会导致所有通道之间存在相干性,而这在Split-Attention却不应该如此。
Conclusion
以上是本人针对ResNeSt、ResNeXt、SKNet进行分析的一点小结论,论文思想还是非常不错的,但是代码与论文还是存在些微不一致性问题。 也有可能是本人分析有问题,如有哪位小伙伴发现问题请指正一下。
补充
针对前面提到的论文和代码不一致问题,进行简单的分析。因为作者在Similar to the attention of SKNet. · Issue #4 · zhanghang1989/ResNeSt 提到了一种等价关系,而这也是该文的一个核心。但是分析发现,代码实现并不存在这种等价关系。原因如下:
- split-attention中的softmax部分不符合等价关系,主要是因为split问题导致。可以参考本人修正的代码分析一下。
尽管作者github中提供的代码同样可以正常训练测试,但其与论文中的描述确实不一致。有兴趣的小伙伴可以自己尝试一番对比一下。
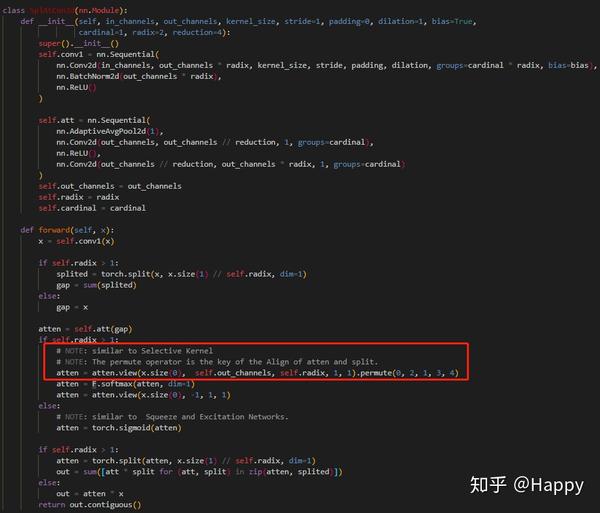
对view、split流程不太清楚的小伙伴容易被绕晕,所以我花了点时间绘制了图进行说明。首先给出按照作者代码执行的流程。这里假定,输入16个通道,Cardinal=4,Radix=2。按照流程,先进行groups=8的Conv输出32个通道,用不同颜色标色。然后进行split+sum。不同组间的对应关系通过箭头示出了。后续紧接的是GAP+FC1+FC2(groups=cardinal=4)。此时输出一个32通道的加权系数(尚未进行归一化),由于group的原因,仍然采用不同颜色标注。下一步就是关键问题了。按照作者的代码split后就的排列就出现问题,进而导致后续的split+sum有问题。

最后,补充上正确的流程图:
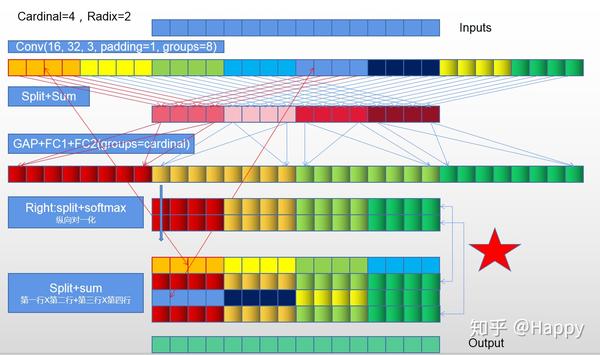
注:上述分析仅仅是针对Split-Attention等价关系。非常期望与作者@张航一起讨论分析下是否存在该问题。
20200422补充,最后附上SKNet中的对应模块的示例代码如下。 感兴趣的小伙伴可以对比一下该部分SKConv与SplAtConv2d的区别与联系。主要区别有三点:(1)self.att部分中的groups;(2)atten进行softmax操作之前的Reshape操作(重点在于groups参数对于Reshape的影响);(3)self.conv1部分代码。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.quantized import FloatFunctional
class SKUnit(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, 1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
SKConv(mid_channels),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(mid_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.relu = FloatFunctional()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
return self.relu.add_relu(x, out)
class SKConv(nn.Module):
def __init__(self, channels, M=2, reduction=4):
super().__init__()
self.conv1 = nn.ModuleList([])
for i in range(M):
self.conv1.append(nn.Sequential(
nn.Conv2d(channels, channels, kernel_size=3, padding=1+i, dilation=1+i, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU()
))
self.att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, channels//reduction, 1),
nn.ReLU(),
nn.Conv2d(channels//reduction, channels * M, 1)
)
def forward(self, x):
splited = [conv(x) for conv in self.conv1]
feats = sum(splited)
att = self.att(feats)
att = att.view(x.size(0), len(self.conv1), x.size(1))
att = F.softmax(att, dim=1)
att = att.view(x.size(0), -1, 1, 1)
att = torch.split(att, x.size(1), dim=1)
return sum([a * s for a, s in zip(att, splited)])最后的最后,突然想到,如果想SKConv的conv1与SKUnit的conv1合并处理一下呢?效果有将是怎样的呢?有兴趣的小伙伴可以亲自尝试一番。另外,从流程图是不是看到了点ShuflleNet中的通道置换的影子?
全文到底结束,相信通读全文的小伙伴应该对ResNeSt的整个流程非常清楚了,下一步就可以去尝试一下改进发paper咯!
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

