
Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition
该文出自Facebook-AI,作者包含Bing Xu, Yunpeng Chen等大神。 该文提出一种性能的模块:IdleBlock,它以一种自然的方式进行块内链接裁剪。为更充分利用所提模块,作者打破了已有网络架构的设计方式,引入模块混合组成方式。作者研究了MobileNetV3与EfficientNet-B0的混合组成。无需NAS,采用混合组成模块的MobileNetV3即可取得SOTA的分类性能(超越人工设计网络与NAS);类似的,在同等计算约束下,混合版本EfficientNet-B0计算更高效。这为网络结构设计与NAS提供了一个更简单而有效的研究方向。
Introduction
作者重新研究了现有高效卷积网络的设计流,并将其划分为两个独立步骤。第一个步骤:设计网络架构;第二个步骤:网络剪枝。 在第一个步骤中,已有网络(包含人工设计与NAS)主要包含一个常规模块与一个下采样模块。整个网络的构成架构如下图所示。作者将这种设计模式称之为单调设计模式。比如残差网络由多个BottleNeck构成,ShuffleNet由多个ShuffleBlock构成。诸如MobileNet、NASNet、FBNet等均采用了类似的设计模块。在这些网络中,所有模块均具有全信息交换;在第二阶段,某些链接被剪枝后,此时无法确保全信息交换。

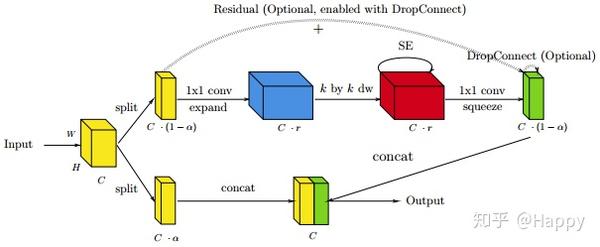
通过考虑将剪枝融入到网络设计阶段,作者尝试设计一种更高效的用于图像识别的网络。作者提出了一种新的模块设计方法:Idle。在设计过程中,输入的子空间不做变换:即直接闲置并传递到输出。作者同时还打包了单调设计模式约束问题,将该非单调组合称之为混合组合(Hybrid Composition)。该设计模块如下图所示。

Method
Motivation
作者首先对比分析了Bottleneck与Inverted Residual(也称之为MBBlock)两个模块的区别,并指出:对于深度卷积而言,扩展特征图通道数有助于提升网络的表达能力;然后分析了通道置换类方法,并指出:通道置换在大多硬件上并非绝对高效,依赖于神经网络加速器。作者提到在CoreML推理框架下带通道置换要比不带通道置换慢10倍。
当设计高效模块架构时,降低计算量(MAdds)是一个明显的方向,比如用深度卷积替换标准卷积;当为硬件平台做优化时,还有其他更多挑战。比如,尽管后训练剪枝可以降低计算量,但需要特定的计算库与高稀疏性,否则难以真正达到计算量降低的目的。
作者尝试引入一种结构化剪枝方案到模块设计中,以真正达到加速目的。基于该考虑,作者提出一种新的设计模块:Idle,它直接将输入的部分信息不经任何变换输入到输出。在该模块设计中,作者引入一个闲置因子参数,它可以视为剪枝因子。给定包含C个通道的输入张量x,该张量将被划分为两个分支:(1) 激活分支,它包含个通道,其对应同样通道的输出张量;(2)闲置分支,它包含个通道,直接由输入复制到输出。
Discussion
这种设计思路与ShuffleNet比较类似,但有一下几点不同: (1)ShuffleNet需要扩张进行特征图的扩展与收缩,而Idle则不需要进行这些操作; (2)ShuffleNet中所有信息将进行通道置换,而Idle则不需要进行任何通道置换类改变;(3)Idle目的在于设计一个预剪枝结构,而ShuffleNet则旨在得到更窄特征进行空间变换。
作者简单总结了从Inverted Residual与ShuffleNet中学习到的直觉与经验:
- 需要在扩展特征图上执行深度卷积;
- 组卷积并非必要;
- 通道置换对于加速器不友好,需要遗弃。
基于上述知识,作者提出了IdleBlock,一种Idle版MBBlock,见下图。如图1所示,有两种设计变种,根据限制通道所在位置的不同分别将其命名为L-IdleBlock,R-IdleBlock。
混合组合的一个关键目的是:增强输出的感受野。大家可以自己先分析一下如何根据所提到的这两个模块组合提升输出的感受野。异形交替方式or同形堆叠方式?
Hybrid Composition
在前面章节,作者引入了IdleBlock,在这里作者将引入混合组合,一种新颖的非单调网络组合方法。在网络的每个阶段,作者采用多种类型的模块进行非单调组合。这种组合仅适用于对输入与输出维度有相同约束的不同模块。比如,ShuffleNetv1/v2可以与Bottleneck模块混合(两者均要求窄输入宽输出);而Bottleneck模块不适合与MBBlock混合,这是因为两者具有不同的瓶颈层设计原则,输入与输出维度不相同。混合组合尝试组合利用不同类型模块的属性,而这是单调设计原则所无法做到的。
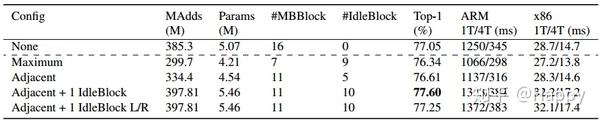
作者认为:IdleBlock与MBBlock均满足混合组合的输入与输出约束。一旦将两者组合,那么MBBlock的第一个点卷积有助于IdleBlock进行两个分支间的信息交换,而无需额外的通道置换操作。然而,混合组合会引入另一个挑战:如果一个阶段包含n个MBBlock,那么将有中组合,需要重中探索一个最小子集。为此作者探索了三种配置方式:Maximum, None, Adjacent.
- Maximum。仅当输入与输出维度发生改变时使用
MBBlock,其他则仅采用IdleBlock。这种配置是混合组合的计算量下限,因为仅需要一个MBBLock单元进行信息交互; - None。此时不适用任何
IdleBlock,此时是混合组合的计算量上限; - Adjacent。它是一种贪婪策略,迭代的用
IdleBlock替换MBBlock直到达到指定的计算需求。当时,一个MBBlock的计算量等价于两个IdleBlock,也就是说可以通过采用两个IdleBlock替换MBBlock保持相同计算量,但网络深度将加深30%。 - 理论上,通过
NAS搜索的方式也将落在上限范畴内。
Experiments
类似其他图像分类网络,作者在ImageNet上验证了所提方法的有效性。作者将设置,聚焦于研究MobileNetV3与EfficientNet-B0,在Intel Xeon CPU, ARM Cortex CPU上统计模型的耗时。
关于训练配置,作者采用MXNet框架进行单节点与分布式训练。(1)单节点训练,采用8个V100GPU,采用混合精度训练,BatchSize=2048,优化器选择Nesterov,初始学习率设为2.6,权值衰减设为3e-5,共计训练360epoch,前5个epoch进行warmup;(2) 分布式训练,8个节点64个GPU,每个GPU的BatchSize=128,优化器采用LB-SGD,初始学习率设为0.8,动量因子0.9,权值衰减3e-5。所有模型训练80epoch(等价于单节点640epoch)。类似的,前5个epoch进行warmup,分布式模型使用了Mixup增广。
在推理阶段,作者在谷歌云(Intel SkyLake CPU@2.0GHz)上评估了推理耗时,对于ARM端,硬件平台为ARM Cortex-A53@600MHz。所有模型均采用TVM与AutoTVM进行了优化,这进一步降低了推理耗时。
下图给出了MobileNetV3的评估结果(注:*表示分布式训练结果)。从中可以看出:相比MobileNetV3,采用所提方法可以减少23%的计算量,而精度仅降低0.7%左右;如果保持同等计算量,此时可以提升精度04-0.9%左右。相比已有专家网络或NAS网络,持续加深网络可以得到更高效且高精度的结果。


下图给出了EfficientNet-B0在不同配置下的性能对比。
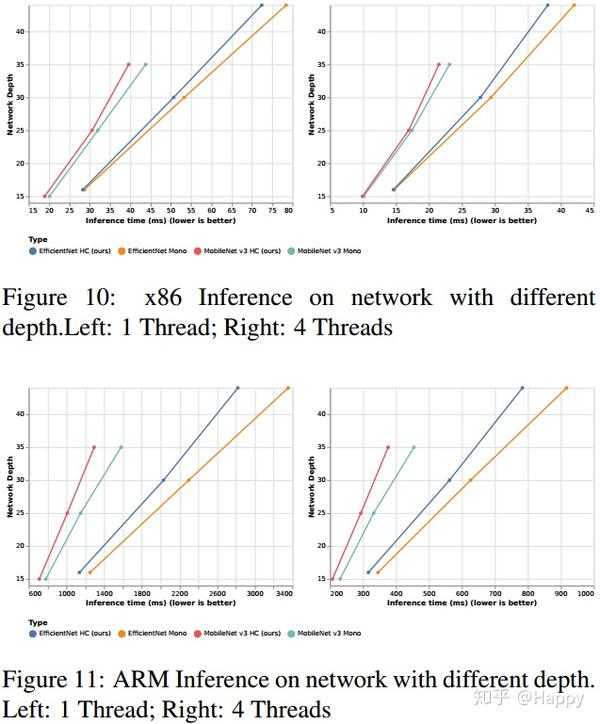
下图给出了所提方法在不同硬件平台的耗时对比。(注:理论上TVM优化后可以达到三分之一的加速比,但无论如何所提方法均得到了实际性的加速)
此外,作者还将所提方法与通道置换进行了对比,见下图。从中可以看出:对于该设计而言,通道置换并非必要。

最后,作者还分析了L/R-IdleBlock的对模型性能的影响。对于浅层网络而言,更大感受野将提升模型精度M,大部分实验均验证了该论点(堆叠有更大感受野)。其中有一个交错方式表现出了更高的性能,交错将引入一个新的超参数,不过相对其他超参,该超分极为不敏感。

Conclusion
受网络剪枝启发,作者提出一种新的网络设计方法:Idle与MBBlock的Idle版本。为更好的利用Idle的高效性,作者打破了传统的网络单调性设计原则,引入了混合组合策略(即组合Idle模块与MBBlock)。作者通过实验表明:相比其他SOTA方法,通过组合混合弥补剪枝降低的计算量使网络变得更深,同时具有更好的精度与计算效率。组合混合同样使得大网络变得更高效,这可能为未来来的NAS搜索更高效的分类网络提供了一个更简单的方向。Idle的设计原则可能也适用于扩展到其他任务的网络中。
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

