
该文是商汤科技、香港中文联合投于ARXIV的一篇关于可学习组卷积方面的论文。
相比常规卷积,组卷积取得了令人印象深度的进步。然而,现有的网络由于手动设置组数仍存在次优性能问题。未解决该问题,基于一种新颖的动态组卷积(DGConv)提出GroupNet,它可以通过端到端的方式学习组数。所提方法有以下几点优势:(1) DGConv为常规卷积、组卷积以及深度卷积提供了一个统一表达;(2) DGConv是一种可微分且灵活的单元,它可以通过训练执行各种各样的卷积;(3) GroupNet可以为不同的层学习不同的组卷积策略。
作者在ImageNet数据集上验证了其优于ResNet与ResNeXt的性能,同时给出了所提方法的组数可学习性说明。首发知乎:https://zhuanlan.zhihu.com/p/79295551
文章作者: Happy
相关链接:https://arxiv.org/abs/1908.05867
Abstract
组卷积已成为当前轻量型网络设计的一个核心模块,它具有简洁性与参数节省特点,比如ResNeXt以更少的参数更高的精度优于ResNet。尽管组卷积易于实施,但仍有一下几个缺点:
- 组卷积中的组数为超参数,它往往通过人工设定,且在ConvNet中保持相同;
- 已有的方法往往采用均匀分组方式,需要通过试错方式确定最佳方案,而且网络的不同深度所学习的特征意义存在差异,进而均匀的分组方式可能会存在降低性能的风险。

为解决上述问题,作者提出一种动态组卷积,常规卷积、组卷积以及深度卷积均可视为其特例。它具有以下几个优点:
- 动态聚合成组,如上图所示,DGConv可以自适应的学习组策略(组数与连接方式),而且添加正则项后还可以进一步控制模型大小与计算负载;
- 可微分性,DGConv是全可微的,可以采用SGD通过端到端的方式进行训练;
- 参数节省,训练过程中仅需额外的$\mathcal{log}\_2(c)$参数,这远远小于其节省的参数量,更进一步,在训练完成后,该参数可以被忽略掉。
动态组卷积
在介绍动态组卷积之前,先给出常规卷积与组卷积的定义:

其中,
类似地,组卷积的定义如下:

在组卷积的基础上,对其进行拓展可以得到动态组卷积的定义如下:

其中, 

如何设计稀疏矩阵U则是动态组卷积的关键操作。下图为本人曾设想一些稀疏卷积结构(供参考),曾尝试过枚举方式,但这种方式比较耗时。关于这点本人一直没人突破,也就僵在这里没能继续往下进行。

稀疏矩阵U的构建有这样几个难点:
- (1) SGD只能优化连续变量,而稀疏矩阵U是二值变量;
- (2)稀疏矩阵U会引入大量的参数,进一步增加的调优的难度;
- (3) 稀疏矩阵U千变万化,我们期望的是结构化稀疏,非结构化稀疏非我们所期望的,也就是所谓的如何给稀疏矩阵U添加正则项。
稀疏矩阵构建
上述稀疏矩阵构建方式不仅可以确保U具有组结构,同时可以节省可训练参数。这是因为:
既然完成了稀疏矩阵U的构建,那么剩下的就要去考虑如何对齐进行训练。作者提到现有支持自微分的框架(如Pytorch, Tensorflow)可以轻易将梯度反向传播到二值门限$g$,仅有要解决的则是如何处理sign函数,作者提到其在SS中的方式可以在这里应用,门限参数可以通过STE方式优化。(PS:直接提供code多好呀,期待作者开源这里的代码)


Groupable Residual Networks
DGConv可以轻易与ResNeXt相关联,它可以直接替换原有组卷积,作者将替换后的网络称之为Groupable ResNeXt。下图给出了ResNeXt50\_32x4d与其对应Groupable ResNeXt50的架构配置参数表。
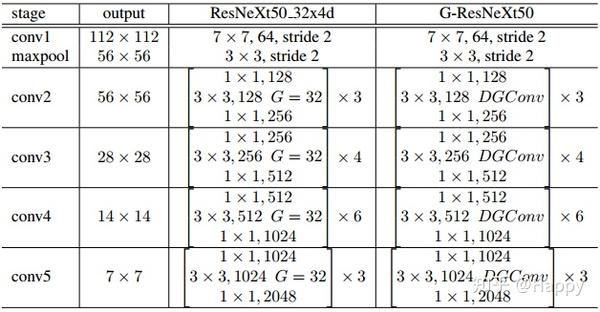
除了直接采用DGConv替换组卷积外,作者还提出了一种资源约束训练机制。不同的DGConv层可以具有不同的组数,这会导致如何/怎么降低计算量完全依赖于训练数据与任务。为此,作者提出一种正则项用于约束计算复杂度,该正则项表示为:

其中,L表示DGConv层数,从上式可以看出: 表示稀疏矩阵U中的非零单元数,可以度量卷积核中的激活数量,因而可以作为模型计算复杂的度量方式。结合稀疏矩阵U的特征,上式可以进一步调整为:

假设所期望的计算复杂度为o,优化目标则是搜索一个满足如下约束的深度模型:

作者提到,上述损失函数可以通过SGD直接进行优化,而且可以通过设置不同的o调节网络的复杂度约束,进而可以分析精度与复杂度之间的关系。
Experiments
作者以ImageNet为基准,对标ResNeXt50与ResNeXt101训练了两个网络。训练超参数配置类似ResNeXt,这里不再赘述。 在资源约束方面,推导出这样一个公式:

作者还提到一个有意思的发现:具有相同复杂度的ResNeXt与Groupable版本,GDConv倾向于在网络底层占据更多的计算量。这与恺明等人在ResNeXt中的发现类似:同等复杂度的网络,相比更深更快的网络,具有更大基的网络表现更好。性能的提升源自更强的表达能力,作者认为:可以通过调整每一个DGConv层的组策略进一步提升表达能力。
下图给出了本文方法与其他SOTA方法的性能对比,更多实验结果建议参考作者的分析,这里不再进行更多的赘述。

Conclusion
作者提出一种新颖的架构:Groupable ConvNet(GroupNet),它具有计算高效性同时可以提升性能。GroupNet可以通过逐层为每个卷积学习不同的组策略,同时优于标准组卷积方法(无论是精度还是计算复杂度),所提DGConv可以轻易的应用到现有深度网络中。
不过截止目前,只有CondenseNet一文的作者开源了源码,而FLGC与DGConv暂未开源代码,甚是期望相关代码的开源。
参考代码
链接:https://github.com/d-li14/dgconv.pytorch
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

