
eyeriss V2是MIT团队在2018年提出的升级版。在V1的基础上,主要进行了2点改进,第一是引入了被称为hierarchical mesh的NOC结构,用来获取更好的数据和权重的重用性。其次是增加了对权重和数据的压缩处理,用来支持稀疏矩阵的运算。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/95381665
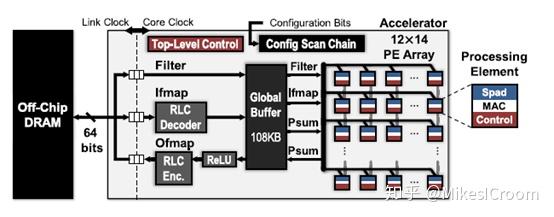
首先回顾下eyeriss v1的结构。这是一个memory和core分离的结构,通过总线进行通信。核内包含一个L1 memory(global buffer),整体控制模块(Top-level Control),数据数据的align(RLC),和核心运算矩阵:一个12x14的PE array。是一个典型的具有一定配置性的ASIC加速器。这样的PE array是一个扁平化的阵列,主要通过横纵向的控制流和数据流传递进行控制和数据交换,因此是一个简化的方案,每一个PE所具有的的存储和功能都比较有限,如果内部Spad空间不足,就需要访问外边的Global Buffer,这样的延迟就会比较大,对NOC的带宽也有较高要求。eyeriss V2希望探寻一种更为灵活的network形式。
eyeriss V2的思路还是比较直接的,就是增加每个PE能够直接使用的存储空间,整个框架类似于多核处理器系统中的内存结构。若干个Globle Buffers和PEs组成一个cluster,然后通过router连接在2D mesh上。这样将V1中的集中式的globle buffer分割成了每个cluster独有的存储空间。每个cluster内部可以算作一个完整的运算模块,包含较小的PE矩阵组,以及较原先Spad更大的存储。具体的结构如下图:

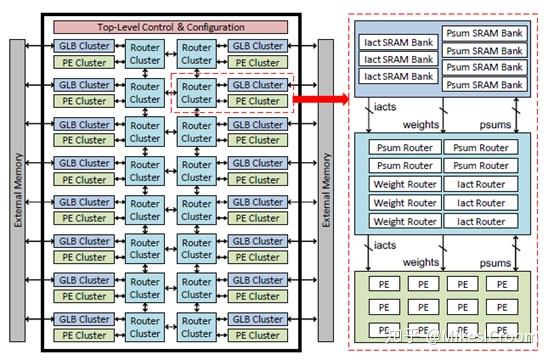
这种存储集中式向分布式的转化也符合目前深度学习加速器的内存结构。由于深度学习算法的特点,较大的运算能够很好的切分为若干个小运算的组合,包含独立的数据和权重。eyeriss可以将切分好的运算单位分散到各个cluster中并行执行。由于eyeriss的基本运算结构是一维的卷积运算,卷积结果会累加在PE自身,并没有像systolic计算方式那样需要纵向传递,因此PE矩阵的大小并不会影响其运算效率。这种小PE组结合大规模NOC的结构在很多数据流驱动的加速器,如wavecomputing的DPU上是很流行的。由于权重需要预先存储在PE cluster中,而卷积运算切分后,数据分发上会存在很大的可重用性。在这方面,TPU类的systolic计算通过集中式的数据发送可以很好的复用,以较小的数据带宽支持较大的卷积运算。为了改善eyeriss这方面的性能,V2设计了比较复杂的数据分发方式。
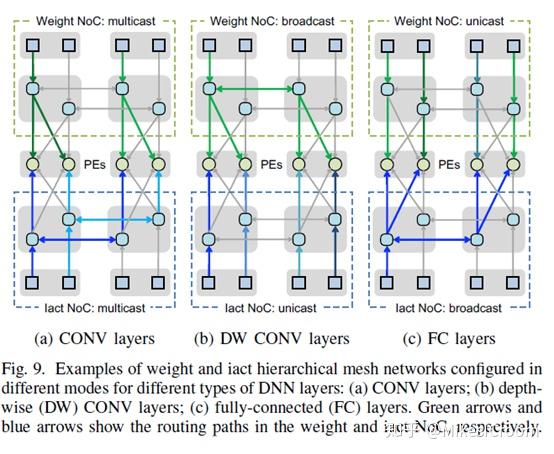
总体来说,eyeriss V2通过每个cluster内部的issue router将数据根据当前运算的不同发送到对应的PE运算单元中去。针对卷积,全连接,depth-wise convolution的运算特点设计了multicast,broadcast和unicast等多种发射方式。可以看出这种cluster内部的数据传输是比较复杂的,本质上是一个定制化的ASIC网络结构,面向特定的几种运算(主要是CNN模型)进行数据复用的加速,而并不具有较好的可编程性。
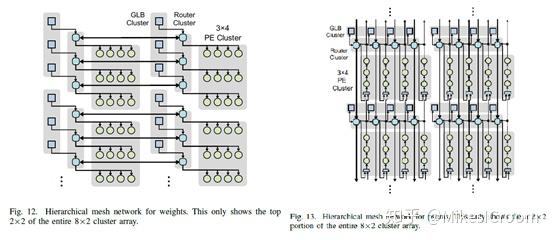
当面对cluster间的数据传递,为了有效的进行数据复用,这个结构就更复杂了。为了CNN计算中权重的传递,设计了水平传输通道,每行的权重通过广播方式传输给每个PE。为了通道间数据可以进行累加,又设计了纵向的累加通道,每个PE的一维卷积结果通过纵向累加形成两维的卷积。为了上述灵活的网络结构,cluster设计了大量的router进行控制和数据分发。这种设计更大程度上是学术上的探索,并没有太多考虑具体实现上的问题,比如逻辑复杂性,物理设计的难度,是否能满足时序,如何进行软件编程进行NOC控制等问题。而包含了上述问题的解决方案的芯片能否有效的发挥该设计的灵活性和复用性也是一个疑问。因此并不是一个可行性很好的实现方案。
eyeriss V2提出的另一点就是对稀疏矩阵的支持。稀疏性在深度学习算法中是很常见的,权重系数中本身就会包含0值,而数据经过多轮的激活操作也必然出现多个0。通常来讲,运算密度较大的结构,比如systolic,对于稀疏的运算支持都较差,最多能够做到0值不耗power,而无法将0值运算排除。这是由于systolic规则运算的结构所致。在这方面,GPU和CPU是比较有优势的,尤其是稀疏程度很高的情况下,可以通过指令的判断跳过0值运算。加速器设计上通常是针对某种特定的数据压缩算法,在数据向执行单元输入时将0值略掉,这也是一种针对性很强的ASIC设计。比如寒武纪的Cambricon X的方案(如下图),要求压缩格式以index方式,即输入数据流开头增加一个byte,里边的每个bit表示接下来的哪个byte是有值的。一个特殊的译码逻辑会用来分析这个数据流,将有效的数据和权重组合发送到执行单元中去。这种结构需要数据串行执行,并且需要根据运算排列正确,因为index模式并没有办法在任意位置获得数据对应的真实地址,而必须串行译码到该数据时才能获得。这限制了index压缩的运算规模和灵活性。
eyeriss V2使用了一个压缩程度较低的方式,但可以直接获得数据的真实地址,这样就避免了index压缩中所需要的数据预排列的过程,同时可以获取任意位置的数据。这个压缩被称为CSC(Compressed Sparse Column)。非0数据存储在一个data vector中。counter vector中的值表示对应位置的data和上一个非零data之间的0的个数。address vector中的值表示每列之前的非零数字的个数。因此如果要读取矩阵W[1,1]位置的值(即d),首先根据address vector的值,第0列有2个数,则第一列会从第三个数开始。再根据counter vector的值,第三个数C对应的count是0,表示从0位置开始的,D对应的count也是0,则表示D紧跟着C,位置index为1 。这样就获得了W[1.1]对应的值。因此一般性的步骤是通过横坐标和addr vector获得data的起始index,再根据count vector依次获得纵坐标对应的位置。可以看到单独获得纵坐标需要一个依次查找的过程。因此较大的矩阵需要首先切割成为较小的Segment,然后在Segment内部做CSC压缩,方便硬件进行坐标的译码查找。获取一行或者一列数据的方法也是差不多的逻辑。这样eyeriss V2就可以通过正常方式执行运算,只需要增加index到对应数据的译码逻辑即可,虽然增加了一组vector,但是灵活性大大增加了。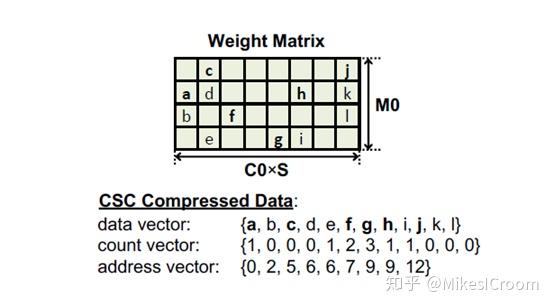 总体来说,eyeriss V2相比于V1,从单一的核内矩阵结构过渡到类似于众核的NOC结构,这也是目前大型深度学习加速器在探索的一个方向。NOC是一个比较成熟的设计,对于深度学习的应用需要着重考虑数据带宽的需求。对于其复杂的数据分发方式,可以作为参考,但并不是一个很好的实现方案。众核结构的另一个优点是对稀疏矩阵的支持,由于每个PE都是独立执行的,比较方便对输入的0值数据进行过滤,而systolic这类的运算矩阵由于需要相邻单元同步执行,且对数据格式有很强的要求,因此很难将0值数据的计算去掉。不过systolic的优势是单位面积的计算密度大,控制和本地存储非常少;而NOC由于支持复杂的数据routing以及local的data buffer和独立控制逻辑,这样纯计算单元的比例就降低了。因此如何在计算密度和稀疏性支持之间寻找一个平衡,也是深度学习加速器需要探索的一个方向。
总体来说,eyeriss V2相比于V1,从单一的核内矩阵结构过渡到类似于众核的NOC结构,这也是目前大型深度学习加速器在探索的一个方向。NOC是一个比较成熟的设计,对于深度学习的应用需要着重考虑数据带宽的需求。对于其复杂的数据分发方式,可以作为参考,但并不是一个很好的实现方案。众核结构的另一个优点是对稀疏矩阵的支持,由于每个PE都是独立执行的,比较方便对输入的0值数据进行过滤,而systolic这类的运算矩阵由于需要相邻单元同步执行,且对数据格式有很强的要求,因此很难将0值数据的计算去掉。不过systolic的优势是单位面积的计算密度大,控制和本地存储非常少;而NOC由于支持复杂的数据routing以及local的data buffer和独立控制逻辑,这样纯计算单元的比例就降低了。因此如何在计算密度和稀疏性支持之间寻找一个平衡,也是深度学习加速器需要探索的一个方向。


【1】Y.-H. Chen, T.-J. Yang, J. Emer, and V. Sze, “Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices,” arXiv Prepr. arXiv1807.07928, 2018.
【2】S. Zhang, Z. Du, L. Zhang, H. Lan, et, al. "Cambricon-X: An accelerator for sparse neural networks" Microarchitecture (MICRO), page 1--12. IEEE, (2016)
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

