
在前一篇译文中,翻译了计组黑皮书的进阶内容 5.12 章:实现一个基础 cache,并整理了代码。在本篇原创文章中,笔者将对此前整理的代码进行一番解析。此外,写一个仿真脚本,在 modelsim 10.5 上运行起来计组黑皮书提供的 testbench ,结合仿真结果,更深入了解这个简单的高速缓存模块。
转载自:知乎
相关链接
在线内容
链接:https://booksite.elsevier.com/9780124077263/appendices.php
源码整理
笔者将代码整理在 GitHub 上:https://github.com/ljgibbslf/basic\_cache\_core/tree/master/refer
结构
计组黑皮书(以下简称“书”)提供的源文件组成一个结构如下的模块。
模块结构
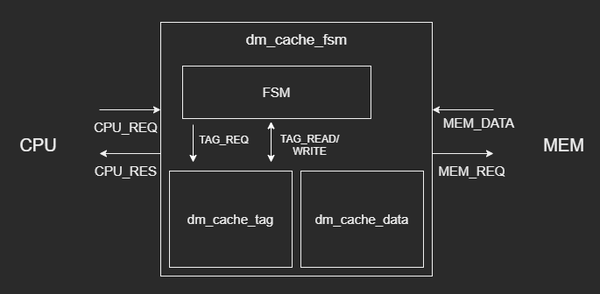
顶层模块为 dm\_cache\_fsm,其中的状态机控制了整个模块的功能,包括 cache 存储访问、主存访问、CPU请求响应等功能。在其中例化了 2 个 cache 存储模块,dm\_cache\_tag/data 模块,分别存储 cache 条目中的标签以及数据。
模块顶层按照方向分为 2 组信号,分别前往 CPU 以及主存 MEM,各自包括 1 个请求信号以及数据信号。外部信号连接至 FSM。
FSM 则通过一组 REQ 以及读写数据信号与 tag/data 模块连接,data 模块信号与 tag 模块一致,图中未画出。
仿真平台结构
配合书中提供的 testbench,搭建起一个结构如下的 cache 模块仿真验证平台。
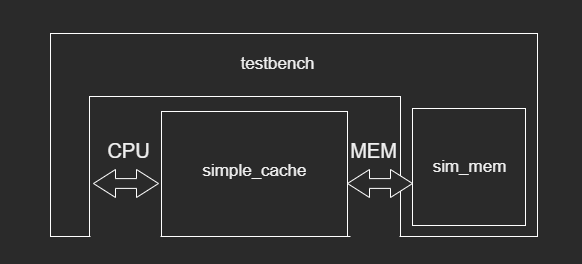
Testbench 产生 CPU 端请求信号激励,观察待测试的高速缓存模块返回 CPU 的数据。在 tb 中设计了一个“伪”主存模块 sim\_mem,使用寄存器模拟外部的主存。
CPU 请求地址结构
CPU 请求地址位宽为 32 比特,划分为 {tag,index,byte_offset}
地址的划分是本文实现的 cache 特性所决定的:
- 块大小为 4 个字,即 128 bit
- 即每个块共 16 个字节,因此 REQ\_ADDR[3:0] 为字节偏移,共 4bit
- 高 2 bit 也可被称为字偏移字段
- cache 大小为 16KB
- 即 1024 个块,需要 10bit 的 cache 索引来标识每个 cache 块, 因此 REQ\_ADDR[13:4] 为 cache 索引
- cpu 请求地址共为 32 bit
- 判断 cache 条目与请求地址是否匹配地址标签字段 tag ,位宽为 32 - 10 - 4 = 18 bit ,即 REQ\_ADDR[31:14]

模块解析
整个验证仿真平台可分为几类模块,本文依次来看
- 控制状态机 (dm\_cache\_fsm)
- 存储模块 (dm\_cache\_tag/data , sim\_mem)
- 激励产生模块(tb\_refer\_simple\_cache)
存储模块
存储模块中开辟了一段寄存器空间,根据读地址返回相应的寄存器数据。在写使能有效的情况下,将写数据写入寄存器,代码如下:
module dm_cache_data(
input bit clk,
input cache_req_type data_req,//data request/command, e.g. RW, valid
input cache_data_type data_write, //write port (128-bit line)
output cache_data_type data_read
); //read port
timeunit 1ns; timeprecision 1ps;
cache_data_type data_mem[0:1023];
// initial begin
// for (int i=0; i<1024; i++)
// data_mem[i] = '0;
// end
assign data_read = data_mem[data_req.index];
always_ff @(posedge(clk)) begin
if (data_req.we)
data_mem[data_req.index] <= data_write;
end
原代码中的 initial 块会在笔者的仿真环境中报错:
data\_mem 变量在超过一个过程块中被赋值
不知道是否在其他仿真环境,或者不同的仿真设置支持这种写法,欢迎读者在评论区指出。
sim\_mem 模块基本代码与上述模块类似,增加了一个可配置的读写访问延迟 MEM\_DELAY,用于模拟主存的延迟。
localparam MEM_DELAY = 100;
....
##MEM_DELAY;
if (req.rw)
mem[req.addr] = req.data;
else begin
data.data = mem[req.addr];
end
....
控制状态机
状态机初始化
在状态机空闲状态时,为各信号赋初值。置低 tag/data 两个缓存模块的写使能信号,并将索引信号与 CPU 端口的地址信号相关字段连接。
另一方面,为主存接口信号准备写入地址与数据。
/*-------------------------default values for all signals------------*/
/*no state change by default*/
vstate = rstate;
v_cpu_res = '{0, 0}; tag_write = '{0, 0, 0};
/*read tag by default*/
tag_req.we = '0; /*direct map index for tag*/
tag_req.index = cpu_req.addr[13:4];
/*read current cache line by default*/
data_req.we = '0;
/*direct map index for cache data*/
data_req.index = cpu_req.addr[13:4];
/*memory request address (sampled from CPU request)*/
v_mem_req.addr = cpu_req.addr;
/*memory request data (used in write)*/
v_mem_req.data = data_read;
v_mem_req.rw = '0;
主存接口的位宽为 4 个字,由于 CPU 接口位宽为 1 个字,因此每次只要修改主存中的单个字。在实现中,首先读取主存该地址上的数据,data\_read,然后根据 CPU 请求地址的字偏移(cpu\_req.addr[3:2]),修改单个字后组成写入主存的数据:data\_write。
同理,在 4 个字的读数据中,根据 CPU 请求地址的字偏移字段,每次只返回 CPU 单个字。
/*modify correct word (32-bit) based on address*/
data_write = data_read;
case(cpu_req.addr[3:2])
2'b00:data_write[31:0] = cpu_req.data;
2'b01:data_write[63:32] = cpu_req.data;
2'b10:data_write[95:64] = cpu_req.data;
2'b11:data_write[127:96] = cpu_req.data;
endcase
/*read out correct word(32-bit) from cache (to CPU)*/
case(cpu_req.addr[3:2])
2'b00:v_cpu_res.data = data_read[31:0];
2'b01:v_cpu_res.data = data_read[63:32];
2'b10:v_cpu_res.data = data_read[95:64];
2'b11:v_cpu_res.data = data_read[127:96];
endcase
状态机状态跳转
cache 控制状态机共包括 4 个状态:
- IDLE 空闲状态
- Compare Tag 标签比较状态
- Allocate 高速缓存分配状态
- Write-Back 写回状态

Image
IDLE状态
状态机在 rst 复位信号有效后,回到初始 IDLE 状态。
always_ff @(posedge(clk)) begin
if (rst)
rstate <= idle; //reset to idle state
else
rstate <= vstate;
end
而在 CPU 端产生有效的访问请求后,转至 Compare Tag 状态。
idle : begin
/*If there is a CPU request, then compare cache tag*/
if (cpu_req.valid)
vstate = compare_tag;
end
Compare Tag 状态
Compare Tag 状态根据 CPU 的请求,比较高速缓存的标签,检查 cache 请求是否命中,是最重要的一个状态。
首先,本文实现采用直接映射的 cache 组织方式,请求地址中的部分字段会唯一映射至 cache 索引,具体地,即
INDEX\_CACHE = REQ\_ADDR[13:4]
在 dm\_cache\_tag 模块中,读取该索引位置上 cache tag,如果其中的地址标签与请求地址匹配,且该 cache 条目有效(valid 位置高),则代表 cache 命中(cache hit),cache 中保存的正是该地址上的一个副本。
cache hit 后的读操作中,cache index 送入 dm\_cache\_data 存储模块,获得缓存条目的数据,返回给 CPU。
而写操作中,同样以 cache index 为地址,将 CPU 写数据送入 dm\_cache\_data 存储模块,并置高写使能完成写入。由于采取写回策略,对于 cache 的修改不会马上写入主存,因此置高 dirty 位,表示 cache 中的内容已经与主存不一致。
/*compare_tag state*/
compare_tag : begin
/*cache hit (tag match and cache entry is valid)*/
if (cpu_req.addr[TAGMSB:TAGLSB] == tag_read.tag && tag_read.valid) begin
v_cpu_res.ready = '1;
/*write hit*/
if (cpu_req.rw) begin
/*read/modify cache line*/
tag_req.we = '1; data_req.we = '1;
/*no change in tag*/
tag_write.tag = tag_read.tag;
tag_write.valid = '1;
/*cache line is dirty*/
tag_write.dirty = '1;
end
/*action is finished*/
vstate = idle;
end
如果 cache 索引指向的条目中,地址标签与请求地址不匹配,或者该条目干脆无效,则 cache 条目中没有存放我们要的东西,称为 cache 未命中(cache miss)。根据 dirty 位的不同情况分为两种处理方式:
- dirty 位使能,需要先将该条目的数据写回主存后,再重新利用该单元,转至写回状态
- dirty 位无效,转入缓存分配状态,重新利用该单元
Write-Back 写回状态
向主存发出写入请求,等待原内容写入主存后,转入缓存分配状态,重新利用该单元。
/*wait for writing back dirty cache line*/
write_back : begin
/*write back is completed*/
if (mem_data.ready) begin
/*issue new memory request (allocating a new line)*/
v_mem_req.valid = '1;
v_mem_req.rw = '0;
vstate = allocate;
end
end
Allocate 高速缓存分配状态
/*wait for allocating a new cache line*/
allocate: begin
/*memory controller has responded*/
if (mem_data.ready) begin
/*re-compare tag for write miss (need modify correct word)*/
vstate = compare_tag;
data_write = mem_data.data;
/*update cache line data*/
data_req.we = '1;
end
end
该状态从主存中读取新的数据至 cache 中,值得注意的是,在完成新数据读取后,再次转入了标签比较状态,这是出于 write miss 的用途。
在写未命中情况下,首先转至 Allocate 状态,将写地址上的内容读取到 cache 中,然后在Compare Tag 状态中对 cache 中的内容进行修改,完成未命中情况下的写操作。自然,该 cache 块自动变脏了。
激励产生模块
该模块中通过直接赋值的方式,产生各种 CPU 读写请求,仿真 cache 在各种情况下的响应,比如读取 {0x1234,0x2,0x0} 地址。
cpu_req.rw = '0;
cpu_req.addr[13:4] = 2; //index 2
cpu_req.addr[31:14] = 'h1234;
cpu_req.valid = '1;
$display("%t: [CPU] read addr=%x", $time, cpu_req.addr);
wait(cpu_res.ready == '1);
$display("%t: [CPU] get data=%x", $time, cpu_res.data);
cpu_req.valid = '0;
##5;
采用 {tag,index,byte_offset} 的形式表示地址。
仿真
脚本与运行
笔者为书中简单的 cache 模块编写了一个 modelsim 的运行 do 脚本,在 win 平台上可以直接运行一个 bat 脚本启动仿真。这些脚本都位于 github 仓库的 sim 目录中。
笔者在 modelsim 10.5 环境测试中,发现黑皮书提供的 testbench 似乎有一些问题,导致仿真运行失败。
最主要的似乎是将 cpu 写为了 ui,导致无法直接仿真,因此笔者对 testbench 做了一些修改后,成功运行了仿真。
仿真结果分析
仿真平台共产生了 6 次读写请求,各请求的地址、测试点如下表所示

结语
本文分析了简单 cache 模块的代码结构以及仿真结果,在后续的文章中,将在简单 cache 的基础上进行扩展,包括支持 cache 容量、块大小等等参数的可定制化,支持更多的 cache 组织方式,以及 cache 替换策略。
推荐阅读
- 深入 AXI4 总线(E0)实战:平台搭建
- 可重构计算:基于FPGA可重构计算的理论与实践 1.器件架构 译文(三)
- 可重构计算:基于FPGA可重构计算的理论与实践 1.器件架构 译文(二)
- 可重构计算:基于FPGA可重构计算的理论与实践 1.器件架构 译文(一)
关注此系列,请关注专栏FPGA的逻辑

