
转载自:知乎
作者:ljgibbs
本期我们将讨论 DRAM 的训练特性之一 —— write leveling。
基于 JESD79-48 / 4.7 节
本系列连载于 OpenIC SIG,除了 DDR 学习时间专栏外,OICG 目前正在陆续上线 HDLBits 中文导学的优化版本,欢迎关注/支持/加入我们
DDR 学习时间 - OpenIC SIG 开源数字IC技术分享
DRAM Training : write leveling
深度学习真的改变了我们的生活,至少当我们说到 DRAM Training 时,自然而然地需要解释下这里不是深度学习的那种 training。
DRAM training 可以认为是一种”自适应调整“,用来克服 DRAM 拓扑、以及与系统连接时引入的不确定性。而 write leveling 是其中的一个训练项目。
DDR fly-by 拓扑结构
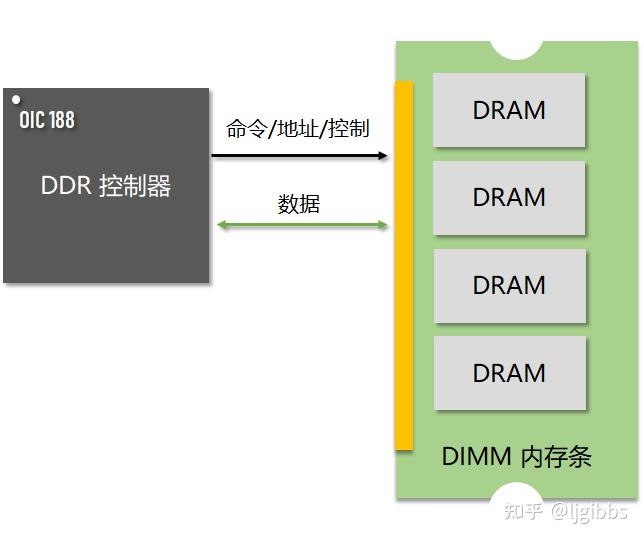
上图是一个包含 DRAM 的系统,系统中的 DDR 控制器与 DRAM (具体地说是 DIMM 内存条)之间共有 2 组信号,分别为
- 命令、地址、控制总线以及时钟
- 数据总线
DRAM 组件,比如 DIMM 内存条,由多个 DRAM 芯片组成。数据总线连接到各自的 DRAM 芯片即可,而命令地址总线以及时钟信号则需要复制多份,连接每个 DRAM 芯片。
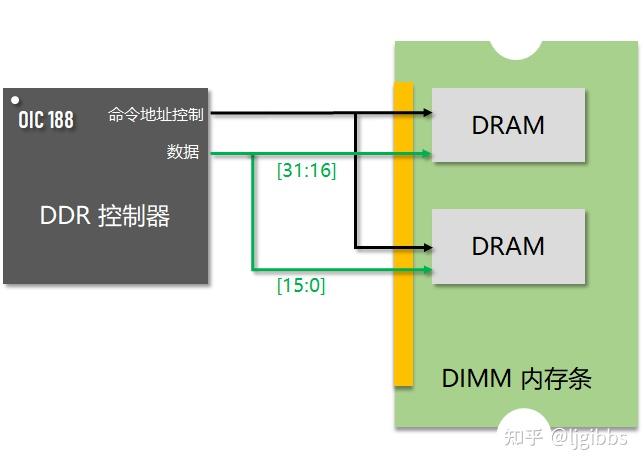
以上图举个例子,DIMM 内存条包括 2 个 x16 DRAM 颗粒,控制器的数据划分为 2 个部分,分别连接至两个 DRAM 芯片。命令地址总线则被复制为两份驱动 2 个 DRAM 芯片。
上图中地址和数据总线连接均采用星型拓扑,会导致控制器与 DIMM 之间有大量的信号线连接,一个包含 N 个 DRAM 颗粒的内存条需要 N 个命令地址和时钟接口,这产生了一些糟糕的问题:
- 影响时钟的信号完整性,降低 DRAM 运行频率
- 接口太多导致 DIMM 内存条成本上升
因此,DDR4 为多 DRAM 芯片系统设计了 fly-by 的命令地址总线拓扑,数据仍然采用星型拓扑,如下图所示。命令地址总线从控制器连接至第一个 DRAM 芯片,再从其出发连接第二个 DRAM 芯片,以此类推。fly-by 拓扑通过减少命令地址总线在 DIMM 上的接口,以及走线长度与复杂度,改善了信号完整性和成本的问题。
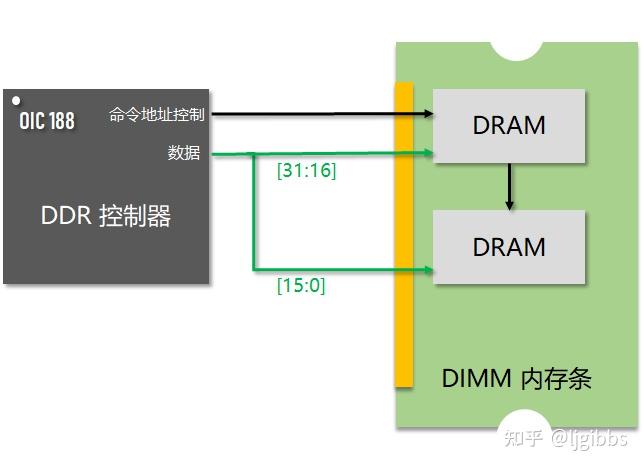
为什么需要 write leveling
显然,在 fly-by 结构中,命令地址信号到达每个 DRAM 的时间有很大不同。但是数据到达每个 DRAM 的时间却是接近的,这会导致每个 DRAM 时钟信号(随命令地址总线传输)和数据的偏差不一致。
从原理上说,对于单个 DRAM 时钟与其数据之间的偏差,这些偏差一般为固定的走线偏差,控制器采用调整时钟或者数据的延迟链来补偿偏差。
但对于多个 DRAM 芯片组成的系统而言,调整单个 DRAM 是不够的。由于每个 DRAM 的时钟-数据偏差不同,而且控制器还不知道具体每个 DRAM 的偏差是多大!这样一来,控制器就无法在整个 DIMM 内存条(DRAM 系统)层面上保持 tDQSS,tDSS,tDSH 等时序参数。
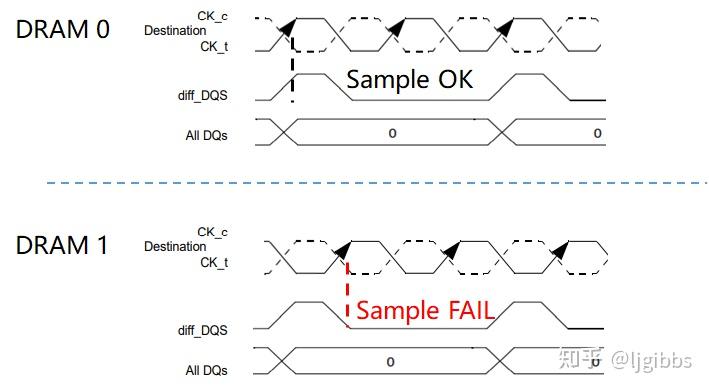
如下图所示,两个 DRAM 的数据信号几乎同时到达,但时钟信号有一定的偏差,即使在调整 DRAM0 的 DQS 信号的延迟,使 DRAM 0 可以完成数据采样后,DRAM 1 仍然无法完成采样。
为了克服时钟与数据之间的偏差在每个 DRAM 颗粒上的不确定性,DRAM 需要进行 write leveling ,针对每个 DRAM 芯片量身训练一个时钟与数据之间的偏差补偿。时钟选取 CK 信号本身,而数据则选取 DQS 信号来表示,DQS 是数据有效信号,这里暂且认为其与真正的数据信号 DQ 是完全同步的。
所以 write leveling 会针对每个 DRAM 芯片,进行 CK 与 DQS 信号间的相位调整,采用一种多次试错,寻找最优值的方法使 DRAM 接收到的时钟信号与写数据同步。
这里强调 write leveling 是一项每个 DRAM 芯片层面上的训练项目,是因为还有其他训练项目会对 DRAM 芯片内部的不同组成部分进行训练。不过严格来说 write leveling 是针对每个 lane 进行训练的,这里简单起见,选用 x8 DRAM 作为例子,一个 DRAM 芯片只对应于一个 lane。如果是 x16 的颗粒,那么其 2 个 byte lane 需要分别训练。
进行 write leveling
write leveling 由 DDR 控制器 (MC) 完成,目标是通过改变发出 DQS 信号的延迟,使 DRAM 接收到的 DQS 信号与 CK 信号同步,即两者边沿对齐。
但 write leveling 也需要 DRAM 相应特性的支持。因为是 write leveling 的目的是 DRAM 处采样得到的时钟-数据信号同步,所以 write leveling 需要 DRAM 告知控制器自己采样信号的同步状况。
那么接下来我们就从 MC 和 DRAM 两方来看看 write leveling 这个小剧场故事:
[MC]
有人给 MC 介绍了一个朋友:DRAM0(我们暂时就叫 ta DRAM)。
MC 约 DRAM 出来聊天(MC 配置 DRAM 进入 write leveling 模式 )
[MC]
现在 MC 对 DRAM 是一问三不知的:
- 家里住哪片,远不?(好比源时钟到目的端延迟)不知道。
- 开车比公交快多少?(好比数据与时钟相对偏差)不知道。
- 人怎么样?(好比读写功能是否正常,不过这个和 write leveiling 没关系,^\_^)不知道。
MC 只能在首次尝试中,试探性地给 DQS 一个相对时钟 CK 的延迟,比如 0, 即 DQS 与 CK 同步发出。
[DRAM]
DRAM 对 MC 也是一无所知的,但 ta 不 care 很多东西。
MC 叫我进入 write leveling 模式,我就进,但我具体应该干些什么呢?
MC 告诉我需要在 DQS 信号上升沿采集 CK 的状态,并把 CK 的高低电平状态,通过 DQ 信号回传给 MC。
[MC]
很好,DRAM 返回了一个 CK 在 DQS 上升沿的采样值,是 0。看来目前 DQS 对应的是 CK 的低电平。
MC 的目标是让 DQS 上升沿与 CK 同步,即采样到 CK 值从 0 到 1 的跳变。很好,加大 DQS 相对 CK 的延迟,冲!
[DRAM]
采样,返回采样值
[MC]
采样值还是 0,这还得加大延迟啊。
LOOP ....
[MC]
采样值变 1 了,搞定了!
成功地捕捉到了 CK 的上升沿,让 DQS 与 CK 的上升沿对齐了!记录此时 DQS 的延迟值,对应于 DRAM0 接收到的 CK 信号上升沿。
很好,DRAM0 搞定,去认识下一位 DRAM 朋友: DRAM1,再见 DRAM0!
我必须要继续出发,去认识所有系统中的 DRAM。(遍历系统中所有的 DRAM(以 RANK 为单位),完成 write leveling)
[DRAM0]
???
write leveling 小剧场到这里就告一段落,接下来我们通过时序图来进一步了解这个过程。
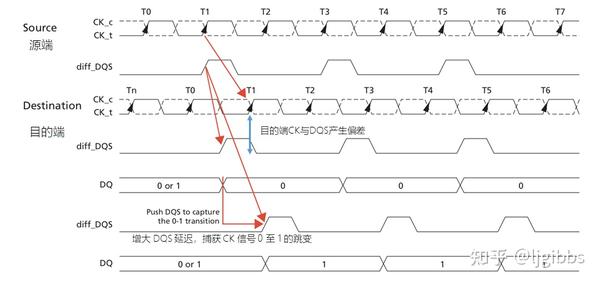
源端同步发送的时钟信号 CK 和数据有效信号 DQS 在接收端出现了偏差,一般来说时钟信号会更滞后一些。从 DRAM 端返回的 DQ 值为 0,表示 DQS 上升沿时 CK 信号为低电平。
源端 MC 根据 DQ 数值,继续加大 DQS 的延迟,直至 DQ 值为 1,此时 DQS 上升沿时 CK 信号为高电平。再略微将延迟调小,MC 就捕捉到了 CK 的上升沿,记录此时的 DQS 延迟值,就完成了 DQS (数据)与 CK 的同步。
DRAM write leveling 模式
MC 通过配置 MR1 寄存器 write leveling enable,可以使 DRAM 进入 write leveling,返回 DQS 上升沿时 CK 的采样值。

因为 MC 以 RANK 为单位进行 write leveling,而 RANK 之间共用数据通道,因此 Ouput buffer mode 用于关闭不在进行 training 的 RANK,让他们让出 write leveling 的通道。
write leveling 关键时序
tDQSS,tDSS,tDSH
此三者都是 write leveling 调整的最终目的。tDQSS 是 DQS 上升沿相对 CK 上升沿的偏差,DDR4 要求两者的偏差在 ±0.27 个 tCK 范围内,这也是 write leveling 精度的参照。

tDSS,tDSH 分别是 DQS 信号下降沿相对于 CK 上升沿的建立和保持时间。建立或者保持时间的违例会导致 DQS 采样失败。一般来说,当 tDQSS 调整到位时,这两者也就一起到位了,无需特别的调整。
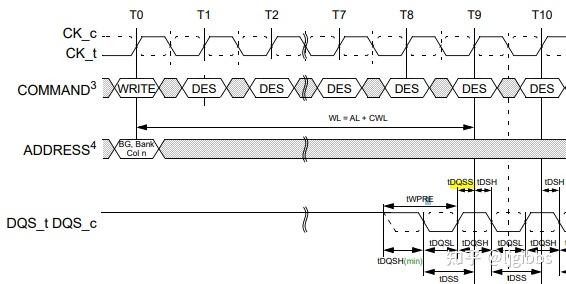
tWLMRD
根据名字可以看出,这是 write leveling 的专属参数。
在 MC 配置 DRAM MR,使之进入 write leveling 模式后,经过 tWLMRD 后,MC 开始发出第一个用于 write leveling 的 DQS 脉冲。
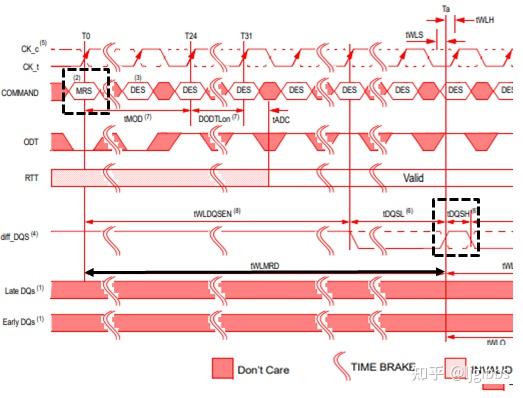
tWLO/tWLOE
DRAM 在 DQS 采样 CK 值后,通过 DQ 返回采样值,这里需要注意的是,返回采样值是一个异步的操作。DRAM 会在采样后的 tWLO 时刻返回采样值。
协议规定,DQ 的所有比特都会返回一个相同的值,但这些比特的跳变时间之间有一个偏差,这个偏差的最大值是 tWLOE。
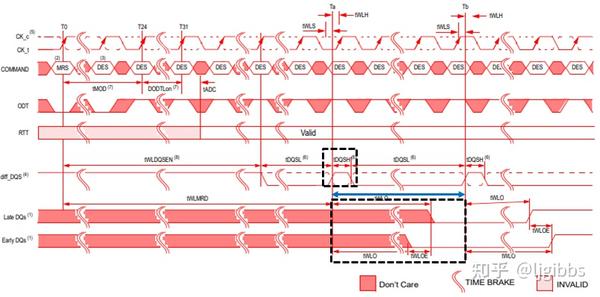
什么时候不需要 write leveling
如果 DRAM 颗粒的类型、信号线的长度、DRAM 颗粒间的拓扑关系都是固定的,那么控制器使用提前设定的参数,即可以保持 tDQSS,tDSS,tDSH 等时序参数,无需 write leveling。
这种情况一般出现在定制的嵌入式系统中。举个例子
- 苹果的 A 系列手机处理器芯片只提供给自家的产品使用,无需适配第三方客户设计。
- 量产产品基本也只会有一种主要的 PCB 设计,因此走线延迟是可知的。
- 内存颗粒可能也就是一到两种型号。
所以对 A 系列处理器来说,涉及 DDR 时钟-数据的延迟因素都是事先可知的,写入 DDR 驱动中按需使用即可。
与此相对的,Intel 的 CPU 需要适配有几十家厂商、上百种主板、上百种 DIMM 内存条、几十种颗粒类型,穷举这些参数写死在驱动中是很困难、容易过时的,那么诸如 write leveling 这样的内存训练就是必须的。
结语
本期我们讨论了:
- 为什么需要 write leveling ?
- DDR4 时钟采用 fly-by 拓扑结构,需要 write leveling 消除不同 DRAM 上,时钟与数据到达时间之间的不确定性
- write leveling 是如何进行的?
- MC 基于 DRAM 返回的 DQS 上升沿 CK 采样值,调整 DQS 延迟,使 DQS 与 CK 上升沿对齐
- write leveling 的关键时序参数
- 哪些场景不需要 write leveling?
- DRAM 走线延迟、拓扑都已知且确定的设计,MC 使用预置参数即可维持 DQS 与 CK 的时序关系
- 多见于一些定制嵌入式系统中
- *
关于作者
ljgibbs , 主业是某 Fabless 的 SoC Designer,业余时间是 OpenIC SIG 专栏作者与开源开发者。
感兴趣的领域包括:AXI 等片上总线、DDR、嵌入式系统与计算机架构、FPGA 、计算机网络通信、半导体行业与市场、翻译&写作、电影&历史。
关于《DDR 学习时间》专栏
在 DDR 学习时间专栏中,目前有两个 Part:
- Part-A DRAM 课程、论文以及其他在线资源的学习
- Part-B 基于 DDR4 Spec 的 DDR 特性学习
计划开设第三个 Part
- DDR 仿真与实例
关于连载《DDR 学习时间》专栏的 OpenIC SIG
OpenIC SIG(简称 OICG),开源数字 IC 特别兴趣小组,致力于分享开源项目与知识。
欢迎关注/支持/加入我们!contact\_us@digitalasic.design
DDR 学习时间 - OpenIC SIG 开源数字IC技术分享
推荐阅读
- DDR 学习时间 (Part B - 2):DRAM 自刷新
- DDR 学习时间 (Part B - 1):DRAM 刷新
- 开源仿真器 EpicSim 运行 SM3_core
- DDR 学习时间 (Part A - 1):一篇 2002 年的 DDR 控制器设计硕士论文
- HDLBits:在线学习 Verilog (三十二 · Problem 155-159)
关注此系列,请关注专栏FPGA的逻辑

