
文章转载于:知乎
作者:金雪锋
麻省理工学院(MIT)提出的自动微分框架 Enzyme 在 NeurIPS 2020 大会上引起过不少人的兴趣,最近也简单分析一下,供参考。
概述
当前对于将新领域,例如物理模拟、游戏引擎、气候模型等,引入到机器学习中来,存在一个普遍问题--求梯度时,需要将外来代码通过源码重写或者操作符重载,以融入现有AD(automatic differentiation自动微分)工具(Adept、Autograd等)或深度学习框架(TensorFlow、PyTorch、MindSpore等),这增加了在机器学习工作流中引入外来代码的工作量。而MIT的这篇论文提出了Enzyme,一个基于LLVM IR的自动微分编译器插件,来缓解该问题。Enzyme可以生成用LLVM IR表达的静态可分析程序的梯度。
Enzyme的关键点:
- 可以自动生成基于静态可分析的LLVM IR的梯度。
- 在优化后的IR上做自动微分,以得到一个高性能的梯度计算。
设计
1、类型分析
LLVM IR没必要表示出所有数据的潜在类型,所以Enzyme做了一些自己的抽象解析。如引入类型树,实现了一个类型传播规则。
2、活动分析
分析出哪些指令对梯度计算有影响以及哪些指令是不可微分的,从而减少不必要的计算。
3、影子内存
对于正向部分需要计算的数据,Enzyme会复制一份影子内存,用于保存梯度计算结果,一直到梯度计算不需要时才会释放。
4、合成梯度
根据类型和活动分析的结果,创建梯度函数,梯度函数包括正向部分和反向部分。

5、缓存
Enzyme在计算反向部分时,如果需要正向部分的结果,默认情况下会重新计算正向。但是对于不可能重新计算的操作(如Read)或效率低的操作,Enzyme也提供了缓存机制保存正向结果用于计算反向部分。
6、生成高性能的梯度计算
Enzyme是在优化过的LLVM IR上做AD的。论文给出了一个在LICM(loop-invariant code motion)优化后做AD的如下例子,相比于在AD之后做LICM,计算复杂度有一个O(N^2)到O(N)的提升。

Top:一个O(N^2)的norm函数,如果使用loop-invariant-codemotion (LICM)把mag函数提出来,能够将复杂度优化到O(N)。Left:执行LICM之后做AD,得到的一个O(N)的 ∇norm函数。Right:在AD之后执行LICM,得到的一个O(N^2)的 ∇norm函数,∇mag仍然在循环内部,因为它使用了循环内部的一个值,LICM并不生效。
下图为论文给出的在不同的benchmark上,Enzyme与其他自动微分工具的性能对比。其中,Ref是Enzyme在优化前做AD的一个对比实验组,与Ref相比,每个benchmark平均下来,在优化后做AD,有4.5倍的性能提升。
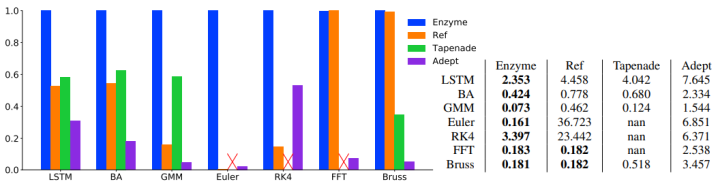
注:这个性能对比主要还是和同等LLVM AD工具比
Left:不同的AD系统在benchmark上的相对加速比,柱状越高的越好。值1.0表示当前benchmark上最快的AD系统,值0.5表示该AD系统生成的梯度计算,花费的时间是最快的2倍。Right:以秒为单位的几何平均运行时间。

Enzyme和Ref两条流水线,在AD前后执行优化的情况
Enzyme的使用
要生成基于LLVM语言的代码梯度,需要调用一个外部函数\_\_enzyme\_autodiff。

以C程序为例,求一个函数的梯度:
- 准备一个C程序
// test.c
#include <stdio.h>
extern double __enzyme_autodiff(void*, double);//extern funciton
double square(double x) {
return x * x;
}
double dsquare(double x) {
// This returns the derivative of square or 2 * x
return __enzyme_autodiff(square, x);
}
int main() {
for(double i=1; i<5; i++)
printf("square(%f)=%f, dsquare(%f)=%f", i, square(i), i, dsquare(i));
}2. 使用clang生成llvm ir
clang test.c -S -emit-llvm -o input.ll -O2 -fno-vectorize -fno-slp-vectorize -fno-unroll-loops3. 使用Enzyme生成梯度
opt input.ll -load=/path/to/Enzyme/enzyme/build/Enzyme/LLVMEnzyme-<VERSION>.so -enzyme -o output.ll -S4. 进行AD后的优化并生成可执行文件
clang output.ll -O3 -o a.exe另外,在做AD时,Enzyme需要获取所有需要微分函数的IR。如果只是一种源代码的IR很容易获得,对于多种源代码或者使用外部库的代码,Enzyme使用Link-Time Optimization (LTO)--一种用于整个程序优化的编译器技术,保留所有源文件的IR一直到链接阶段。为了在多种源代码的代码库中使用,使能LTO,在合并的IR上运行Enzyme,对于静态库可以在编译时加上-fembed-bitcode命令,使得在静态库里面包含中间代码。
目前看Enzyme还支持CPU。
Enzyme在ML框架的应用
根据上述使用Enzyme的方法,借助AI框架的自定义算子能力,可以把Enzyme内嵌到各种框架中,以MindSpore为例:
借助MindSpore自定义算子的能力把Enzyme嵌入到MindSpore中去使用:
自定义算子(CPU) - MindSpore r1.1 documentationwww.mindspore.cn
方法如下:
- 自定义正向算子Enzyme,其中算子实现为根据外来源代码路径,调用clang去生成外来源代码的.so,并通过dlfcn库加载该.so,根据函数名去获取并调用正向函数。
- 自定义反向算子EnzymeGrad,其中算子实现为根据外来源代码路径,调用clang和enzyme去生成外来源代码经过AD的.so,并通过dlfcn库加载该.so,根据函数名去获取并调用梯度函数。
- 定义反向传播函数(bprop),函数的计算逻辑为调用自定义好的反向算子EnzymeGrad。
- 定义正向网络,网络中调用自定义好的Enzyme算子。最后根据正向网络调用GradOperation函数求梯度,就可以使用Enzyme生成梯度了。
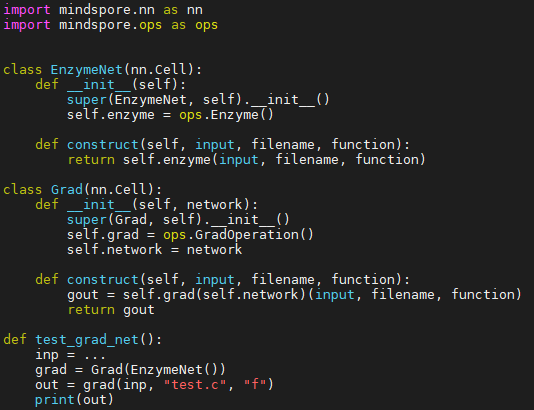
当然现在Enzyme也已经可以应用到Pytorch或TF中。
主要结论:
- Enzyme提供了一种梯度计算的性能提升方法:在某些优化完成之后才进行AD。
- Enzyme能在低级别的LLVM IR上进行AD,非常方便嵌入现有的框架。
论文地址:https://arxiv.org/pdf/2010.01709.pdf
github地址:https://github.com/wsmoses/Enzyme
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

