
内容导读北京时间 3 月 4 日,PyTorch 官方博客发布 1.8
版本。据官方介绍,新版本主要包括编译器和分布式训练更新,同时新增了部分移动端教程。
整体来看,本次版本更新涵盖 1.7 版本发布以来,共计 3,000 多次 commit,包括编译、代码优化、科学计算前端 API 以及通过 pytorch.org 提供的二进制文件支持 AMD ROCm。
同时 PyTorch 1.8 还为管道和模型并行的大规模训练,进行了功能改进和梯度压缩。

其中一些重点更新包括:
- 通过
torch.fx,可进行 python 之间的函数转换; - 增加/调整 API,以支持 FFT(
torch.fft)、线性代数函数(torch.linalg),支持复杂张量自动求导(autograd),并提升了计算 hessian 和 jacobian 的性能表现; - 对分布式训练进行了重大更新和改进,包括:改进 NCCL 可靠性,支持管道并行,RPC 分析,支持添加梯度压缩的通讯 hooks。
在 PyTorch 1.8 中,官方对一些 PyTorch 库也进行了重大更新,包括 TorchCSPRNG、TorchVision、TorchText 和 TorchAudio。
新增及更新 API
新增及更新 API 包括:与 NumPy 兼容的额外 API,及在推理和训练时方面,提高代码性能的额外 API。
以下为 PyTorch 1.8 主要更新功能的简介。
[稳定版] Torch.fft 将支持高性能 NumPy 中的 FFT
PyTorch 1.8 中发布了 torch.fft 模块。该模块在实现 NumPy np.ft 功能的同时,还支持硬件加速和 autograd。
[测试版] torch.linalg 将支持 NumPy 中的线性代数函
torch.linalg 以 NumPy np.linalg 为原型,为常见的线性代数运算提供与 NumPy 类似的支持,包括 Cholesky 分解、行列式、特征值等。
[测试版] 利用 FX 进行 Pthon 代码转换
FX 使得开发者可以通过 transform(input_module : nn.Module) -> nn.Module 进行 Python 代码转换,输入 Module 实例,得到转换后的 Module 实例。
分布式训练
为了提高 NCCL 稳定性,PyTorch 1.8 将支持稳定的异步错误/超时处理;支持 RPC 分析。此外,还增加了对管道并行的支持,并可以通过 DDP 中的通讯钩子进行梯度压缩。
详情如下:
[测试版] 管道并行
提供一个易于使用的 PyTorch API,可将管道并行作为训练循环的一部分。
[测试版] DDP 通讯钩子
DDP 通讯钩子(communication hook)是一个通用接口,通过在 DistributedDataParallel 中覆盖 vanilla allreduce 来控制 worker 之间的梯度通讯。
PyTorch 1.8 新增部分内置的通讯钩子,如 PowerSGD,用户可以按需调用。此外,通讯钩子接口还支持用户自定义通讯策略。
分布式训练的附加原型功能
除了在稳定版和测试版中新增的分布式训练功能外,Nightly 版本中也相应增加了部分功能。
具体如下:
**[Prototype] ZeroRedundancyOptimizer
[Prototype] 进程组 NCCL 发送/接收
[Prototype] RPC 中用 TensorPipe 支持 CUDA
[Prototype] 远程模块**
PyTorch 移动端
PyTorch 1.8 中为新用户提供了多个移动端教程,旨在帮助新用户更迅速地将 PyTorch 模型部署在移动端。
同时为老用户提供开发工具,让其更得心应手地用 PyTorch 进行移动端开发。
PyTorch 移动端新增教程包括:
- iOS 端用 DeepLabV3 进行图像分割
- Android 端用 DeepLabV3 进行图像分割
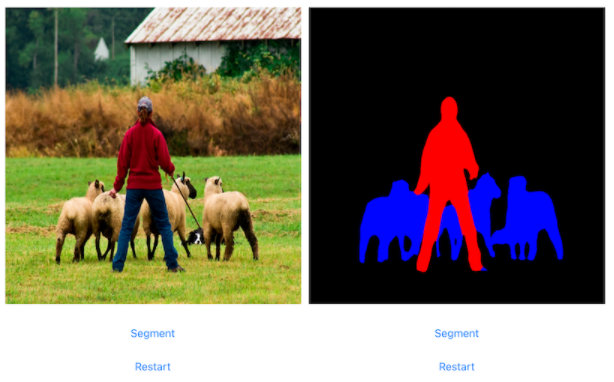
iOS 端用 DeepLabV3 进行图像分割
新增 demo APP 还包括图像分割、目标检测、机器翻译、智能问答等(iOS & Android)。
除了在 CPU 上对 MobileNetV3 等模型进行性能提升外,官方还对 Android GPU 后台原型进行了改造,以覆盖更多机型、进行更快速的推理。
另外,PyTorch 1.8 还推出了 PyTorch Mobile Lite 解释器功能,允许用户减少运行时二进制文件的大小。
[Prototype] PyTorch Mobile Lite Interpreter
PyTorch Lite Interpreter 是 PyTorch runtime 的精简版,可在空间受限的设备中执行 PyTorch 程序,并减少二进制文件对存储空间的占用。
与当前版本中的设备运行时相比,这一功能可减少 70% 的二进制文件大小。
性能优化
PyTorch 1.8 中新增对 benchmark utils 的支持,使用户能够更轻松地监控模型性能。另外还新开放了一个自动量化 API。
[测试版] Benchmark utils
Benchmark utils 允许用户进行精确的性能测量,并提供组合工具,帮助制定基准和进行后期处理。
代码示例:
from torch.utils.benchmark import Timer
results = []
for num_threads in [1, 2, 4]:
timer = Timer(
stmt="torch.add(x, y, out=out)",
setup="""
n = 1024
x = torch.ones((n, n))
y = torch.ones((n, 1))
out = torch.empty((n, n))
""",
num_threads=num_threads,
)
results.append(timer.blocked_autorange(min_run_time=5))
print(
f"{num_threads} thread{'s' if num_threads > 1 else ' ':<4}"
f"{results[-1].median * 1e6:>4.0f} us " +
(f"({results[0].median / results[-1].median:.1f}x)" if num_threads > 1 else '')
)
1 thread 376 us
2 threads 189 us (2.0x)
4 threads 99 us (3.8x)[Prototype] FX Graph Mode Quantization
FX Graph Mode Quantization 是 PyTorch 中新增的自动量化 API。它通过增加函数支持和自动化量化过程,改进 Eager Mode Quantization。
硬件支持
[测试版]强化 PyTorch Dispatcher 的能力,改善 C++ 中后端开发体验
PyTorch 1.8 支持用户在 pytorch/pytorch repo 之外创建新的树外(out-of-tree)设备,并与本地 PyTorch 设备保持同步。
[测试版] AMD GPU 二进制文件现已推出
PyTorch 1.8 新增对 ROCm wheel 的支持,用户只需根据标准 PyTorch 安装选择器,安装选项选择 ROCm,然后执行命令,即可轻松上手使用 AMD GPU。
教程及文档详情,请访问以下链接查看:

