
转载于:知乎
作者:金雪锋
最近Google出了一篇关于超大模型pipeline并行训练的论文《_TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models_》,小伙伴们分析了一下,分享出来,供大家参考。
背景:大语言模型进行训练时,通常需要使用大sequence length来保持住语言序列中的长依赖情况,然而大sequence length的内存开销比较大,就需要用更小的minibatch来训练,才能保证切分后的模型内存开销足够小,能够放的进设备中去。Gpipe并行,minibatch越小,pipeline stage中间的空闲bubble就越大,导致并行加速比降低。论文提出了一种在sequence维度进行更细粒度pipeline并行的计算方法,可以显著提高训练性能。
Opportunity:Transformer是多层Layer堆叠而成,每层layer包含SelfAttention和FeedFroward操作。
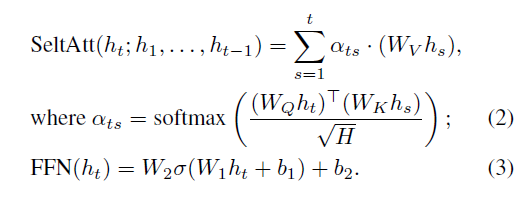
h\_i是hidden state, 对应着input sequence中的每个position。SelfAttention的计算只依赖于t之前的hidden state,而FeedFroward只依赖于h\_t自己。它们都不依赖于未来的hidden state,这样的结构使得把input sequence切开并行成为可能。也就是在Transformer结构中,当前layer处理当前token时,下一个layer处理上个token。如下图中(c)和(d)对比。
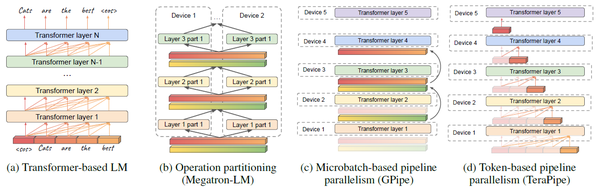
切分input sequence (token dimension)可以和其他模型并行方式组合使用,如pipeline并行和拆分算子并行。在给定input sequence [x1, x2, …, xL],如何找到合适切分点使得切分后[s1, s2, …, sM],其中si包含[xl,…, sr],使得端到端的训练效率最高。
解决方法:选择合适的切分点很重要。若切分后的sequence太小,会使得设备利用率低;若太大,会使得bubble变大。同时,input sequence不能均分,h\_t的计算依赖于之前的h1, …, h\_t,处于模型后端的layer的computation load更大。下图是使用input sequence均分和运行时间均分的对比图。
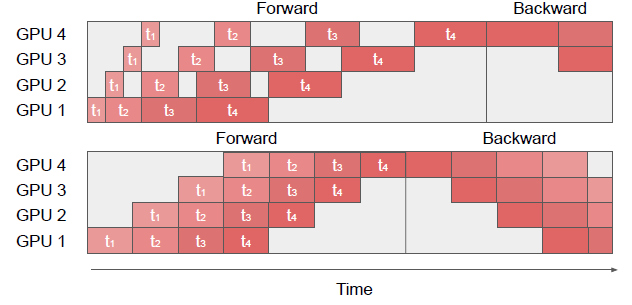
在给定pipeline切分stage数的前提下,文章提出了用动态规划的算法找到合适的input sequence切分点。该算法可扩展到同时切分batch维和input sequence。
效果:训练GPT-3 175B模型时,利用384 GPU环境,相比于不切分input sequence的Gpipe,此工作的切分input sequence的方法会有5-6倍的性能提升。
评论:论文中提到的这种逐字计算的方式,最初的驱动力是由于Gpipe这种方式内存开销大,不过,解决Gpipe并行方式内存开销大的问题,业界还有其他的方式,例如DeepSpeed、Dapple都有对Gpipe的改进方案,一样可以做到很高的并行并行加速比和低内存开销。笔者认为TeraPipe算是很好的一种技术路径探索,不过从训练的角度上看,实现上可能还是DeepSpeed、Dapple那种更加的高效。
谢谢晓达支持
推荐阅读
- Towards Open World Object Detection -CVPR2021 Oral
- 【从零开始学深度学习编译器】二,TVM中的scheduler
- 白给的性能不要?cvpr2021-Diverse branch block
更多嵌入式AI技术干货请关注嵌入式AI专栏。

