
转发自公众号“FPGA加速器”,欢迎关注。软件定义智能网卡FIA架构中可重构分组处理流水线RDP(Reconfigurable Datagram Pipeline)有多种实现方式,如通用网络分组处理流水线实现,以及基于RMT的可编程网络分组处理流水线实现。目前,已经基于RMT架构实现了可重构的可编程网络分组处理流水线,近期将会开源verilog代码。
RMT
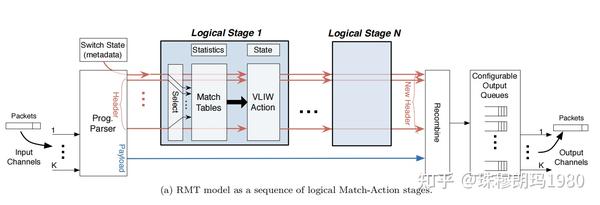
RMT(Reconfigurable Match Table )主要由一个解析器和任意数量的匹配阶段组成。
解析器允许修改或添加字段定义,这意味着是一个可重构的解析器。解析器输出是一个包头向量,它是一组头字段,如IP dest、Ethernet dest等。此外,包头向量包括“元数据”字段,如包到达的输入端口和其他路由器状态变量(例如,路由器队列的当前大小)。向量通过一系列逻辑匹配阶段,每个阶段抽象出包处理的逻辑单元(例如,以太网或IP处理)。
每个逻辑匹配阶段都允许配置匹配表大小,输入选择器选择要匹配的字段。
包的修改是使用宽指令(VLIW-very long指令字块)来完成的,该指令可以同时操作报头向量中的所有字段。
控制流是通过来自每个表匹配的附加输出下个表地址来实现的,该输出提供了要执行的下一个表的索引。
RMT允许通过修改解析器来添加新字段,通过修改匹配内存来匹配新字段,通过修改stage指令来匹配新操作,通过修改每个队列的队列规则来创建新队列。
可配置的解析器
解析器接收数据包数据,并生成4K位的数据包头向量作为其输出。解析流程是由用户提供的解析图指导的,它由离线算法转换为256个40b TCAM(三态内容寻址存储器)条目,匹配入包数据的32b和解析器状态的8b。这个解析器TCAM完全独立于每个阶段中使用的匹配TCAM。TCAM匹配的结果触发一个操作,该操作更新解析器状态,将输入数据移动指定数量的字节,并将一个或多个字段的输出从输入包中的位置指向包头向量中的固定位置。通过将关键的更新数据(如输入移位计数和下一个解析器状态)从RAM中提取到TCAM输出优先级逻辑,循环得到了优化。
可配置的匹配内存
每个匹配阶段包含两个640b宽的匹配单元,一个TCAM用于通配符匹配,SRAM用于基于哈希表的精确匹配。SRAM哈希单元的位宽由8个80b子单元聚合而成,而TCAM表则由16个40b TCAM子单元组成。这些子单元可以单独运行,也可以在更宽的范围内分组运行,或者在更深的表中分组运行。输入交叉开关向每个子单元提供匹配数据,子单元从4Kb数据包头向量中选择字段。相邻匹配阶段中的表可以组合成更大的表。基于限制,所有32个阶段都只可以创建一个表。每个匹配阶段有106个1K×112 b条目的RAM块。分配给匹配、动作和统计内存的RAM块的部分是可配置的。读取确定地在一个周期内执行,所有访问方式都并行进行。每个匹配阶段也有16个TCAM的2K条目×40b,可以组合成更宽或更深的表。
可配置的操作引擎
为每个报头字段提供了单独的处理单元,以便所有的都可以同时修改。小字段的单位可以组合起来执行一个大的字段指令,例如两个8b单位可以合并成一个单独的16b字段来操作数据。每个VLIW为每个字段字包含单独的指令字段。一个通用可选条件是destination valid。cond-move和cond-mux指令用于内部到外部和外部到内部字段的复制,其中内部字段和外部字段依赖于包。一个复杂的动作,比如PBB、GRE或VxLAN封装,可以被编译成一条VLIW指令,然后被组合成一个原语。灵活的数据平面处理允许以更高的成本和100Gb/s的速率执行需要网络处理器、FPGA或软件实现的操作。
小结
已经基于RMT架构实现了可重构的可编程网络分组处理流水线,近期将会开源模块verilog代码。
作者:珠穆朗玛2048
来源:https://zhuanlan.zhihu.com/p/362573389更多FPGA智能网卡相关技术干货请关注FPGA加速器技术专栏。

