
转载于:知乎
作者: 金雪峰本次小伙伴们分析了一篇关于分布式训练时,提升通信效率的论文,供大家参考。
背景
随着深度学习网络规模的增加,基于集群的分布式训练应用的也更加广泛。传统的分布式训练设计,在面对大模型时,受限于机器之间的带宽限制,线性比并不高,无法达到好的训练性能。论文则提出一种利用tok-k稀疏的通信算法,对各个gpu之间的梯度汇聚更新的通信负载进行压缩。
相关工作
现有的公有云系统,分布式的端到端的训练流程,大致可以分为以下几个部分:数据集加载、正反向传播、各gpu之间的梯度Allreduce、梯度更新。论文以16节点的gpu环境对稠密的SGD算法以及TopK-SGD算法进行了性能测试,按照上述几个部分划分,测试结果如下图:
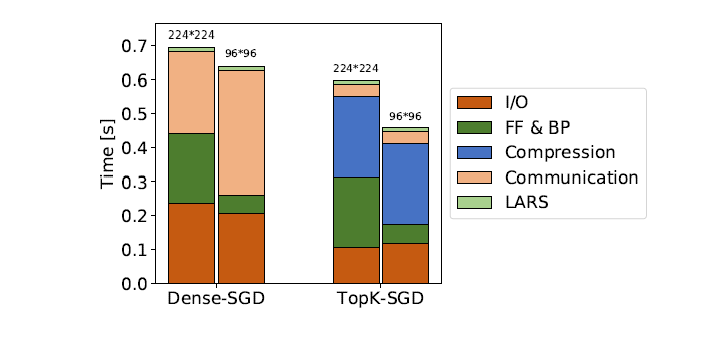
从测试结果来看,传统的稠密的SGD算法,I/O与通信时间占比非常大,相比较而言,TopK-SGD可以有效降低通信时间,但是其存在两个明显的问题:1)需要对每个GPU进行确切的topk排序算法,耗时很大。2)需要使用AllGather对稀疏表达的梯度-索引进行各卡间的收集。从图上也可以看到,TopK-SGD的compression时间消耗过大。为此,该论文提出了一个高效的近似TopK算法,以及TopK稀疏梯度的通信策略。
MSTopK算法
梯度的TopK的公式表达如下:
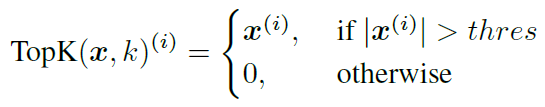
其中阈值_thres_为所有梯度_x_中,排在第k位的梯度的模,由于GPU内存的不规则排布,去实现一个高效的TopK算法较为困难,而论文则提出一种近似的TopK算法,称为MSTopK。整个算法的伪代码逻辑如下:

整个算法的核心逻辑在于二分查找,设置一个最大的查找步长N,设置两个初始阈值thres1、thres2以及对应的thres1,thres2在梯度排序中的索引位置k1、k2,不断调整thres1,thres2变量。每次判断的依据为:thres在梯度排序中的索引位置nnz是否比目标k大。经过固定的查找步长N后,最终找到的一个thres1和thres2范围后,真实的k对应的thres必然在这个范围内。最后,在
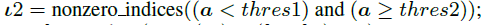
这个真实的梯度列表中随机找一个位置, 与
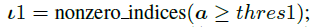
进行拼接,得到最终的近似TopK的梯度列表,既下面概率密度函数中红框框出的范围。
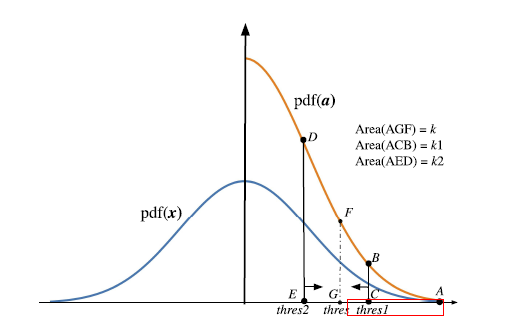
可以看到,这样做的好处是,不需要进行任何排序操作,均是向量化的操作,适合GPU进行运算。
层次化的TopK通信算法
在经过TopK运算后,每张卡得到稀疏表达的梯度2k个,并且稀疏表达的梯度在各卡上所对应的索引值是不一致的,无法通过单个AllReduce操作实现梯度的汇聚。现有的工作对于稀疏表达的梯度,是通过两次AllGather操作分别对梯度索引以及梯度值进行汇聚。但是,跨机器的通信效率远远低于单台机器内部的GPU之间的通信效率,在大规模集群下,直接做AllGather操作是不高效的,文章提出了一个多级的topk-communication算法,称作HiTopKComm,以解决这个问题。
整个算法的流程如下图所示,1)首先对稠密的原始梯度,在机器内部的GPU卡间做一次ReduceScatter。2)对各卡上1/n(n表示一台机器内的gpu数目)的梯度,执行MsTopK操作,得到稀疏的梯度。3)执行跨机器的AllGather操作。4)执行机器内的AllGather操作。
可以发现,这样做的好处有,1)降低了TopK算法的输入的大小,有效降低这一部分的时间。2)大大减小了机器间的通信的数据大小,提升整体的通信性能。

实验结果
论文针对提出的MsTopK算法,设计了多组实验,以验证其精度以及性能。选取的实验环境为:基于16台NVIDIA Tesla V100-32GB GPU机器,每台机器8张GPU卡,机器间带宽为25Gbps。选取了Transformer网络以及CNN网络作为实验对象。
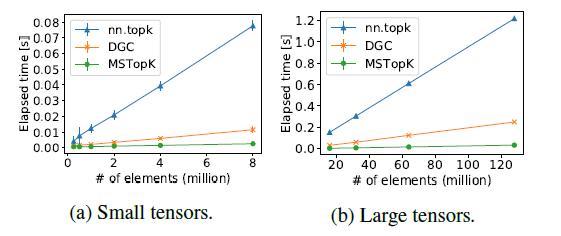
关于MsTopK这个算子的性能,实验结果如下图。实验的迭代时间为5个独立实验的平均值,MSTopK选择的固定步长为30。实验结果表明,MsTopK算子,其扩展性的表现明显优于原始的topk算子。
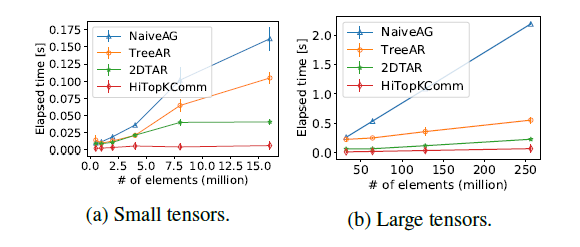
关于HiTopKComm通信算法,基于nccl库,与其他稀疏的通信算法进行比较,实验结果如下,同样可以发现,扩展性优于其它通信算法。
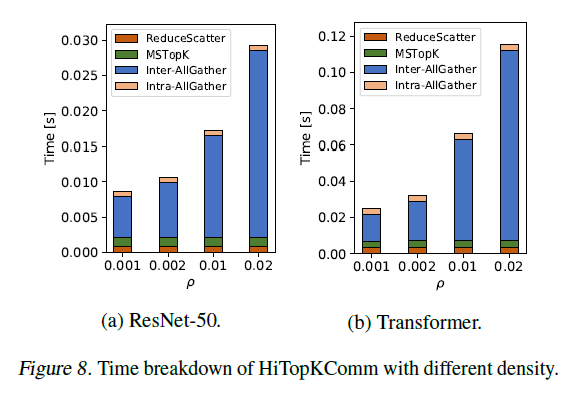
论文针对HiTopKComm的通信瓶颈进行了分析,结果如下,可以看到,瓶颈仍然在于跨机器的通信时间。
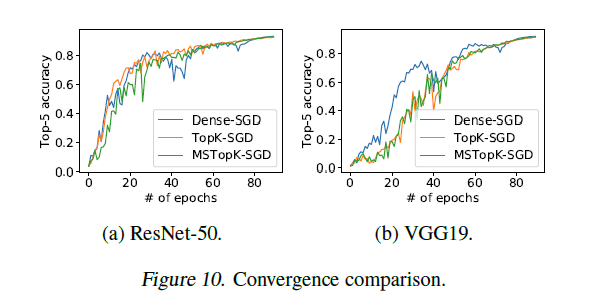
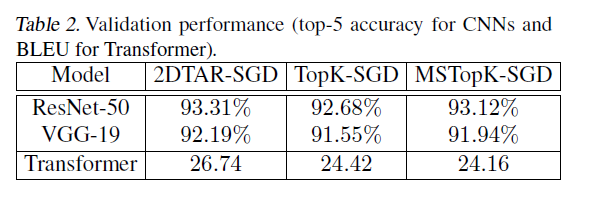
关于精度,实验结果如下图表,可以发现,相比于原始的TopK-SGD,精度没有任何下降。
总结
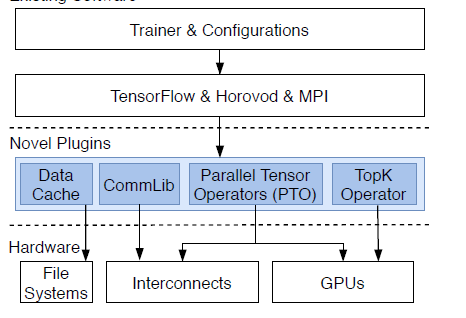
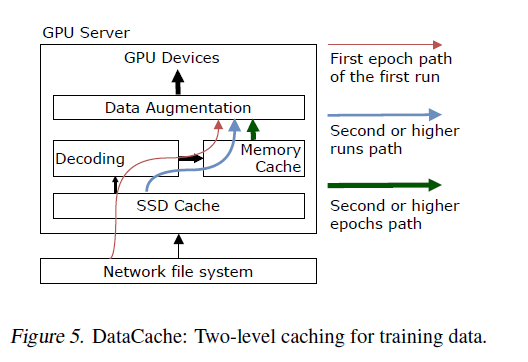
论文提出了一个针对分布式训练系统的GPU友好型的TopK-SGD算法,并且提出了一个层次化的通信策略。论文同时还设计了整个云上端到端系统的逻辑架构,其中对I/O部分也进行了优化,但是相比较而言,I/O部分没有显著的差异,使用了多级缓存数据加载的策略。论文针对提出的MsTopK算子以及HiTopKComm均进行了实验,其实验结果表明,可以在不失精度的前提下,有效提升分布式训练的扩展性。
参考
《Lin, Y., Han, S., Mao, H., Wang, Y., and Dally, B. Deep gradient compression: Reducing the communication bandwidth for distributed training. In International Conference on Learning Representations, 2018.》
《Shanbhag, A., Pirk, H., and Madden, S. Efficient top-k query processing on massively parallel hardware. In Proceedings of the 2018 International Conference on Management of Data, pp. 1557–1570, 2018.》
《Mikami, H., Suganuma, H., Tanaka, Y., Kageyama, Y., et al. Massively distributed SGD: ImageNet/ResNet-50 training in a flash. arXiv preprint arXiv:1811.05233, 2018.》
END
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

