
转载于:知乎
作者: 金雪峰

背景与动机
深度学习技术和深度学习编译技术目前一直是业界研究的热点,AI编译技术也可以从两个层次来看,偏前端的是基于图的编译器技术,偏后端的是基于张量的编译器技术。现有的张量编译器已经证明其在通用硬件上(CPU,GPU)部署深度神经网络的有效性,但部署在基于AI应用的NPU上,仍然具有非常大的挑战。
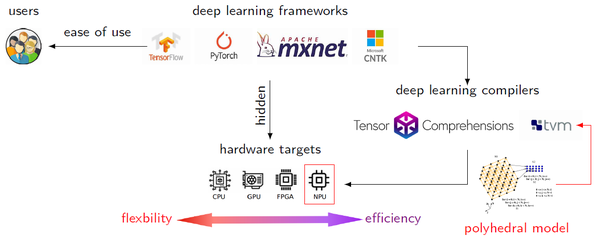
挑战
开发一个面向NPU架构的编译器仍然面临着诸多挑战,因为NPU上通常需要更复杂融合策略设计,以期充分利用NPU上的快速存储部件。编译器需要解决不同程序对并行性和局部性的需求不同的挑战,并找到最优的schedule结果。另一方面,领域特定芯片的内存层级都是多层次、多方向设计的,编译器需要解决如何在软件层面上实现自动内存管理的挑战。解决面向领域特定硬件,自动生成运算密集型算子的挑战,例如卷积,矩阵乘等。
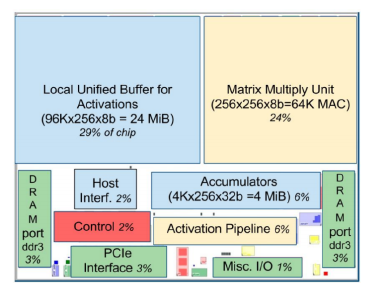
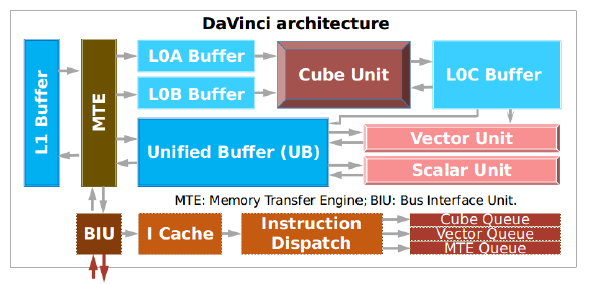
解决方案
为了更友好的和前端的图编译器配合,AKG支持Graph Kernel Fusion算子json和TVM的DSL作为输入,来表征张量计算。同时为了弥补当前解决方案,在面向NPU后端时,调度原语中对自动transformation和自动内存管理的表征不足,AKG引入一个PASS将HalideIR转换为Polyhedral IR,便于后续进行基于多面体的IR变换。将多面体模型和TVM相结合,不仅可以重用后者现有的一些功能(减少重复造轮子的工作),还可以平衡两者的不足。
AKG利用多面体模型的调度算法,更好的同时挖掘程序并行性和局部性。利用多面体模型,AKG对loop fusion和loop tiling进行了很好的建模,并很好地实现了数据排布和内存层级之间的解耦。同时AKG将外部调度树作为输入来实现img2col卷积的转换。AKG还实现了基于NPU指令集的完备向量化方案,多级流水线的自动同步插入,以及auto-tuning来优化生成代码的性能。
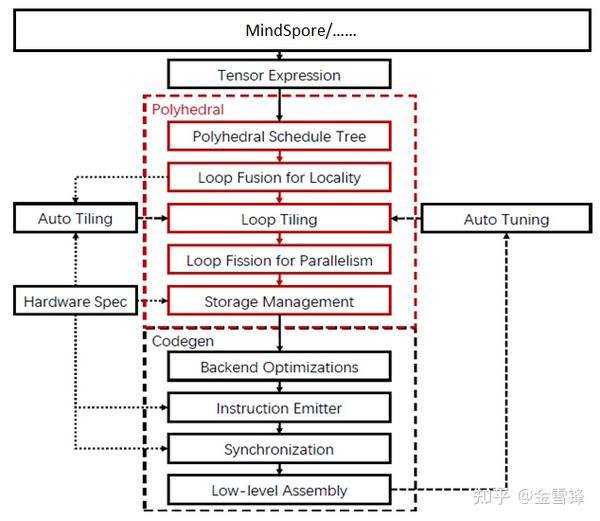
多面体变换
多面体模型是对程序的一个数学抽象,在该抽象上更准确的进行程序分析和编译优化。
Abstraction Lowering
AKG可以将用TVM的DSL编写的张量程序lowering到多面体模型表征的中间表达,调度树上。调度树的表达非常丰富,包括了各种不同类型的节点,其可以根据程序需要来表示程序中不同类型的信息:
- Domain节点,filter节点
- Band节点,sequence节点和set节点
- Extension节点
- Mark节点,等

多面体调度
AKG利用基于整数线性规划的ISL调度器来对输入程序进行新的调度变换。ISL调度器以Pluto算法为主,并辅以Feautrier算法,在程序的并行性和局部性之间寻求最优。下图是一个循环融合的示例,该示例是一个2D卷积算子,后跟了两个abs和Relu的张量计算。在经过融合后,可以看到语句1,语句2,语句3合并到同一个Band节点之下。

Loop Tiling
Loop tiling在多面体的循环变换中是非常重要的一个环节。其对于程序的局部性和并行性,以及内存层级管理都非常重要。Loop tiling的实现可以归结为两个基本问题:一个是tile shape的构建,另一个是tile size的选择。
Tile shape的构建方法非常灵活,可以基于正向的策略,也可以基于反向的策略(更多内容可以参考MICRO/ Optimizing the memory hierarchy by compositing automatic transformations on computations and data),开发者还可以根据自己的需求进一步的丰富构建策略。但基本上在Loop Fusion之后,就可以实施了。
Tile size的选择也是一个非常有意思的topic,目前的compiler有几种常用的方法:基于类型使用程序默认的tile size;或者将这一个过程委托给用户,让用户在开发算子schedule模板时来设置tile size的大小。为了更好的适配多面体模型,AKG为tile size专门提出了一个specification language。

Tile size的spec由下述描述组成:语句id,每个循环维度的tile size大小,指示字符串,表示该语句应该放置的位置。该spec可以简化AKG对于tile size的自动设置,便于AKG实现Tiling的自动化。
Loop Fusion
Loop fusion是一种最小化生产者消费者距离的循环变换,便于优化程序的局部性。Loop fusion已经集成到多面体编译中,以便于挖掘与其他循环变换的组合。现有的启发式融合算法,并没有考虑面向NPU的多向的内存层级结构。AKG完善了面向NPU多内存层级的融合策略。
AKG中实现了多种融合策略,包括:offloading数据融合, forking数据融合,以及intra-tiling的rescheduling。Rescheduling的过程中,对于适用于Vector Unit进行向量化加速的计算进行loop distribution,对于适用于Cube Unit的计算进行更aggressive的融合策略。
Convolution优化
由于卷积运算是CV类网络中计算量占比最高的算子,高效的卷积实现更有助于DL模型运行加速。我们实现了基于多面体的img2col转换,并将卷积转换为矩阵乘操作,以加速卷积算子。
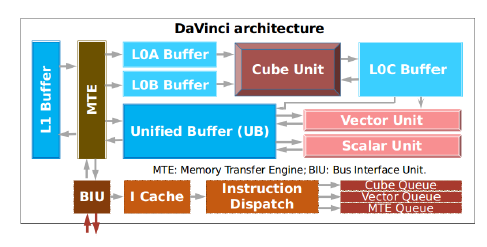
矩阵乘法可以充分挖掘NPU芯片中Cube计算单元的算力。AKG构建了基于外部多面体IR的分型结构的矩阵乘法,在实现方案中同时考虑了band node的切分,以及内层维度的分型对齐,如下图所示。
Other Optimizations in AKG
AKG的目标程序语言是类C风格的CCE代码,其充分考虑了昇腾910架构以及Cube算力,SIMD的向量化等。多面体优化是AKG关于自动调度非常重要的一个环节,但是并不是整个AKG的优化flow。在多面体编译优化之外,还有基于HalideIR的优化pass来自动生成高效的CCE代码,主要包括程序规范化相关的优化,以及硬件相关优化等。
程序规范化优化,包括运算符inline、公共子表达式删除、程序三地址化等。
由于在DL网络中还有除去计算密集的卷积运算之外的其他计算,所以有效的利用SIMD对于NPU的高效使能也至关重要。向量化pass会将多面体技术优化后的Halide IR作为输入,并从中分析中有效的信息,包括alignment, strides, source和destination等,可以自动生成高效的SIMD代码,并具有自动考虑代码中未对齐场景,进行自动对齐。
另外,现代NPU架构都会考虑decoupled access-execute (DAE)的架构,其中每个计算单元和数据搬移单元都有一个独立的指令pipeline,这些pipeline之间是相互独立的,可以同步执行。这一相关优化,也超出了多面体的编译优化,AKG采用DP的方法,实现了面向NPU的优化pass来实现同步优化。
最后,多面体变换通过对硬件架构抽象来优化程序调度,得到的程序性能并非实际中的最佳。AKG基于auto-tuner工具来解决这个问题,通过统计不同tiling策略下算子的性能。通常张量计算的tuning space是非常巨大的,因此我们使用一种基于机器学习的样本抽样方法,对tuning space进行裁剪,在较短的时间内,获取最优性能。
实验
AKG是全栈全场景AI计算框架MindSpore的算子自动生成工具,可以自动生成华为昇腾910芯片上的执行代码,用于深度神经网络训练和推理任务。更多的算法实现可以参考

实验从单算子、子图以及整网的角度来对比不同工具与AKG的性能 。
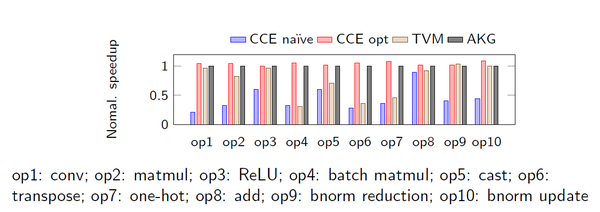
在单算子的对比实验中,我们可以看到手工优化后的CCE代码比优化前能提升2.8倍。AKG自动生成的代码性能,能够和优化后的CCE代码持平;并且平均超越TVM有1.6倍。
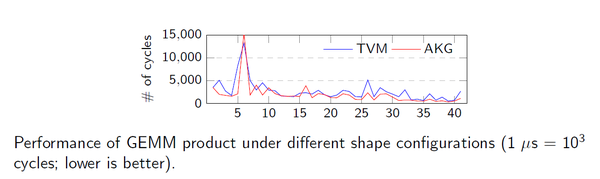
本实验,选取了41个shape大小从(64,64)到(4608,4608)不同大小的矩阵乘法来评估性能的稳定性。在41个不同的case中,AKG有29个case的性能优于TVM的结果。
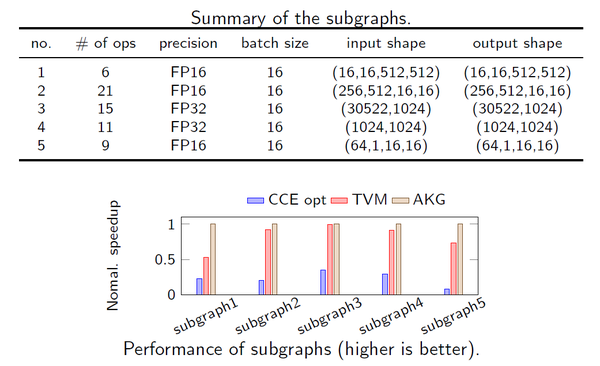
在子图融合的对比实验中,AKG平均超越adapted TVM1.3倍,平均超越CCE opt有5.6倍。
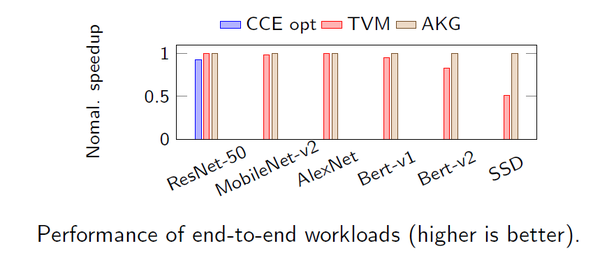
在整网的对比实验中,AKG在ResNet-50, MobileNet,AlexNet和TVM基本持平。但是在Bert和SSD上,超出TVM平均20.2%。此外,虽然在ResNet-50上CCE opt的整网性能最佳,但是手动优化需要大量的人力,而采用自动化工具,可以大大节省人力成本。
总结
首先,AKG采用反向融合策略合理的平衡了tiling和fusion的相互影响,并且实现了平台中立的变换实现。此外,AKG采用hierarchical fusion的方式,可以很好的应用在多内存层级的NPU架构上。还有就是AKG中自动执行卷积算子的领域特定的transformation以及fractal tiling都是较为通用的实现方案。最后,AKG扩展了schedule tree的表达,这一做法其实和MLIR有着异曲同工的效果,都希望在多面体表征上加入领域特定的知识信息。
扩展工作
目前,AKG还增强了面向GPU硬件的自动生成高性能的cuda算子的能力。与的图算融合技术相结合,在MindSpore全场景AI框架上,对于许多业界benchmark网络,性能已经超越了主流AI框架(TensorFlow/MXNet等),取得了非常不错的成绩。更多关于实验的评测报告,大家可以在下述链接中翻阅:
[Orange Lee:国产深度学习框架MindSpore训练性能评测 —— by 中科大ADSL实验室zhuanlan.zhihu.com
(https://zhstatic.zhihu.com/as...
基于AKG算子自动生成技术和图算融合技术,目前还在紧锣密鼓地进行更多NN网络的泛化验证工作,大家很快也可看到详细的工作进展。
展望
在面向NPU后端,引入多面体模型,实现调度自动化,AKG工具做了非常多新颖并且有意思的工作。虽然AKG的论文解读到此就结束了,但是多样化算力异构计算的挑战和软件2.0下AI应用的浪潮远未结束。相信在不久的将来,随着DSA硬件架构的不断迭代,以及AI编译技术的持续创新,终究会迎来软硬紧密协同的黄金年代。
END
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

