
前言
ISSCC全称为IEEE International Solid-State Circuits Conference(国际固态电路会议),被誉为集成电路领域的"奥林匹克"。会上开放大量的很有价值的、经过实测的设计,供工业界和学术界参考使用。而工业界的踊跃参会更使得会议能够建立起工程研发和学术研究的桥梁。
本文主要汇总了ISSCC中关于处理器和SoC的论文,重点是通用处理器和处理器核设计,还会简单介绍一些SoC处理器的设计。本文不涉及GPU、神经网络处理器和非常专用的领域SoC。在ISSCC会议议程中,与处理器和SoC相关的Session有Session 2:Processors和Session 8:Highlighted Chip Releases。
Session 2的标题就是“处理器”,重要介绍的就是通用处理器和SoC处理器的设计。一般来说,这个Session入选的论文都来自于业界有影响力的企业,发布的设计也都是各家公司当下的旗舰产品。2020年的Session 2一共有7篇文章,分别介绍了AMD公司的Zen 2架构(2.1和2.2)、IBM的Z15架构(2.7)、MediaTek联发科的Dimensity(天玑)1000(2.5)和TI德州仪器的Jacinto 7(2.6)。除了这四款产品级芯片之外,三星电子发布了一款原型芯片(2.4)、法国CEA研究院(2.3,校企联合意法半导体和Mentor)发布了一款Chiplet芯片原型。
Session 8发布了4款芯片,分别是Intel的Lakefield架构(8.1)、Xilinx的Versatile加速器(8.2)、ARM的Neoverse N1处理器(8.3)以及AMD的Radeon RX5700显卡(8.4)。其中8.1和8.3会在本文有所涉及。
从CPU核的角度,本届ISSCC出现的处理器核心很多,尤其是各种配置的ARM核心,占据了“半壁江山”。三星、联发科和TI发布的都是面向不同应用场景的SoC芯片,采用ARM的CPU核IP。三星公司还介绍了他们自研的ARM指令集核心M4。算下来,9片文章中出现的处理器核心包括:
- AMD Zen 2 (2.1)
- IBM Z15 (2.7)
- Intel Sunny Cove(8.1)
- Intel Tremont(8.1)
- 三星M4(2.4)
- ARM Neoverse N1(8.3)
- ARM Cortex A75(2.4)
- ARM Cortex A77(2.5)
- ARM Cortex A55(2.4和2.5)
此外,TI使用的三款ARM处理器IP分别属于Cortex-M和Cortex-A系列,具体型号未知。Intel Lakefield中使用了两款处理器核(Sunny cove和Tremont),不过论文8.1的重点完全不在这方面。
本届ISSCC在封装工艺方面介绍了很多成果。Session2中有两篇文章(2.2和2.3)都是介绍Chiplet封装和互联结构设计的,使得Chiplet妥妥的占据了C位。很多人将此解读为Chiplet时代到来。但是在Session8中,Intel介绍了基于Foveros 3D封装工艺制造的Lakefield芯片,这也是非常有开创性的成果。
接下来,本文分三个方向介绍各篇文章,分别是高性能处理器(2.1、2.7和8.3)、Chiplet/3D封装(2.2、2.3和8.1)和SoC处理器(2.4、2.5和2.6)。重点是从论文和幻灯片中截取的架构设计和参数。
高性能处理器
这部分会介绍AMD的Zen2处理器(2.1)、IBM的z15系统(2.7)以及ARM的Neoverse N1处理器(8.3)。这三篇文章都将论文重点放在了处理器架构设计以及与处理器相关的物理实现上。Zen2处理器是AMD下一代处理器架构,覆盖了从移动端、桌面端、工作站和服务器的广阔市场。z15架构用在IBM生产的机器中,也面向高性能计算场合的。Neoverse N1则是ARM专门针对服务器市场开发的第一款IP。这些处理器的设计需要在性能和功耗之间进行平衡。
AMD Zen2 (2.1)
Zen2是AMD下一代x86-64处理器架构,使用TSMC 7nm工艺制造。时钟频率4.7GHz。Zen2覆盖了从移动端、桌面级到工作站和服务器的广阔市场。相对于Zen,Zen2取得了15%的单线程性能提升。同时降低9%的开关电容,可以减少50%的功耗。
Zen2采用了chiplet封装技术,一个封装有一颗互联Die和多颗处理器Die组成(如图8所示)。AMD通过这种方式,可以针对不同的市场进行产品配置。处理器Die的基本单元是被称为Core Complex Unit,简称CCX(图1所示)。一块处理器Die包含2个CCX。在AMD的设计中,一个CCX包含4个处理器核,和16MB共享L3。L3分片布置。CCX可以进行不同的配置。对于工作站和服务器,可以配置为4 core和16MB L3;对于桌面机,可以配置为4 core和4MB L3,而对于移动端,则可以配置为2 core,4MB L3。

图1. Zen2的CCX版图
Zen2架构
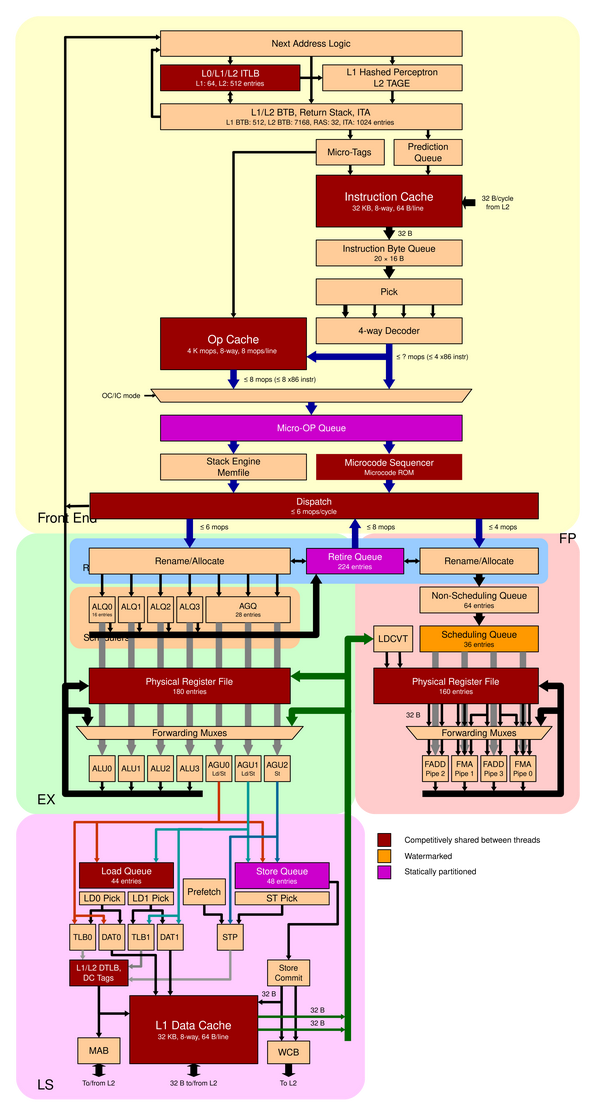
图2. Zen2架构图(来源wikichip)
图2展示的是Zen2的结构图。从图2和论文中可以得出,AMD对Zen2的架构进行了如下的改进。
- 前端架构
- 新的TAGE分支预测器。
- L0 BTB 16单元,L1 BTB 512单元,L2 BTB 7K单元。
- uop cache翻倍,由2K到4K。
- Cache容量扩大
- L1指令cache,由64K/4路变为32K/8路。
- L1数据缓存读写带宽翻倍。DTLB从1.5K到2K。
- L3缓存翻倍,从pre die 8MB到pre die 16MB。
- 乱序执行能力提升
- 物理整形寄存器(用于重命名)从160提高到180。
- 整数调度单元从84增加到92个单元。
- ROB从192增加到224个单元。
- 执行单元
- 浮点计算宽度翻倍,由128b到256b。
- 第三个地址产生单元。地址产生器可以发射3个store地址。
分析
相对于Zen和Zen+,Zen2可以说是全面升级。首先,扩大uop cache容量以提升前端输出指令的吞吐率。将原有的感知分支预测器替换为TAGE预测器,是为了提升分支预测正确率,减少由于流水线刷新导致前端出现气泡。TAGE预测器也是目前业界较为公认的高性能分支预测器。
同时,将浮点计算宽度从128比特提高到256比特,可以缩短SIMD执行的延迟。256比特宽度的指令可以一次做完,而不需要拆成两次128比特操作。
为了发挥出宽发射和后端划分整形和浮点簇的效果,AMD将ROB提高到224个单元,而且专门提高了整数运算簇的调度器单元和整形寄存器。ROB扩容提高了乱序窗口大小,可以实现更大范围的指令的乱序。提高整数运算簇的调度器单元和整形寄存器则可以与4个整数整形单元和3个地址产生单元相适用。
访存的优化一直是CPU优化的重点。Zen2增加了一个指令计算单元,使得一个周期可以下发最多3条store指令或者2条load指令。同时,L1 cache路数翻倍,DTLB扩容,L3扩容,都是为了减少访存延迟。不过相对于Zen,Zen2最大的变化出现在Die间互联结构。这部分在本文的AMD Chiplet部分中进行了介绍。
当然,这种升级的代价就是迅速增加的资源。上一节中每一条改进的背后,都是内存和逻辑资源的迅速增加。这些资源通过采用7nm制造工艺和优化的物理设计得到了吸收,才得到了Zen2的功耗比Zen低的成绩。
IBM z15 (2.7)
IBM z15是IBM Z系列大型机的最新成员,用于数据中心、云计算等场合。IBM z15的处理器采用GlobalFondires的14纳米工艺制造。
z15架构
整个系统由多个Drawer组成,每个Drawer包含另个CP(Central Processor)簇和一个SC(System Controller)。每个CP簇包含两个CP,每个CP连接Memory以及3 lane PCIe。如图3所示,整个系统最多包含5个Drawer,20个CP和5个SC。由于每一个CP共计12个core,所以整系统最多有240个core,而设用户可以使用190个core。其余60个核用于系统管理、功耗和良率备份。
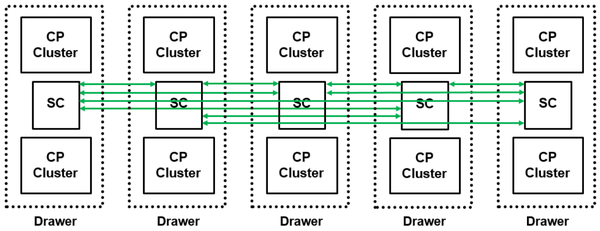
图3. IBM Z15系统图
图3中的绿线展示了Drawer之间的互联拓扑结构,每一个SC都与其他4个SC形成直连;图4展示了一个Drawer内部的互联拓扑,每个CP都与SC直连,每个CP簇中的两个CP可以直连。在IBM的设计中,一个Drawer占用一块基板。
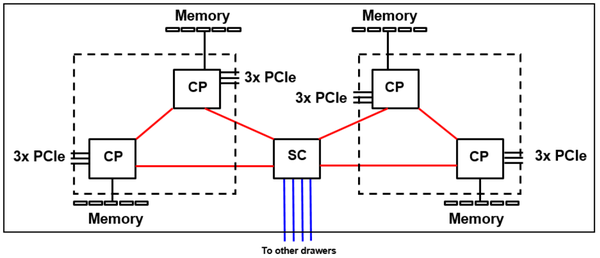
图4. Z15的Drawe拓扑图
SC架构
SC用来提供Drawer之间的互联以及Drawer与CP之间的互联。SC工作在2.6GHz。SC提供缓存和两种通信总线:A-Bus和X-Bus。
- A-Bus用于Drawer-to-Drawer互联,差分链路。SC提供4条A-bus链路。每条lane提供10.4Gb/s(提高33%),每条链路提供0.9Tb/s,SC共计3.6Tb/s。
- X-Bus用于SC和CP互联,单端链路。SC提供4条X-Bus连接,每条lane提供5.2Gb/s,每条总线提供0.8Tb/s,SC共3.2Tb/s。
- SC提供了L4缓存。一块SC可以提供960MB的L4缓存(增加43%)。
CP架构
CP是一块比较传统的高性能多核处理器芯片,如图5所示。CP集成了Cores,L1/L2/L3 Cache,内存接口,IO以及CP和SC接口。CP工作在5.2GHz。
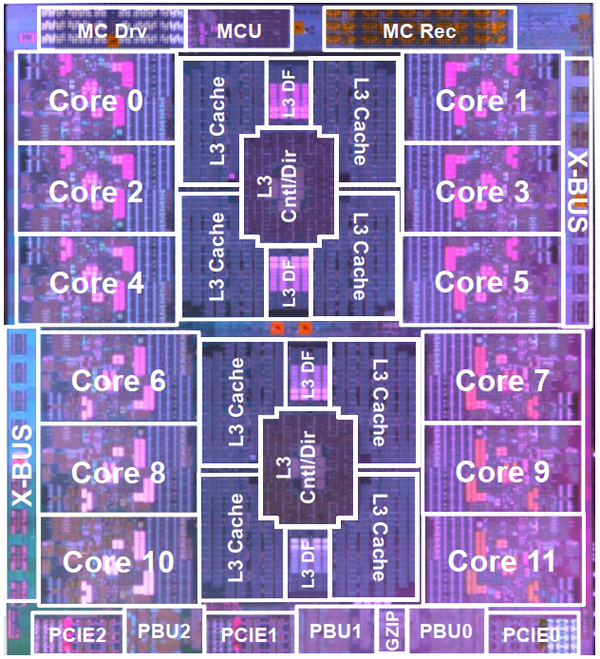
图5. Z15的CP架构
CP的主要参数有:
- CP集成了12个核(20%增加)。
- 核独享的L1I和L1D缓存都是128KB,L2I和L2D缓存都是4MB(增加33%)。
- CP提供256MB共享L3缓存(翻倍)。
- CP提供GZIP加速器。
- CP提供两条X-Bus连接,每条lane提供5.2Gb/s,每条总线提供0.8Tb/s(共1.6Tb/s)。
- 内存接口,每lane提供9.6Gb/s,总共1.6Tb/s。
- 3条 x16 Gen4 PCIe,总共0.8Tb/s。
从图5还可以发现,12个核实际上又分为两个簇,L3也对应分为两部分。两部分之间应该还有互联结构。
处理器核架构
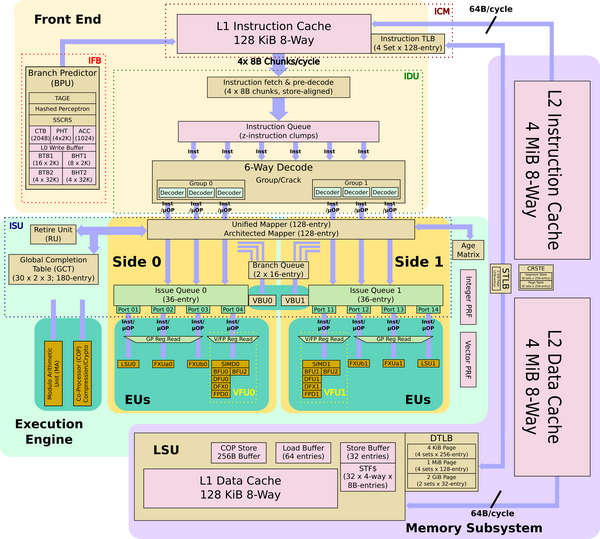
图6. Z15单核架构图(来自wikichip)
图6是Z15处理器的架构图,显著标注的技术参数有:
- 增强的激进分支预测器。L1 BTB和BHT翻倍,并且集成新的TAGE预测器。
- 2路SMT。
- 乱序流水线
- decode和dispatch宽度达到6条指令,发射带宽达到10条指令。
- 全局完成表增加25%
- 发射队列增加20%
- 寄存器映射表翻倍。
- Cache
- TLB翻到了4倍,覆盖512页。
- 新增加速器:ECC加速器、排序/合并加速器。
- 性能bug改进
- 改进operand-store-compare(OSC)冒险。
- 改进十进制操作和十进制到二进制转换。
- 改进store forwarding。
- Core面积减少10%,从28mm2到25mm2。指令序列器面积减少35%。
分析
Z15对于处理器架构IBM进行了一次较大的改动,将前端带宽提到到了6条指令,发射带宽提高到10条指令。不过,IBM的核中包含两套完全一样的执行单元,所以每个后端簇的应该可以分配到5条指令。为了应对指令带宽的增加,全局完成表、发射队列和寄存器映射表都进行了较大的扩容。
同时,顺应潮流,IBM也在处理器中使用了TAGE预测器。这样算下来,在高性能预测器领域有深入耕耘的Intel、AMD和IBM三家都已经认可了TAGE预测器的能力。
IBM自研的处理器核一般都是用在其大型机当中,所以处理器核可以针对大型机的应用场景进行专用的优化。从参数来说,主要体现在CP和处理器核中集成的各种加速器,比如GZIP加速器、ECC校验加速器、排序/合并加速器等。这些加速器使得处理器在执行这些常用操作时,获得明显优于软件的效果。
在未来的一段时间,异构集成将会是架构发展的主流。在SoC层面,通过集成大小核、GPU、NPU等不同的处理单元,可以扩展芯片的功能。在处理器核层面,则是在芯片中集成各种专用的加速器,加强特定指令的执行能力。处理器调用这些加速器,不需要经过总线,而是在CPU的后端就可以使用。
Arm Neoverse N1 (8.3)
Neoverse N1是ARM的第一代处理器专用CPU。其Spec跑分比Cortex-A72提高60%以上,甚至翻倍。不久前,Amper公司发布了业界第一个面向服务器的80核ARM处理器,其使用的处理器核就是这款IP。
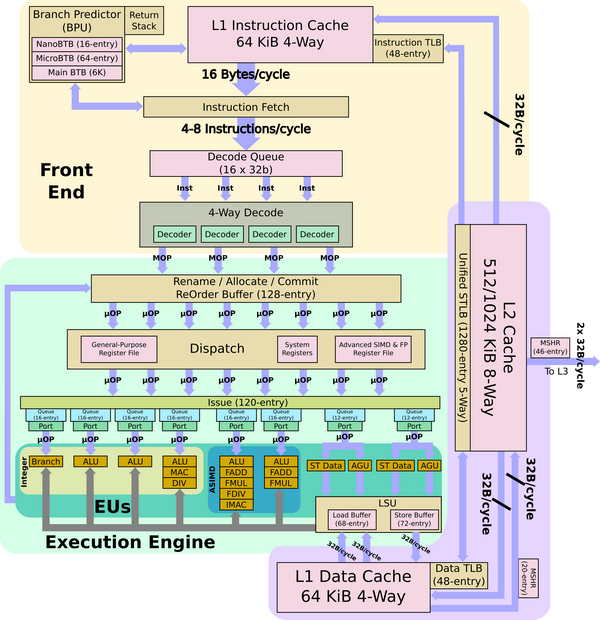
图7. Neroverse N1架构图(来自wikichip)
Neoverse N1可以使用16nm和7nm工艺,速度为2.5GHz到3.1GHz。论文中重点标注的特性包括:
- 支持I-cache一致性。I-Cache大小为64KB,4路;D-Cache大小为64KB,4路。
- 增加1MB私有L2缓存,8路结构。11周期load操作。
- 减少load-to-use DRAM延迟(3.5ns@2GHz GMN-600)。
- 消除共享L3缓存。
- 直接与ARM的Mesh互联IP(CMN-600)互联,支持CHI.C协议。
- 完整的ArmV8.2架构,支持静态分析扩展指令和48比特物理地址。
- 最高功率缓解技术可以降低芯片设计需要容忍的最糟糕情况。
互联和内存系统
图7是Neoverse N1的存储结构框图。从框图可以解释消除共享L3缓存的含义。在之前的设计中,共享L3是被分散到Cluster中的。每一个Cluseter中包含一个或者多个CPU。由共享L3连接互联网络。在NN1中,处理器通过CMN的CAL层直接连接CMN。而共享L3则被分割为多个切片,也被连接到CMN中。在CMN看来,处理器和L3都是一个节点。
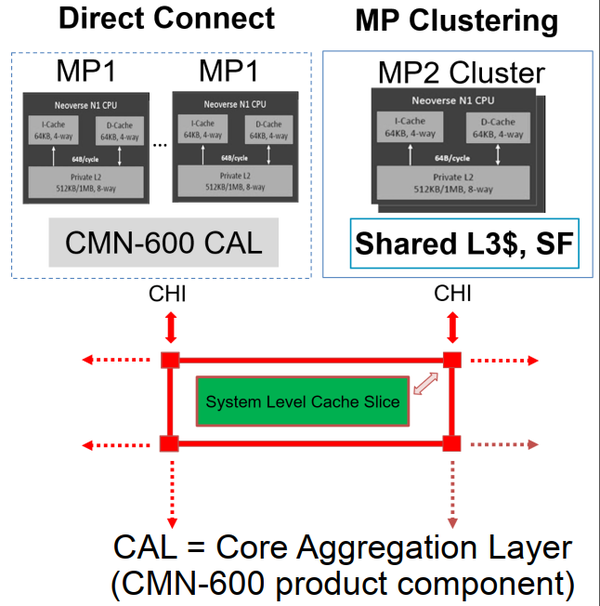
图7. Neoverse N1的存储结构框图
分析
从架构图上可以看出,ARM核的复杂度要比AMD和IBM的处理器架构简单不少,而且规模要小很多。虽然架构图上显示的是8发射。但是ARM核采用的是分布式的RS,也就是每一个执行单元有自己独立的保留站队列。所以,8发射其实是对应于8个执行单元。
论文和幻灯片上,ARM重点介绍的还是其在处理器核和Mesh互联网络(CMN)互联上所做的改进。CMN-600是ARM的第一款Mesh互联网网络IP,与Intel类似。AMD也在向Mesh过渡。服务器中使用Mesh互联网络已经成为各家的共识。
“消除共享L3缓存”这一句有些令人费解。其实,这是相对于ARM之前的SoC处理器核而言的。之前的处理器核不使用Mesh互联网络,L3直接被多个处理器核共有(可以参考下面SoC的框图)。对于服务器和Mesh互联网络,L3分片是必然的选择。如果访存发生L2缺失,会直接发起通信,寻找对应的L3分片。
Chiplet和3D
Chiplet是一种封装技术。相对于单片芯片,Chiplet可以解决不同工艺芯片集成的问题。相对于多片芯片,Chiplet又能提高芯片集成度,缩短互联延迟。真正让Chiplet火起来的原因是,大家普遍认为Chiplet会成为以IP为中心后的新一代的芯片设计商业模式。Chiplet也是DARPA电子复兴计划(ERI)中的3DSoc、POSH等的重要载体。Chiplet偏重于一种互联方案,所以AMD和CEA的文章也都侧重于互联技术。
在8.1中,Intel以其Lakefield架构为载体,介绍了其3D封装技术,不仅实现了不同工艺芯片的堆叠,还首次实现了逻辑芯片的堆叠。虽然逻辑芯片堆叠是很早就有的设想,但是由于散热和良率的约束,一直没有商用。可见,Intel应该是解决了这方面的问题。相对于Chiplet,3D堆叠对于架构和性能的改变要大一些。
AMD Chiplet (2.2)
AMD的多Die互联技术经过了两代发展,如图8。第一代是将一整块芯片切分了多个小芯片,每一块芯片都有自己的I/O和DDR接口以及die间接口,称为第一代EPYC,也程Infinity Fabric Connected。Zen采用的就是第一代的互联技术。第二代则是将所有的die间互联以及DDR、I/O接口都集中到中心的I/O Die上,如图8右侧所示。
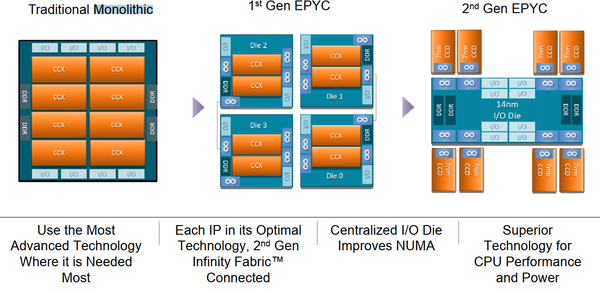
图8. AMD EPYC
图8右侧的图反映的就是Zen2的Chiplet结构。中间的互联芯片称为IOD,四周的处理器芯片称为CCD。CCD只能与IOD互联,而不与其他CCD或芯片外部直接互联。对应于第二代EPYC,AMD有两个代号,分别是“Roma”和“Matisse“。图7中展示的是“Roma”。
IOD可以采用较低的工艺,这是因为模拟或者数模混合电路不如纯数字逻辑对工艺进步十分敏感,模拟电路从工艺发展中获得的收益不大。同时,IOD和CCD之间需要大量的互联线,因此使用了串行的高速serdes(IFOP)作为物理层。Zen2中,IO Die采用TSMC的7nm工艺,处理器Die采用GlobalFoundary的14nm工艺。
CCD结构
CCD结构参数如下:
- 一个CCD包含两个CCX结构(如图2所示),所以一个CCD可以提供8个core和32MB的L3。
- 提供系统控制单元(SMU),用于时钟、复位、电源管理、温度管理。
- Die间连线,速度14.6GT/s。接收通路包括39条接收lane、2条时钟、1个时钟门控;发送通道包括31条发送lane、1条时钟门控。此外,还有4条流控信号和2个时钟信号。
- 提供DFT和调试接口。
- 提供Wafer测试接口。
DIe间互联拓扑
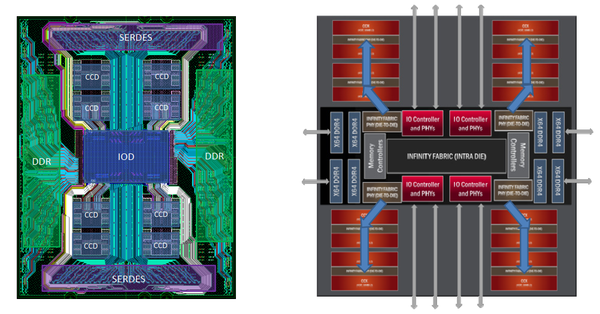
图9. IOD的布线
图9展示IOD的走线。左边是物理布线图,右边是逻辑框图。所有的Die间互联都需要通过IOD,所以即便采用了高速Serdes,布线资源还是不够。因此,两个相邻的CCD会公用一条链路。如图9左边,8片CCD被分成了四个象限(左上、左下、右上、右下)。每一个象限有2个CCD,这两个CCD复用同一条链路。要想到达最左上象限的CCD,那么一定会经过其下方紧挨着的CCD。
IOD提供了如下单元:
- 8组x64 DDR4接口,做IOD左右两侧分别引入。
- 4组IO控制器,一共提供128组x16 serdes,从IOD上下分别引入。
- 4组Die间互联,每一组包含72条数据线和8条时钟/控制线。
IOD内部互联
AMD强调,IOD将这个socket组成一个NUMA域,可以将平均内存访问延迟降低24ns,同时最小延迟提高4ns。图10展示IOD内部的互联网络,可以发现,内部组成了一个较为简单,但是异构的MESH网络。每个节点连接的单元类型和数量不同,而且网络也不是完整的Mesh网络。四个角的节点,分别连接CCD,内部有4个节点连接PCIe。
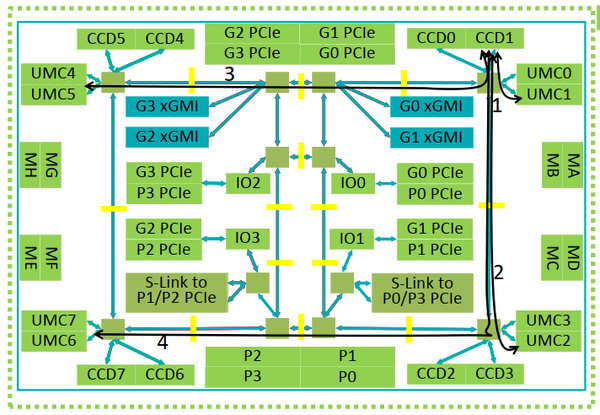
图10. IOD内部的互联
数据通过路由器(绿色方块)需要2个周期;通过缓冲器(黄色小矩形)只需要1个周期。最远端(路径4)比本地(路径3)需要多20ns的传输延迟。
所以说,从Chiplet的角度看,互联拓扑类似于星形拓扑;但是如果把IOD打开来看,网络拓扑的骨架其实是Mesh拓扑。
利用Chiplet组织生产
在幻灯片中,AMD展示了如何利用chiplet的组合。满足不同的市场。一个封装后的Socket中,一定有一颗IOD。这颗IOD是整个封装的中心。CCD则是组合的最小单位。前面说过,一个CCD包含8个core。
- 16核版本配置2颗CCD,左上、右下象限有一个CCD,右上和左下象限空白。
- 32核版本配置4颗CCD,四个象限各有一个CCD。
- 48核版本配置6颗CCD,左上、右上象限有一个CCD,右上和左下象限有两个CCD。
- 64核版本配置8颗CCD,四个象限各有两个CCD。这个单个Socket中处理器最多的情况。
对于需求核心更少的情况,AMD会采用代号为“Matisse”的IOD。之前介绍的都是“Roma”。“Matisse”是“Roma”的缩小版,相当于“Roma”的四分之一,包含2组DDR接口、1组I/O接口、1组Die间互联。使用Matisse IOD的封装Socket,可以连接两颗CCD。如果只连接1颗CCD,那么Socket只提供8个核。如果再进一步关闭CCD中的一个CCX,则可以得到4核版本。
任务调度
AMD一直在层次化的互联结构上向前演进。chipset依然没有改变层次化的结构。4个处理器核形成CCX;2个CCX形成CCD;多个CCD形成Socket;Socket还可以扩展。所以,其任务调度也一定要考虑到这种层次化结构。在幻灯片中,AMD提到了操作系统调度器的优化。AMD建议:
- 在启动时,根据各个处理器核的频率偏差,建立一个处理器核的频率列表。
- 单线程程序调度到频率最高的处理器核,多线程程序调度到频率最高的CCX。
分析
AMD在Zen2对其互联结构进行了较大程度的改变。第二代EPYC使用的网络拓扑和第一代EPYC完全不同。从Die的层面,第一代EPYC是直连拓扑,而第二代EPYC则是星形拓扑。如果进一步打开第二代EPYC的IOD,则会发现网络拓扑是Mesh形状。不过这个Mesh的规模远小于Intel的Mesh互联网络。远端和本地节点之间有20ns左右的传输时间差。因此,AMD似乎没有进行特定的网络负载均衡策略,只是建议通过任务调度避免出现距离最远的数据访问。
AMD的Chiplet工艺并不算很新,可以认为是将一小块PCB封装到了芯片中。所有的电路都Cchiplet上,而基板上只有互联线。
CEA Chiplet (2.3)
CEA研究院的文章介绍一款demo芯片,这款芯片的亮点是一种Chiplet的互联架构,称为Active Interposer。也有人对这篇文章的解读是:基于Chiplet的SoC设计将以互联为中心。
Active Interposer
图11是互联架构的框图。芯片分为基板和chiplet两层。chiplet实现了功能单元。图11中显示的是同构的chiplet,实际上应该可以是异构的。Chiplet中的互联采用2D Mesh NoC。基板上提供了功耗管理单元、模拟外设、I/O、PHY、DFT等。基板上布置了一个2D Mesh NoC,用来进行die间通信。每个chiplet都作为基板上NoC的一个结点。chiplet附近是与这个chiplet紧密相连的功耗管理模块。
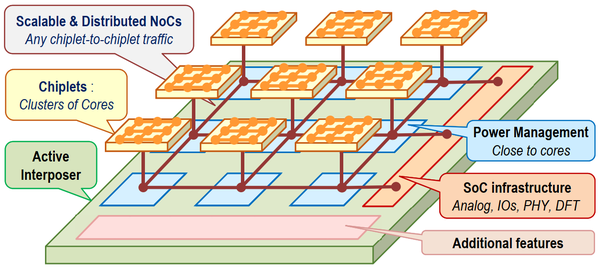
图11. Active Interposer
文中提出的架构的主要特征如下:
- 功能单元划分为多个Chiplet。Chiplet内部采用NoC互联。
- Chiplet之间利用NoC互联,提高带宽,降低平均延迟。
- Chiplet和基板采用不同的工艺。Chiplet采用比较新的工艺,充分榨取先进工艺的红利,比如数字逻辑。基板采用比较老的,稳定的工艺,节约成本,提高良率,比如模拟电路或数模混合电路。
- 基板的电路都按照通信要求进行排布。与处理器核紧密度高的电路就放到处理器核附近。需要与芯片外进行交互的,就放到芯片边上。
原型芯片配置
原型芯片的Chiplet采用28nm工艺制造。每个Chiplet提供4个处理器簇,每一簇提供4个MIPS32v1处理器核。所以,一个Chiplet上有16个处理器。
- 层次化缓存:
- 每个处理器独享16KB L1I,16KB L1D。
- 每个簇提供256kB L2缓存。全局共享分布式缓存。
- 每个Chiplet提供4 MB共享L3缓存。全局共享分布式缓存。
基板采用65nm工艺制造。每个基板上放置6个Chiplets,所以一块芯片包含了96个core。基板为每一块Chiplet提供了集成的SCVR(开关电容电压调节器)控制器。基板提供了内存控制、系统IO,DFT等单元。
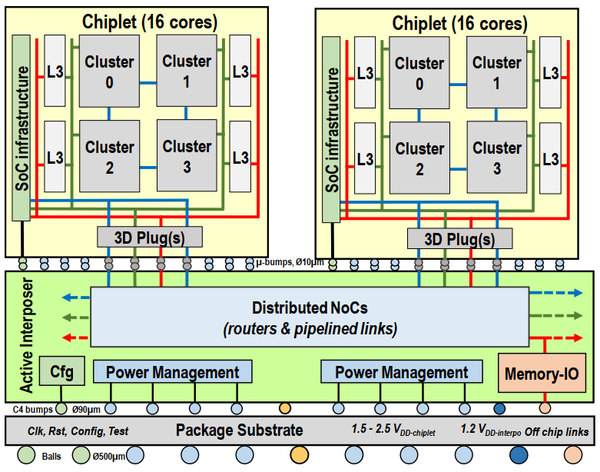
图12. 原型芯片示意图
片上网络配置
芯片中配置了三套片上网络,图12和图13中的蓝色、绿色和红色。其中
- 蓝色:5通道2D-Mesh互联,被动链路。蓝色互联用于短距离请求,连接的是私有L1和共享L2之间的通信。传输宽度为40比特。实际上,蓝色网络只与邻居节点相连。如果需要更远距离通信,则需要在Chipset中进行路由到另一端,在回到基板。最近通信距离1.5mm,延迟8个周期左右,延时7.2ns。最远通信距离15nm,延迟44个时钟周期,延时44ns。Chiplet内部互联5mm,需要8ns(内部打断为8级)。
- 绿色:2通道2D-Mesh互联,QDI异步通信链路。绿色互联用于长距离请求,连接的共享L2和共享L3之间的通信。传输距离25mm。传输延迟与异步通信有关,大约15.2ns。
- 红色:2通道2D-Mesh互联,同步主动链路。红色互联用于长距离请求,连接的是共享L3和外部内存之间的通信。传输距离25mm。传输延迟37个时钟周期,延时49.5ns。路由器和路由器之间的电路按照每1mm一级插入FIFO,一条链路要插入8个FIFO,形成8级流水。
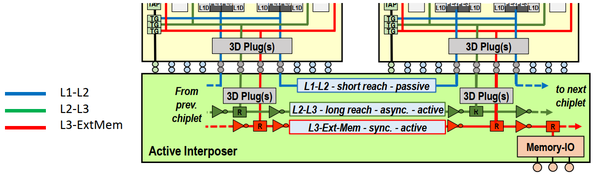
图13. 基板片上网络示意图
分析
这一架构的并不非常独特。如果从上向下看图10的结构,这块芯片就是一个标准的CPSoC的架构。处理器簇按照矩阵排列,通过矩阵网络互联。内存控制器、外设等都连接在Mesh网络周边的节点上,将处理器围绕在中间。可见,Chiplet对于架构的影响还是比较有限的。
这篇文章还有一点值得关注的是其工艺。不管是基板还是Chiplet层上都是有逻辑的。不过从幻灯片上公开的照片来说,正对在Chiplet下面主要是互联和接触球。电路逻辑还是放在Chiplet之间的空白位置上的。
Intel Lakefield (8.1)
这篇文章的重点几乎不在处理器架构上,而完全在Intel的3D封装工艺上。相对于Chiplet,Intel的3D封装似乎没有引起很大的关注。实际上,Intel的3D封装技术突破了之前3D封装的限制,实现了逻辑电路的层叠。AMD使用的Chiplet仍然只有1层Die,其基板类似于PCB,没有逻辑只有走线。CEA研究院的原型芯片的基板是有逻辑的。Foveros实现了两层逻辑电路Die的堆叠,而且用于量产。这是一个很大的进步。
Lakefield架构
Lakefield是Intel的最新处理器架构,用于10代酷睿处理器,主要面向小型设备和移动设备市场。这一代处理器的核心特点是大小核配置。
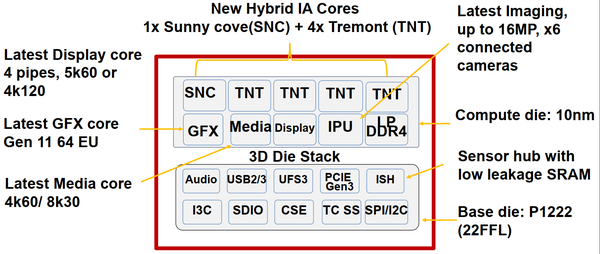
图15. Lakefield的功能模块框图
图15展示Lakefield的功能模块框图。因为Lakefield使用3D堆叠封装工艺,所以图15中的功能模块也被分为两部分。
上半部分中的功能模块称为Top Die,使用10nm工艺制造,提供了:
- 1个Sunny Cove处理器核作为大核,最求更高的单核性能。
- 4个Tremont处理器核作为小核。可以发挥多核优势,得到很好的整体性能;也可以体现低功耗优势,延长电池寿命。
- GFX Gen11 64 EU集成显示控制器。
- 多媒体核心,支持4k@60Hz或8k@30Hz
- 图像处理器,支持16M像素,最多连接6个摄像头。
- LPDDR4接口。
Intel采用的是1大核4小核的配置,这与ARM的配置方法不同(见下一节“SoC处理器”)。对于Intel来说,除了Suny cove的单核性能强于Tremont之外,4个Tremont核可以通过多核并行的方法在性能上反超Sunny cove,如图16所示。这预计会使得的Lakefield的调度策略更加复杂。
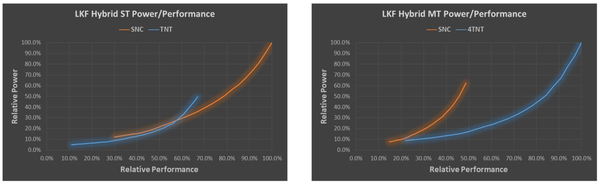
图16. Lakefield大小核性能比较
下半部分的功能模块称为Base Die,使用22nm工艺制造,提供了:
- 音频接口。
- USB2.0/3.0,UFS3,I3C,SDIO,CSE,TC SS,SPI/I2C等外设接口。
- 传感器接口ISH。
- PCIE Gen3。
可见,与CEA Chiplet的分工类似,上层使用较新的工艺,实现高速高效的数字电路;下层则使用较成熟的工艺,实现模拟或数模混合电路。
Forveros 3D封装技术
就3D封装而言,Intel做得还是相当不错的。从图17分析,Intel一共封装了三层,最底层是基板,采用22nm,完成外设和数模混合电路;中层是计算层,采用10nm工艺,实现处理器核、集成显卡、显示以及DDR4接口等;最上层是存储层,实现片内存储。基板层和计算层是Forveros技术,采用的是TSV互联。基板和内存层中间也是采用了接触球的方法,称为POP内存。
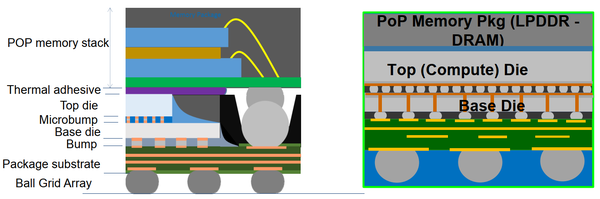
图17. Intel的3D封装
分析
3D封装自提出那天就对于芯片设计很有吸引力。因为3D封装可以真正的减少芯片互联距离和芯片的面积。Intel宣称Lakefield的连线功耗仅仅是6代Core的8%。最终封装成片也只有12x12x1mm,小于一个硬币。从而可以适用于移动设备,比如surface等。
在之前,将内存叠加到逻辑芯片上的POP内存工艺已经是得以实现,并且广泛应用于移动设备处理器。但是将逻辑芯片堆叠到一起,主要面临的挑战是良率和热。良率的问题在于,如果两个芯片没有对齐,那么整个芯片就报废了。对于内存,还可以通过阉割来拯救;对于逻辑芯片,这个芯片都会失败。而热则是更大的问题。因为逻辑芯片是处理器热的主要来源。将两层Die叠在一起,下层的热不容易散出去,可能导致芯片过热。显然,这些问题已经得到了解决。不过Intel的3D工艺短期内不太可能拿出来给大家代工,不过TSMC也有类似的工艺推出。
SoC处理器
Session 2发布了三款移动SoC,分别面向智能手机和自动驾驶市场。移动SoC都采用了ARM处理器或者ARM指令集处理器。ARM独霸SoC处理器的天下。
三星 (2.4)
三星发布的面向移动端市场的处理器属于一款实验芯片,采用7纳米工艺。芯片的主要特点是采用了大-中-小核三级配置来满足从最低性能到最高性能的平滑过渡。
处理器架构
芯片的处理器架构如图18所示。
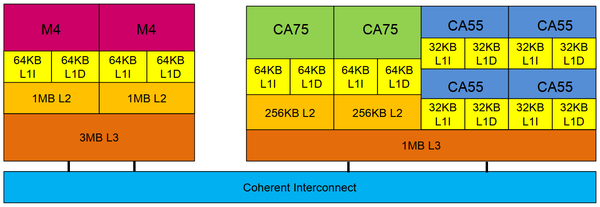
图18. 大核-中核-小核的三级处理器架构
芯片使用2颗三星自研M4处理器核作为大核,频率2.73GHz。每个核私有64KB L1I缓存、64KB L1D缓存,以及1MB L2缓存。两个核共享3MB L3缓存。大核不与中核和小核共享缓存。
芯片使用2颗Cortex A75作为中核,频率2.4GHz。每个核私有64KB L1I缓存、64KB L1D缓存,以及256KB L2缓存。芯片使用4颗Cortex A55作为小核,频率2.0GHz。每个核私有32KB L1I缓存、32KB L1D缓存,没有L2缓存。中核和小核共享1MB L3缓存。
大核与中-小核通过互联网络连接(同样是ARM的IP)。
三星M4处理器核
文章和幻灯片花费了一些篇幅来介绍三星自研M4处理器的技术参数。
- 6发射。译码、重命名、发射和退出宽度都是6条uop。
- 改进了分支预测。采用基于神经网络的主预测器。提供128个单元的uBTB,4K单元的主BTB,32K单元分支的L2BTB(较M3翻倍)
- 228个单元的ROB。
- 整形计算提供2个简单ALU和2个复杂ALU。
- AGU提供1个Load、1个Store以及一个Load/Store复用通道。
- 通过从内存控制器的直接连接改进访存延迟。
- 每个核私有1MB L2缓存(较M3翻倍),共享3MB L3缓存(较M3提高50%)。
- 48单元DTLB(较M3提高50%),512个单元DBTLB,4K单元L2 UTLB。
- 三个128比特浮点流水线,每个周期同时进行24个单精度操作。
- FADD:2周期、FMUL:3周期、FMAC:4周期。
- 两个128比特的点乘浮点计算单元(与int8乘),用于机器学习。
根据幻灯片的结果,M4处理器全面优于M3处理器和Coretex-A76,优于i5-7500@3.0GHz。
任务调度
如图19所示,只采用大小核两级,在大核和小核之间存在一段缺口。落在这段缺口中的应用,如果分配到小核,则会出现性能不足的现象;如果到大核,则功耗较高。采用三级配置可以实现从小核的最低性能到大核的最高之间全谱系的平滑运动。
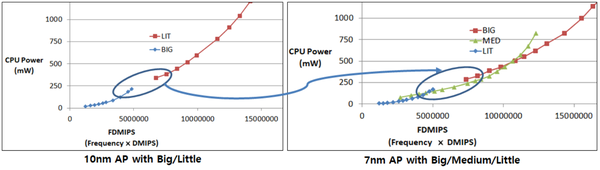
图19. 大核-中核-小核的三级配置的动机
三核的任务调度较为复杂,虽然中核填补了大小核之间的缺口,也同时与小核和大核都形成了全面的重叠。在重叠区域的选择中,文章提出三个需要考虑的因素:性能需求、功耗和指令集。根据需要的性能在功耗模型上选择对应位置功耗较小的核。文章还提出,功耗模型应该考虑指令集。处理器对于32位指令集和64位指令集的功耗模型是不同的,不能一概而论,这就是文章所谓的基于ISA的调度器。
联发科 Dimensity 1000 (2.5)
联发科发布的是其旗舰级5G智能手机芯片,芯片型号天玑(Dimensity 1000)。芯片采用7nm工艺制造,频率达到2.6GHz。芯片支持5G蜂窝网、WiFI 6、高性能计算、多媒体和AI。
芯片技术参数
大小核处理器:
- 4个Cortex A77作为大核,最高2.6GHz,每个核私有64KB L1D缓存,64KB L1I缓存。四个核共享256KB L2缓存。
- 4个Cortex A55作为小核,最高2.0GHz,每个核所有32KB L1D缓存,32KB L1I缓存。四个核共享128KB L2缓存。
- 所有处理器共享2MB L3缓存。
无线通信模块:
- 5G模块:SA和NSA网络,4.7Gbps下行,2.5Gbps上行,完全向前兼容(即GSM、CDMA、LTE全兼容)。
- 支持Wi-Fi 6,802.11,蓝牙,GPS,FM
图形模块:
- ARM-Mali G77 MC9 3D,全高清 120Hz
- 80M像素图片处理器,支持32+16M像素双摄像头。
- 支持HEVC和AV1,4K 60FPS编解码能力。
AI:
- 自研APU 3.0 Hexa-core AI,2大+3小+1微,4.5TOPS。
互联:
- AXI64/128比特互联。
Cortex A77微架构
幻灯片作为福利放出了A77的微架构,以及相关改进,如图20所示。
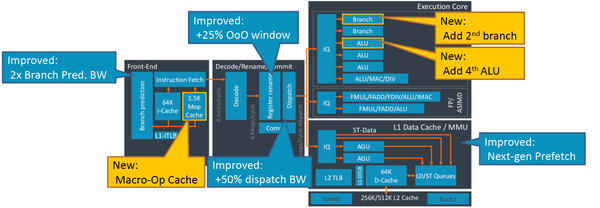
图20. Cortex A77微架构
主要变化有:
- 增加了宏指令(Macro op)缓存。
- 增加了第2个分支指令执行单元和第4个ALU。后端总共提供2个分支指令执行单元,4个ALU指令执行单元,其中1个还可以执行MAC和DIV操作。
- 改进了分支预测,可以一次预测两条分支。
- 增加了25%的乱序窗口。
- 增加了50%的发射带宽。
- 改进了Prefetch。
Cortex A77处理器较A76处理器可以提高20%的跑分。
TI Jacinto™ 7 (2.6)
Jacinto是OMAP和Keystone II平台的改进版,主要面向自动驾驶场景,设计重点考虑安全(Security)。其主要设计特点是三套几乎独立的计算机系统。
Jacinto的系统框图如图19所示,其中有三个独立的Domain组成,分别是唤醒Domain,MCU Domain和主Domain。不同的Domain用来满足不同的安全等级(ASIL,参见ISO-26262)
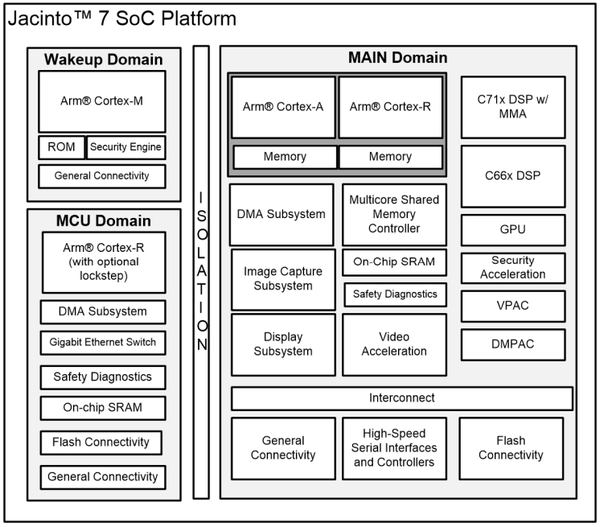
图21. Jacinto系统框图
唤起Domain
唤起Domain集成ARM Cortex-M系列MCU,提供Rom,安全引擎和通用连接。唤起Domain用来管理安全模式和低功耗模式,包括:启动管理、加密加速、可信执行、加密保存等。满足最强安全性要求。运行时钟1GHz。
MCU Domain
MCU Domain,包含一个完整的MCU系统。这个Domain使用ARM Cortex -R处理器,提供DMA、Gb以太网、片上SRAM、Flash,通用连接以及安全检查。Domain具有独立的电源、时钟和复位信号。满足最强安全性要求。运行时钟1GHz。
Main Domain
Main Domain,包含一个功能更加丰富的MCU系统,分别计算簇和加速器簇。满足较弱的安全要求(倒数第二级)计算簇包括:
- ARM Cortex-A处理器核,运行时钟2GHz。
- C71x DSP。
- 提供L1/L2/L3缓存,支持一致性内存,支持虚拟化。
- C66x DSP,对音频应用优化。
- 高性能GPU。
- 内存接口LPDDR4-4266。
加速器簇包括:
- 视觉预处理加速器VPAC
- 深度和运动感知动态加速器DMPAC
- 视频加速器H.264/H.265
- 图像捕获(MIPI CSI-2 RX/TX)
- 显示:eDP,MIPI DSI,MIPI DPI
- 安全加速器:PKA、AES、SHA、RNG、DES/3DES。
对于实际应用场景,TI是这样设想的:唤起Domain独立运行,用来管理安全模式和低功耗模式。MCU Domain和主Domain相互配置。主Domain运行丰富的应用,MCU Domain作为对主Domain的监控。如果主Domain发生错误,那么MCU Domain会采取措施,保证驾驶安全。
分析
介绍SoC芯片的文章都没有将重点放在处理器核上,所以这几篇文章并不是我关注的重点。SoC芯片的主要特点都是异构集成。一颗SoC中,通过集成不能性能要求的处理器核以及各种各样的加速器,满足SoC需要的丰富的功能,同时控制功耗。ARM很早就提出了大-小核配置。不过为了实现从最低性能到最高性能的平滑调度,三星和高通使用了大-中-小核三簇处理器核的配置,使得性能迁移之间没有跳跃点。
最后,不得不感慨一下,虽然还有一款M5,本届ISSCC的这篇原型芯片恐怕是三星自研CPU核的绝唱了。有点可惜,但是也体现出了处理器核研发的困境,强大的先发优势和日渐缩小的设计优化空间,使得处理器核的研究很可能成为“费力不讨巧”的工作。
总结
看完所有这些9篇论文,本人有这样一些体会:
- 从文章数量的分布来说,目前的处理器设计走向两个方向:追求极致性能的通用CPU(Intel、AMD、IBM)和追求性能-功耗比、面向特性领域、单片集成丰富功能的SoC(三星、联发科和TI)。这种趋势由来已久。前者的设计空间正在缩小;而后者有着广阔的应用场景和设计空间。
- 追求极致的CPU的道路依然是在x86体系下发展,被Intel和AMD垄断。在这个领域内,有一种说法,相对于架构优化,Intel更加依赖于工艺发展;AMD比Intel的架构优化更加激进。从今年的论文中可以佐证一些。Intel推出了能够堆叠逻辑Die的真3D工艺,但是却不幸地在芯片跑分上被AMD超越。
- CPU性能的提升,更多的是依靠工艺的进步和资源的累加,但是面向不同市场的芯片堆资源的思路不同。通用CPU主要是堆核芯,继续在同构多核的道路上前进;移动SoC则是堆各种加速器,继续在异构多核的道路上前进。通用CPU集成加速器也是一种潮流。IBM的Z15中就集成了压缩和加密加速器。未来,异构集成架构将是处理器研究的主流,即便是追求极致性能的x86处理器也不得不接受这一事实。
- 对于单个处理器核,资源累加仍然是有效的,包括:增加L1、L2、L3 cache容量,增加micro-op cahce以及其容量,扩展取指、译码、发射等乱序执行的宽度,增加执行单元,增加LSU等。单核芯片的优化逻辑是:首先增加资源;然后通过架构调整使得时钟、功耗等满足设计要求;再接下来由物理设计来解决时序和功耗问题;最后,如果还不能解决,那就只能再减少资源了。
- Chiplet技术将会开始落地,但是对于架构的影响程度,目前不得而知。目前来看,Chiplet下芯片的架构仍然是现有芯片架构的延伸或者分解。相关互联架构在NoC和板级互联领域都有研究。3D技术的落地还有一定的难度,Intel不会开放代工。Chiplet最主要的影响还是对设计流程的影响,期待这方面的落地。大家现在都只能猜测其落地的形式。
- 物理设计和数模混合设计对于处理器的实现非常重要。其重要程度甚至高于前端设计或架构设计。在很多情况下,前端逻辑设计引入的大量资源需要后端设计通过工艺优化和电路优化进行调整。比如,文章里面多次提到7nm工艺对于物理设计的影响,以及如何改进DRAM架构和标准单元从而显著扩大片上cache。
- 多核处理器的任务调度、功耗管理仍然是一个很有趣的话题。多篇文章提到了为了满足功耗要求,他们优化的时钟单元和功耗管理电路;还有文章提到优化传感器和时钟电路以改善由于高负载而引起的IR压降等;还有文章提到如何在处理器核之间上调度任务。解决这方面的问题是需要电路层面和架构层面协同解决的。
- 也许是由于ISSCC会议的特点,物理设计对于实现性能提升的作用非常大。前端疯狂堆积的资源引起的时序和功耗问题,都需要后端通过物理设计来消化。有多篇文章都提到如何优化SRAM结构来达到提高频率,降低功耗。
致谢
感谢多位同事和好友对于本文提出的意见。
本人才疏学浅,对于处理器的理解尚需提高,请大家多批评指正。
END
知乎:https://zhuanlan.zhihu.com/p/112267697
推荐阅读
更多内容请关注其实我是老莫的网络书场专栏

