

关于上一章
上一章节讨论了用于支持 QoS(Quality of Service)的机制,并描述了对网络结构中传输的不同数据包的传输时间和带宽进行控制的意义。这些机制包括,特定应用的软件会给每个数据包分配优先级,以及在每个设备内构建可选的硬件来启用事务优先级管理。
关于本章
本章节将会讨论 PCIe 拓扑结构中事务(transcation)对排序(ordering)的要求。这些规则是继承自 PCI 的,它们许多都受到“生产者/消费者(Producer/Consumer)”程序设计模型的推动,因此在本章内会描述这个模型的机制原理。原始的规则中还考虑了那些必须要避免的死锁情况。
关于下一章
下一章节将会描述 Data Link Layer Packet(DLLP,数据链路层包)。我们将会描述其用途、格式以及 DLLP 数据包类型的定义,也将会对其相关字段的细节进行描述介绍。DLLP 可以被用来支持 Ack/Nak 协议、电源管理、流控机制,还可以被用来做一些 vendor 自定义的事情。
8.1 介绍(Introduction)
和其他协议一样,对于同时要在网络拓扑中进行传输的、拥有相同 TC(Traffic Class,流量类型)的事务,PCIe 规定了它们之间的排序规则。而拥有不同 TC 的事务之间则并不存在排序关系。对相同 TC 的事务指定排序规则的原因有:
- 维持与传统总线的兼容性,例如 PCI、PCI-X 和 AGP。
- 保证事务的完成是确定的(deterministic),且是按照程序员想要的顺序进行的。
- 避免死锁情况。
- 通过将最小化读取延时和读写顺序管理,实现性能和吞吐量最大化。
具体的 PCI/PCIe 事务排序的实现基于以下的特性:
- 生产者/消费者编程模型(Producer/Consumer),它是基本排序规则的基础。
- 宽松排序(Relaxed Ordering),当请求者知道某个事务与先前的事务没有任何依赖关系时,则允许出现宽松排序。
- ID 排序(ID Ordering),在 ID 排序规则下,Switch 可以允许来自某一个设备的请求先于另一个设备的请求,因为这两个设备正在执行不相关的线程。
- 一些避免死锁情况的方法以及支持 PCI 传统设备实现的方法。
8.2 定义(Definitions)
在数据流中有三种通用模型用于事务排序:
- 强排序(Strong Ordering):对于在 PCIe 结构中传输的拥有相同 TC 的多个事务流,PCIe 要求使用强排序规则。拥有相同 TC 的事务们也会被映射到同一个给定 VC,因此每个 VC 中也要应用强排序规则。因此,当多个 TC 都被映射到同一个 VC 时,这些 TC 的所有事务都会被当做同一个 TC 来进行处理,即使不同的 TC 之间的事务之间不存在排序关系。
- 弱排序(Weak Ordering):除非事务需要重新排序,否则它们将维持原来的顺序。由于某些给定的事务模型(例如 Producer/Consumer 模型)相关的依赖性,维持事物间的强排序关系可能会导致所有的事务都被阻塞。而被阻塞的事务中,有些与依赖关系并不相关联,它们就可以安全地被重新排在阻塞的事务之前。
- 宽松排序(Relaxed Ordering):在且仅在某些可控的情况下,事务可以被重新排序,它的好处是可以像弱排序模型一样提升性能,但是它仅在软件指定时才会这样做,以此来避免依赖问题。而它的缺点则是仅有部分事务可以得到性能上的优化。软件启用宽松排序(RO,Relaxed Ordering)也需要一些额外开销。
8.3 简化后的排序规则(Simplified Ordering Rules)
PCIe 2.1 版本中介绍了一种简化版的排序规则表,如所示。这个表格可以按主题划分如下:
- 生产者/消费者(Producer/Consumer)规则
- 宽松排序(RO)规则
- 弱排序规则
- ID 排序规则
- 死锁的避免
后续小节中会给出与各个排序模型、操作、基本原理、情况以及要求相关的细节内容。
8.3.1 排序规则与流量类型(Ordering Rules and Traffic Classes)
PCIe 中的排序规则会应用于拥有相同 TC(Traffic Class,流量类型)的事务之间。对于那些在网络结构中传输的具有不同 TC 的事务来说,并没有针对它们的排序要求,可以认为它们各自的应用程序之间是没有关联的。因此对于不同 TC 的数据包来说,也就不存在由于事务排序而带来的性能降低问题。
对于拥有相同 TC 的数据包来说,当它们在 PCIe 网络结构中传输时,有可能会经历性能降低。这是因为 Switch 和设备们必须要支持一些排序规则,而这可能会要求将数据包延迟,或者在先发送来的数据包之前将后发送来的数据包转发出去。
如 Chapter 7“Quality of Service //服务质量” 一章中讨论的那样,拥有不同 TC 的事务可能会被映射到同一个 VC。TC-to-VC 映射关系的配置决定了一个给定了 TC 的数据包将会被映射到哪一个指定的 VC 去。尽管事务排序规则仅应用于相同 TC 的数据包之间,但是可能也存在简化的 EP/Switch/RC 设计,它们将事务排序规则应用在同一个 VC 中的所有数据包之间,即使在一个 VC 中可能含有多个 TC 的数据包。
显然,映射到不同 VC 的数据包之间没有排序关系,无论它们的 TC 是多少。
8.3.2 基于包类型的排序规则(Ordering Rules Based On Packet Type)
PCIe 协议规范中定义的排序关系是基于 TLP 类型的。TLP 被分为三个种类:
1) Posted
2) Completion
3) Non-Posted
Posted 种类的 TLP 包括 MWr 请求(Memory Write request)与 Message(Msg/MsgD)。Completion 种类的 TLP 包括 Cpl 与 CplD。Non-Posted 种类的 TLP 包括 MRd、IORd、IOWr、CfgRd0、CfgRd1、CfgWr0 以及 CFGWr1。
在下一小节中使用了一个表格(表 8‑1)来描述事务的排序规则,你将会看到这个表格中列出了上面提到的三个种类的 TLP 以及它们所定义的排序关系。
8.3.3 简化后的排序规则表(The Simplified Ordering Rules Table)
该表按照行事务是否可以超越列事务(Row Pass Column) 的方式对内容进行组织。所有的排序规则都在简化后的排序表(表 8‑1)之后进行总结概括。每种规则,或者每组规则,都定义了它们要求的操作内容。
在表 8‑1 中,列 2 至列 5 代表先前已经被 PCIe 设备发送的事务,而行 A-行 D 则代表 1 个刚刚到达的新的事务。对于出站事务(outbound transaction),该表指定了行(A-D)所代表的事务是否可以超越一个由列(2-5)所代表的先前的事务。表中的“No”表示行事务不允许超过列事务,“Yes”表示必须允许行事务超过列事务以此来避免死锁,而“Yes/No”则表示行事务可以超过列事务但是并不要求一定要这么做。表中各个条目均有其含义。
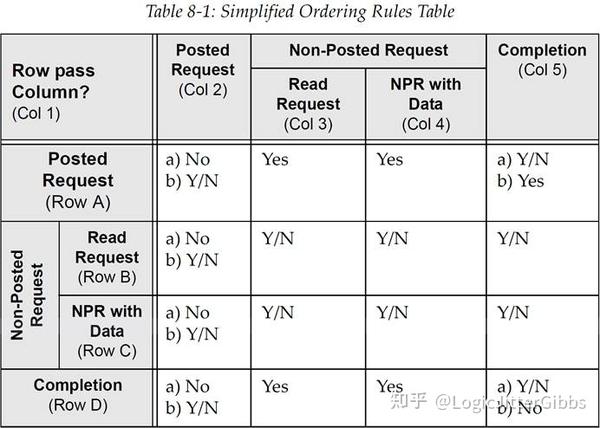
表 8‑1 简化后的排序规则表
译注:以下规则名称第一个字母代表上表中的行号,第二个数字代表上表中的列号,例如 A2a 和 A2b 表示不同情况下,第 A 行与第 2 列之间的排序规则
- A2a,B2a,C2a,D2a:为了执行生产者/消费者模型,后来的事务不允许超过超过一个先前的 Posted 请求。
- D2b:如果设置了 RO(Relaxed Ordering),那么一个 Read Completion 是可以超过一个先前已排队的 MWr 或是 Message 请求的。
- A2b,B2b,C2b,D2b:如果使用了可选的 IDO(ID Ordering),那么后来的事务是允许超过一个 Posted 请求的,只要它们两个的 Requester ID 不同。
- A3,A4:一个 Mwr 或者 Message 请求必须要可以超过 Non-Posted 请求,以此来避免死锁。
- A5a:Posted 请求可以但不必要超过 Completion。
- A5b:避免死锁的情况。在一个 PCIe-to-PCI/PCI-X Bridge 中,为了让事务从 PCIe 传到 PCI 或 PCI-X,Posted 请求必须要能超过 Completion,否则将有可能发生死锁。
- B3,B4,B5,C3,C4,C5:这些情况实现弱排序,且不会有任何与排序相关问题的风险。
- D3,D4:Completion 必须要能超过 Read、IO 或者是配置写请求(Non-Posted 请求),以此来避免死锁。
- D5a:拥有不同事务 ID 的两个 Completion 都可以超过对方。
- D5b:拥有相同事务 ID 的 Completion 们不能超过对方,要保持原排序。这是为了保证在给单个请求返回多个 Completion 时,仍然可以保持地址的递增顺序。
8.4 生产者/消费者模型(Producer/Consumer Model)
这一节将会描述 Producer/Consumer(生产者/消费者)模型的操作方式,以及为了正确执行这个模型所需要的排序规则。图 8‑1 中简单的展示了一个用于示例的拓扑结构。在接下来的基于该拓扑结构的第一个示例中将会描述 Producer/Consumer 模型在使用合适的排序规则时的操作方式,然后会再给出一个例子用于描述 Producer/Consumer 模型在使用不合适的排序规则时导致操作错误的失败情况。
Producer/Consumer 模型是 PCI 和 PCIe 中数据传输时的常用方法。这个模型由图 8‑1 中所展示的 5 个元素所组成:
- 数据的 Producer(生产者)
- 内存数据 Buffer
- 用于指示数据已经由生产者发送的 Flag semaphore(标志信号量)
- 数据的 Consumer(消费者)
- 用于指示消费者已经读取了数据的 Status semaphore(状态信号量)
协议规范中指出,无论所有的相关的元素是如何排列放置的,Producer/Consumer 模型都会执行工作。在本例中,Flag 和 Status 元素都位于同一个物理实体设备,但是其实它们也可以位于不同的设备中。
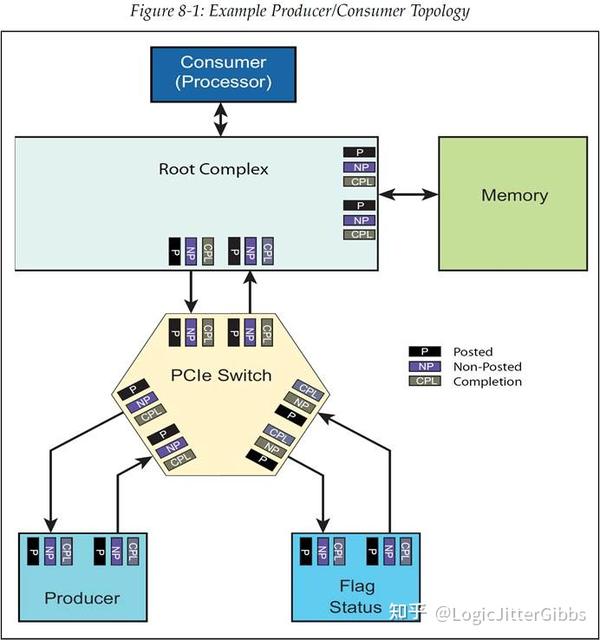
图 8‑1 生产者/消费者拓扑示例
8.4.1 正确的生产者/消费者流程(Producer/Consumer Sequence-No Errors)
下列的讨论请参照图 8‑2。该示例中假设开始时 Flag 和 Status 元素已经被清除复位。这两种信号量在本例中都位于同一个设备中。下面的描述中带有序号的事件流程,以及图 8‑2 所示的流程,都反映了正确排序规则流程的第一部分。
- 在示例中,一个被称为 Producer(生产者)的设备将会执行一个或多个 Mwr 事务(Memory Write,Posted 请求),要写入的位置为内存(Memory)中的一个数据 Buffer。在数据流通过 Posted Buffer 时可能会产生一些时间延迟。
- Consumer(消费者)会周期性的通过发起 MRd 事务(Memory Read,Non-Posted 请求)来检查 Flag 信号量,以此来确定数据是否已经被 Producer 发出。
- Flag 信号量被 Consumer 设备读取,并以 MRd Completion 的形式返回给 Consumer,用于告知 Consumer 数据还没有被 Producer 发送出(因为此时 Flag=0)。
- Producer 通过发送一个 MWr(Posted 请求)来将 Flag 的值更新为 1.
- 又一次地,Consumer 发起步骤 2 中相同的事务(MRd,Non-Posted)来读取 Flag 的值。
- 这一次,Consumer 读取到的 Flag 的值为 1,这也就是说 Consumer 通过这次 MRd Completion 得知了所有的数据都已经被 Producer 发往内存(Memory)了。
- 然后,Consumer 发起一个 MWr 事务(Posted 请求)来将 Flag 信号量清除为 0。
图 8‑3 继续展示了示例的第二部分流程。
8. Producer(生产者)现在有更多的数据需要发送,它通过发起 MRd 事务(Non-Posted 请求)的方式周期性的检查 Status 信号量。
9. Status 信号量被 Producer 设备读取,并以 MRd Completion 的形式返回给 Producer,用于告知 Consumer 还没有读取内存中的数据 Buffer 并且也没有更新 Status 信号量,因为 Status=0。
10. 对于 Consumer,它现在已经知道了内存 Buffer 中有可用数据,所以它会发起一个或多个 MRd(Non-Posted 请求)来从 Buffer 中获取这些数据。
11. 内存 Buffer 的内容被读取并返回给 Consumer。
12. 在完成了内存到 Consumer 的数据传输后,Consumer 发起一个 MWr(Posted 请求)将 Status 信号量置为 1。
13. 又一次地,Producer 通过发起 MRd(Non-Posted 请求)来检查 Status 信号量。
14. Producer 设备读取 Status,而此时 Status=1。MRd Completion 返回给 Producer,从而 Producer 也就知道了内存 Buffer 中的数据已经被 Consumer 读出,那么 Producer 就可以继续向内存 Buffer 发送数据了。
15. Producer 通过发起 MWr 来将 Status 信号量清除为 0。
16. Producer 重复以上按顺序从步骤 1 开始的一系列事件。
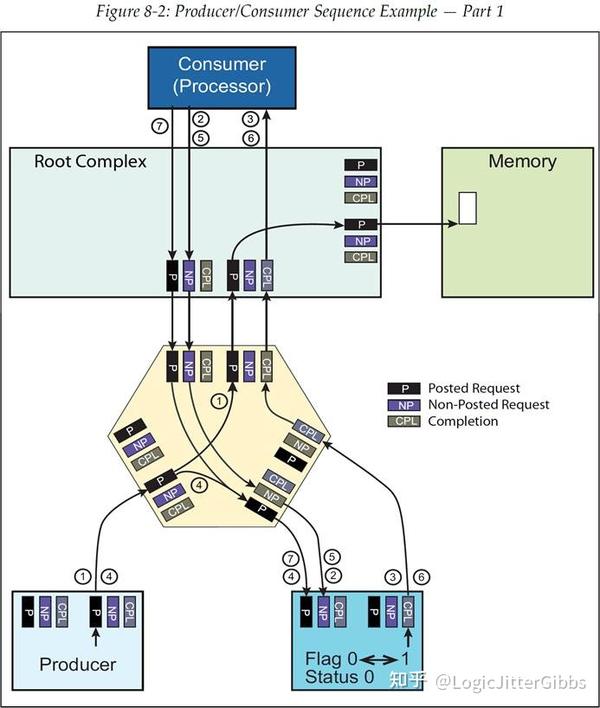
图 8‑2 生产者/消费者流程示例——第一部分
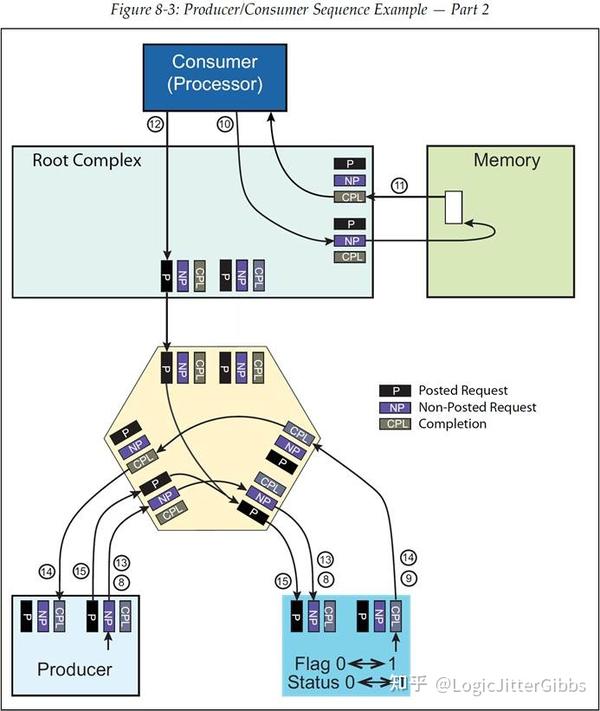
图 8‑3 生产者/消费者流程示例——第二部分
8.4.2 出错的生产者/消费者排序(Producer/Consumer Sequence-Errors)
前面的例子在没有讨论排序规则的情况下正确的执行了 Producer/Consumer 模型,但是它有可能会受到竞争情况的影响而导致 Producer/Consumer 模型执行流程失败。图 8‑4 中展示了一个简单的流程用于演示在没有执行排序规则的情况下可能出现的多种问题中的一种。在进行下列讨论时请参照图 8‑4。
- Producer 向内存 Buffer 发起 MWr 事务(Posted 请求)。我们假设要写入的数据被暂时地阻塞在了 Switch 上行端口的 Posted 流控 Buffer 中。
- Producer 发送一个 MWr 事务(Posted 请求)来将 Flag 更新为 1。
- Consumer 发起 MRd 请求(Non-Posted 请求)来检查 Flag 是否被置为 1。
- Flag 的值通过一个 Completion 返回给 Consumer。
- 由于 Flag=1,Consumer 认为数据已经从 Producer 发送给内存 Buffer 了,因此它就发起 MRd 请求来获取内存 Buffer 中的数据。然而 Consumer 并不知道,由于 Switch 上行端口和 RC 之间链路的流控 Credit 不足,导致数据被暂时地阻塞在 Switch 上行端口的 Posted 流控 Buffer 中。结果,Consumer 从返回的 MRd Completion 中所获取到的数据是内存 Buffer 中原有的旧数据而不是 Producer 此次发出的新数据。
这个问题可以通过拓扑结构中的 Virtual PCI Bridge 所支持的排序规则来避免。在本例中,当 Consumer 在执行步骤 3、4 的 MRd 事务时,Switch 上行端口的 Virtual PCI Bridge 不能让含有 Flag 值的 Completion 超前于此前的 Posted MWr 的数据被转发(这个 Completion 和 MWr 事务都要经过 Switch 的上行端口转发)。这种情况就是表 8‑1 中的 D2a。
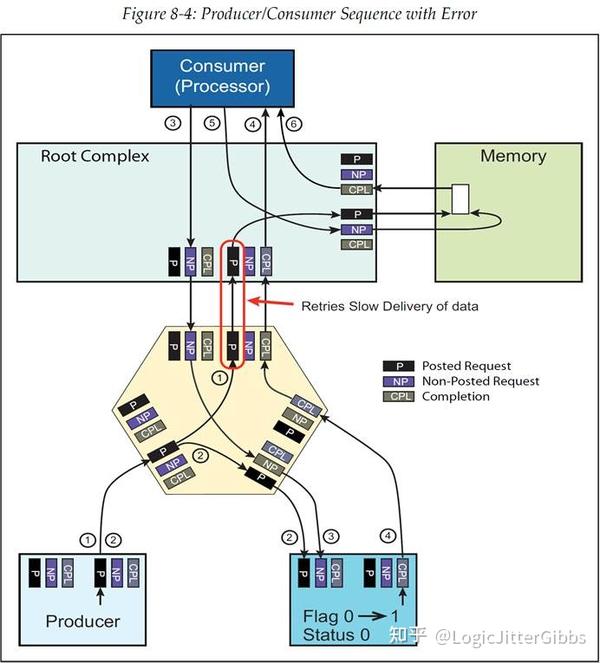
图 8‑4 出错的生产者/消费者流程
8.5 宽松排序(Relaxed Ordering)
PCIe 中支持 PCI-X 引入的宽松排序机制(Relaxed Ordering,RO)。RO 机制允许 Requester 和 Completer 之间路径上的 Switch 对一些事务进行重新排序,以此来提高性能。
用来支持 Producer/Consumer 模型的排序规则可能会导致事务在某些情况下被阻塞,即使这些被阻塞的事务与 Producer/Consumer 模型的工作流程毫无关系。为了减少这种问题,可以将一个事务的 RO 属性位置为 1,这表示软件确定这个事务与其他事务没有任何关联,允许它重新排序在其他事物之前。例如,如果一个 Posted 的写事务因为目的 Buffer 空间不足而被延迟阻塞,那么必须要等到这个写事务的阻塞问题解决并且写事务发送完成后,才能发送后续的任何事务。如果在后续到来的事务中,有一个事务是软件确定它与其他此前的事务没有关联,且它的 RO bit 也被置为 1 以此来表示这种无关联性,那么在 Posted 写请求解决阻塞问题之前就可以发送这个事务,而不用让它也等待写请求,且这样做并不会引发任何问题。
当设备驱动支持并启用 RO bit(如图 8‑5 所示,它在 TLP Header 中 DW0 的 Byte2 中的 Bit5),设备才有可能会使用它。然后,当软件请求发送一个数据包时,这个请求包要根据软件的指示来使用 RO 这个属性位。当 Switch 或者 RC 发现一个数据包的 RO bit 是置为 1 的,那么它们就可以对这个数据包进行重排序,但是并没有强制要求它们一定要这样做。
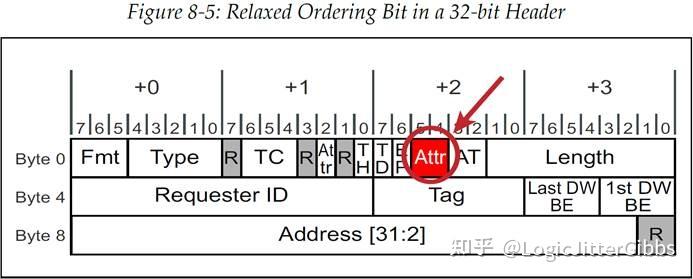
图 8‑5 宽松排序标志位在 32bit Header 中的位置
8.5.1 RO 对 MWr 和 Message 的影响(RO Effects on MWr and Message)
Switch 和 RC 必须观察事务的 RO 属性位的值。MWr 和 Message 都是 Posted 写事务,都由同一个 Posted Buffer 来接收,也都遵从同一个排序要求。当 RO bit 为 1 时,Switch 处理这些事务的方式如下:
- 允许 Switch 对刚下发的 MWr 事务(RO bit=1)进行重新排序,使其可以排在先前下发的 Posted MWr 或是 Message 事务之前。类似地,刚下发的 Message 事务(RO bit=1)也可以可以重新排在先前下发的 Posted MWr 或是 Message 事务之前。Switch 在转发事务时也必须保持 RO bit 不改变。PCI-X Bridge 会忽略 RO bit,它总是按照原顺序转发写事务(PCI-X 中让写事务改变顺序并没有太大作用,如果一个写事务因为某些原因被阻塞了,那么即使更改了顺序,被提前的那一个写事务也还是会被阻塞)。另一个不同就是 PCI-X 中并没有定义 Message 事务。
- 允许 RC 对 Posted 写事务进行重新排序(PCI-X 中这也会起到作用,因为 RC 可以向不同区域的内存进行写入,因此即使一个区域正忙,RC 也可以写入另一个不同的内存区域)。同样地,当 RC 接收到的写事务 RO bit=1 时,它可以按照任何地址顺序来写入每一个 Byte。
8.5.2 RO 对 MRd 事务的影响(RO Effects on MRd Transactions)
PCIe 中所有的读事务都采用拆分事务(Split Transaction)的方式来处理。当一个设备发出一个 RO bit=1 的 MRd 请求,Completer 将会通过一系列的一个或多个 Split Completion 事务(拆分完成包)来返回 Requester 设备所请求的数据,且在完成包中使用和当初请求包相同的 RO bit 值。这种情况下 Switch 的工作行为如下:
- 当 Switch 接收到一个 RO bit=1 的 MRd 时,它会将 MRd 请求按照接收时的顺序来进行转发,一定不能让其重排在先前下发的 MWr 事务之前。这保证了所有和读请求同方向传输的写事务都会被推到读请求之前。这是之前的 Producer/Consumer 例子的一部分,软件可能要依赖这个类似刷新的举动来进行正确的操作。Switch 一定不能更改 RO bit 的值。
- 当 Completer 接收到 MRd 请求,它将收集被请求的数据,然后以一个或多个 Completion 完成包的形式进行发送,这些 Completion 都具有跟请求包中相同的 RO 属性。
- Switch 接收到 RO bit=1 的 Completion 完成包时,可以将它们进行重新排序,将这些 Completion 排在先前下发的与 Completion 同方向传输的 MWr 之前。如果写事务被阻塞了(例如被流控阻塞),那么 Completion 就可以被排在写事务之前发送,不用等待写事务阻塞结束。这种情况下的宽松排序(RO)可以改进读操作性能。表 8-2 中总结了 Switch 允许的宽松排序行为。

表 8‑2 宽松排序中可以被重新排序的事务
8.6 弱排序(Weak Ordering)
当严格执行强排序规则时可能会出现暂时性的事务阻塞问题。在不违反 Producer/Consumer 编程模型的前提下可以对强排序模型进行一定的修改,使其可以消除一些阻塞事务的情况,以此来提升链路效率。也就是说,实现弱排序模型(Weakly-Ordered model)是可以缓解强排序模型中阻塞事务的问题的。
8.6.1 事务的排序与流控(Transaction Ordering and Flow Control)
之所以要将给定数量的 VC Buffer 拆分成三个流控子 Buffer(Posted、Non-Posted 和 Cpl),是因为将 TLP 被解析或归入各自的 Buffer 后可以简化对事务排序规则的处理过程。事务排序规则处理逻辑之后就只需要在这三个子 Buffer 之间或是每个子 Buffer 去应用排序规则即可。
因为 TLP 被归入各自类别的三个子 Buffer 来应用事务排序规则,那么就必须要定义链路两端端口之间每种 VC 子 Buffer(P、NP、Cpl)的流控机制。实际上,你可能会回想起来对于每种 VC 子 Buffer 大类(P、NP、Cpl)来说,它们各自的 Header(Hdr)和 Data(D)这两种子 Buffer 之间还拥有一个独立的流控机制。
8.6.2 事务暂停(Transaction Stalls)
强排序规则可能会出现由于单个接收 Buffer 满而阻塞所有事务的情况。例如,Producer/Consumer 模型相关事务的排序要求不能变,但是与模型不相关的事务的排序规则是可以改变的,若都完全使用强排序规则那么就有可能出现阻塞其他不相关事务的情况。为了改善性能,我们可以考虑一种弱排序方案,这是一种对事务排序施加最低要求的方案。
下面的例子中(图 8‑6)展示了在一个 VC 中单向传输的事务相关的发送和接收 Buffer。回忆一下,在同一 VC 中每种事务类型(P、NP、Cpl)都有独立的流控机制。发送 Buffer 内的数字表示这些事务被分配的发送顺序,并且此时 Non-Posted 接收 Buffer 已经满了。
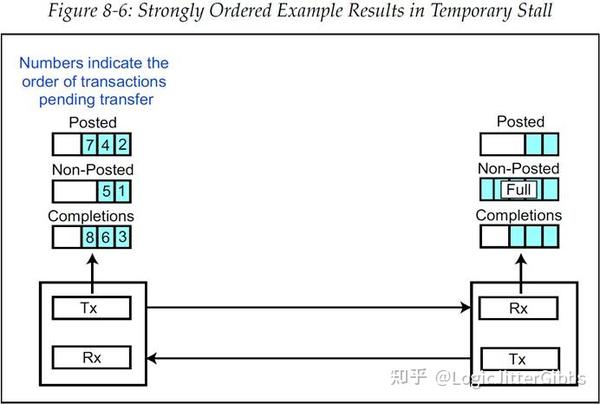
图 8‑6 强排序规则导致的事务临时暂停
考虑下面的流程:
- 事务 1(MRd)是下一个要被发送的事务,但是此时并没有足够的 Non-Posted 流控 Credit,因此它必须要等待。
- 事务 2(Posted MWr)是紧跟事务 1 之后的待发送事务。如果执行的是强排序规则,那么这个 MWr 一定不能重排在事务 1 之前。
- 这种强排序的约束也会应用在后面的所有事务上,所以就会导致他们都暂停了下来,要等待事务 1 传输完成。
8.6.3 VC Buffer 提供了一项好处(VC Buffers Offer an Advantage)
事务的顺序是在 VC Buffer 内进行管理的。这些 Buffer 被按照事务类型 Posted、Non-Posted 和 Completion 进行分类,对于每个类型的 Buffer 来说,它的流控是与其他类型相独立的。这使得弱排序规则更加有用,比如在我们上面的例子中,即使一个 Buffer 满了,但是其他的 Buffer 还有空间,那么就可以在规则内让其他事务先传输。
8.7 基于 ID 的排序(ID Based Ordering,IDO)
另一种优化排序并提升性能的方法与数据流的性质有关。来自不同 Requester 的数据包之间通常并没有依赖关系,毕竟一个设备很难根据传输顺序就知道另一个设备在什么时候完成了某些步骤,因为它们可能有各自不同的路径来去往它们共享的资源。考虑到这一点,PCIe 的 2.1 版本协议规范中引入了一种被称为基于 ID 的排序规则(ID-Based Ordering)来提升性能。
8.7.1 解决方案(The Solution)
如果数据包的来源并没有考虑事务顺序,那么性能就会受到影响,如图 8‑7 所示。在图中,事务 1 从自己的事务源被传输到 Switch 的上行端口,但是在它想继续传输至 RC 时却被阻塞了,这是因为 RC 端口中与之对应的 Buffer 满了(可以通过流控 Buffer 不足来表示这一点)。这里我们使用协议规范中的术语,来自同一个 Requester 的多个数据包称为一个 TLP 流(TLP Stream)。在本例中,事务 1 所示的传输路径可能会要传输 TLP 流中的一系列 TLP。事务 2 也到达了同一个出口端口(Switch 的上行端口),并且它也被阻塞了,因为它需要保持与事务 1 的相对顺序。既然这两个数据包来自不同的事务源(属于不同的 TLP 流),因此这种延迟等待基本上是没必要的,很大概率这二者并没有相互依赖关系,但是在一般的排序规则中并没有进行这样的考虑。为了提高性能,我们需要一种不同的解决方法。
这种情况的解决办法也很简单:如果数据包各自的 Requester ID 不同(对于 Completion 来说是 Completer ID),那么就可以将它们重新排序。这种可选的特性使得软件可以让设备使用 IDO,这样 Switch 端口就可以识别出一些数据包属于不同的 TLP 流。这是通过置位设备控制 2 寄存器(Device Control 2 Register)的使能位来实现的。
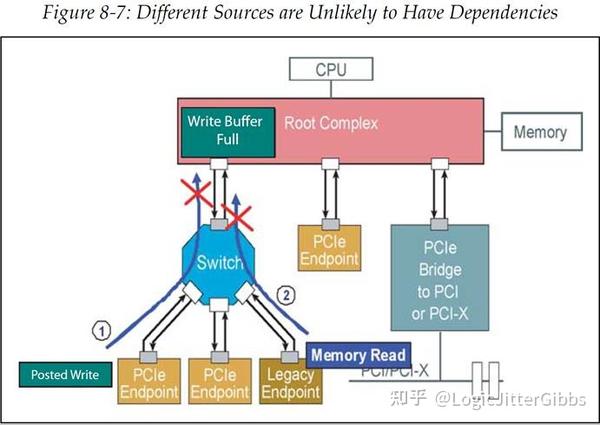
图 8‑7 不同数据源之间一般没有相互依赖关系
8.7.2 何时使用 IDO(When to use IDO)
协议强烈建议在比较安全的时候,同时使用 IDO 和 RO。举例来说,对于一个 EP 设备来说,如果其正在直接和单个设备通信,比如 RC,那么在所有 TLP 上启用 IDO 应该是安全的。 反过来说,如果 EP 设备正在和多个设备通信,那么可能启用 IDO 会不安全。协议给出了有一个不安全使用 IDO 的例子,一个设备正在对内存进行 DMA 写访问,然后对另一个设备进行了点对点访问,设置了其中的某个标志位。在标志位被置起之后,第二个设备也向内存的同一区域发起写访问。正常情况下,这两个设备的写访问应该是强制有序的,但是在启用 IDO 的情况下,它们之间的顺序是不能保证的,因为它们来自不同的设备,有不同的设备 ID。同样地,如果某些包受到了流量控制,那么此时启用 RO 也是不安全的。对于完成包来说,如果启用了 IDO,那么协议建议对所有的完成包都启用 IDO,除非有特殊的理由不能这么做。
8.7.3 IDO 软件控制(Software Control)
软件可以让来自一个给定端口的请求或完成包应用 IDO,这是通过设置 Device Control 2 Register 中相应的位来实现的。跟 RO 的情况一样,设备中并没有能力位(Capability bit)来告诉软件这个设备支持什么,而是只存在使能位,因此软件需要通过其他的一些方法来知道这个设备可以支持 IDO(否则即使置位了使能位,但是设备并不支持 IDO,那么也无法使用 IDO)。这些 bit 使得这些类型的数据包可以使用 IDO,但是软件还需要决定是否每个单独的数据包都要将它的 IDO bit 置位。TLP Header 中的一个新的属性位可以用来指示这个 TLP 是否使用 IDO,如图 8‑8 所示。这带来了另一个相关的知识点:Completion 一般会直接继承对应请求包中所有的属性位,但是对于 IDO 来说可能就不是这样了,因为 Completer 可以独立地启用 IDO。换句话说,即使请求包中没有使用 IDO,对应的 Completion 也是可以使用 IDO 的。

图 8‑8 64bit Header 中的 IDO 属性位
8.8 死锁的避免(Deadlock Avoidance)
因为 PCI 总线采用延迟事务,也因为 PCIe 的 MRd 请求可能会因为缺少流控 Credit 而被阻塞,在这些原因下产生出了一系列的会出现死锁的场景。这些避免死锁的规则被包含在了 PCIe 的排序规则中,以此来确保不管何种拓扑结构都不会发生死锁。遵守排序规则可以防止由于出现了意料之外的拓扑结构,而产生边界条件时出现的问题(例如,两个 PCIe-to-PCI Bridge 跨 PCIe 网络拓扑相连)。参考 MindShare 的名为《PCI System Architecture,Fourth Edition》的书籍,里面有对各种场景的详细解释,它们是 PCIe 中与避免死锁相关的排序规则的基础。表 8‑1 中列出了用来避免死锁的排序规则,它们为 A3、A4、D3、D4 和 A5b。注意,表中这五种为“Yes”的条目都是用来避免死锁的。如果表中列 3 或 4 相关的 Non-Posted Buffer 由于缺少流控 Credit 而出现了阻塞现象,那么行 A 相关联的 Posted 请求或是行 D 相关联的 Completion 必须要移动到 Non-Posted 请求之前,不难发现它们在表中的项都是“Yes”。还需要注意,A5b 中的“Yes”项仅引用于 PCIe-to-PCI/PCI-X Bridge 中。
本质上来说,这些用来避免死锁的规则可以被总结为“必须要允许后到来的 MWr 请求或是 Completion,在顺序上超过先前到来的但被阻塞的 Non-Posted 请求,否则就有可能会发生死锁。”
原文: Mindshare
译者: Michael ZZY
校对: LJGibbs
欢迎参与 《Mindshare PCI Express Technology 3.0 一书的中文翻译计划》
Gitee:
https://gitee.com/ljgibbs/chinese-translation-of-pci-express-technology
Github:
https://github.com/ljgibbslf/Chinese-Translation-of-PCI-Express-Technology-
原文:知乎
作者:LogicJitterGibbs
相关文章推荐
- 【译文】 DFT, Scan and ATPG
- 【译文】 Example showing JTAG Operation // JTAG 运行示例
- JTAG Architecture //JTAG 架构
- FPGA单独下载<固化文件>的解决方案
- Xilinx DDS Compiler IP 使用教程
更多FPGA干货请关注FPGA的逻辑技术专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

