
佐思汽研发布了《 2025 年汽车存储芯片产业及对大模型影响研究报告** 》。
从 2D+CNN 小模型到 BEV+Transformer 大模型,模型参数量暴增,存储成为性能瓶颈
全球汽车存储芯片市场规模将从 2023 年的 43 亿美元左右,到 2030 年增长至 170 亿美元以上,复合增长率高达 22%,汽车存储芯片在汽车半导体中的价值占比,2023 年在 8.2%,预计到 2030 年将上升至 17.4%,存储芯片成本将大幅上升。
2023-2030 年全球汽车芯片市场规模预测

来源:佐思汽研《2025 年汽车存储芯片产业及对大模型影响研究报告》
汽车存储芯片行业发展的主要驱动力在于车载 LLM 大模型快速兴起,从过去的 2D+CNN 小模型到 BEV+Transformer 大模型,模型参数量大幅提升,算力需求骤增。CNN 模型参数通常不到 1000 万,大模型即 LLM 的参数一般在 70 亿至 2000 亿之间,经过蒸馏后的车端模型参数也已高达几十亿级别。
从计算角度看,BEV+Transformer 大模型以 LLaMA 为代表的解码器架构中,Softmax 算子成为核心,其并行化能力低于传统卷积(Convolution)算子,导致存储成为瓶颈,特别是存储密集型模型如 GPT,对存储带宽要求高,市面上常见的自动驾驶 SoC 芯片常面临“存储墙”问题。
端到端实际上是内嵌了一个小型 LLM,随着喂养数据的增加,这个大模型的参数会越来越大,最初阶段的模型大小大概是 100 亿参数,经过不断迭代最终会达到 1000 亿以上。
2025 年 4 月 15 日,小鹏汽车在 AI 分享会上首次对外披露正在研发 720 亿参数的超大规模自动驾驶大模型,即“小鹏世界基座模型”。小鹏的实验结果表明,在 10 亿、30 亿、70 亿、720 亿参数的模型上都看到了明显的规模法则(Scaling Law)效应:参数规模越大,模型的能力越强。同样的模型大小,训练数据量越大,模型的能力也会越强。
多模态模型训练的主要瓶颈不仅是 GPU,也需要解决数据访问的效率问题。小鹏汽车自主开发了底层的数据基础设施(Data Infra),使数据上传规模提升 22 倍、训练中的数据带宽提升 15 倍;通过联合优化 GPU / CPU 以及网络 I/O,最终使模型训练速度提升了 5 倍。目前,小鹏汽车用于训练基座模型的视频数据量高达 2000 万 clips,这一数字今年将增加到 2 亿 clips。

来源:小鹏汽车
未来,小鹏将 “小鹏世界基座模型” 通过云端蒸馏小模型的方式将基模部署到车端,车端大模型参数规模只能越来越大,对计算芯片和存储都带来巨大挑战。基于此,小鹏汽车自研了图灵 AI 芯片,芯片比通用车规高算力芯片利用率提升 20%,最高能处理 30B(300 亿)参数的大模型,相较之下,当前理想汽车的 VLM(视觉-语言模型)参数量约为 22 亿。
模型参数量越大,也往往伴随着模型推理的较高延迟问题,如何解决时延问题至关重要,预计图灵 AI 芯片可能通过多通道设计或先进封装技术实现存储带宽的显著提升,以支持 30B 参数大模型的本地运行。

来源:小鹏汽车
存储带宽决定了推理计算速度的上限,LPDDR5X 将被普遍采用,但仍显不足,GDDR7、HBM 或将提上规划日程
存储带宽决定了推理计算速度的上限。假设一个大模型参数为 70 亿,按照车载的 INT8 精度,它所占的存储是 7GB,特斯拉第一代 FSD 芯片的存储带宽是 63.5GB/s,即每 110 毫秒生成一个 token,帧率不到 10Hz,自动驾驶领域一般图像帧率是 30Hz。英伟达的 Orin 存储带宽是 204.5GB/s,即每 34 毫秒生成一个 token(7GB 除以 204.5GB/s=0.0343s,约 34ms),勉强可以达到 30Hz(帧率=1 除以 0.0343s=29Hz),注意这只是计算的数据搬运所需的时间,数据计算的时间都完全忽略了,实际速度要远低于这个数据。

- DRAM 存储芯片选择路径(1):LPDDR5X 将被普遍采用,LPDDR6 标准仍在制定中
除了特斯拉,目前所有的车载芯片最高只对应 LPDDR5,下一步业界将主推 LPDDR5X,譬如美光已推出车规级 LPDDR5X+DLEP DRAM 方案,已通过 ISO26262 ASIL-D 认证,可以满足关键的汽车 FuSa 要求。
英伟达 Thor-X 已支持车规级 LPDDR5X,内存带宽增至 273GB/s,支持 LPDDR5X 标准,支持 PCIe 5.0 接口。Thor-X-Super 内存带宽则达到了惊人的 546GB/s,采用了 512 位宽的 LPDDR5X 内存,确保了极高的数据吞吐量,实际 Super 和苹果系列芯片一样,就是将两片 X 放进一个封装里,但短期内预计不会量产投放。
Thor 也有多个版本,目前已知的有 5 个:①Thor-Super,2000T 算力;②Thor-X,1000T 算力;③Thor-S,700T 算力;④Thor-U,500T 算力;⑤Thor-Z,300T 算力。联想全球第一个 Thor 中央计算单元计划采用双 Thor-X。
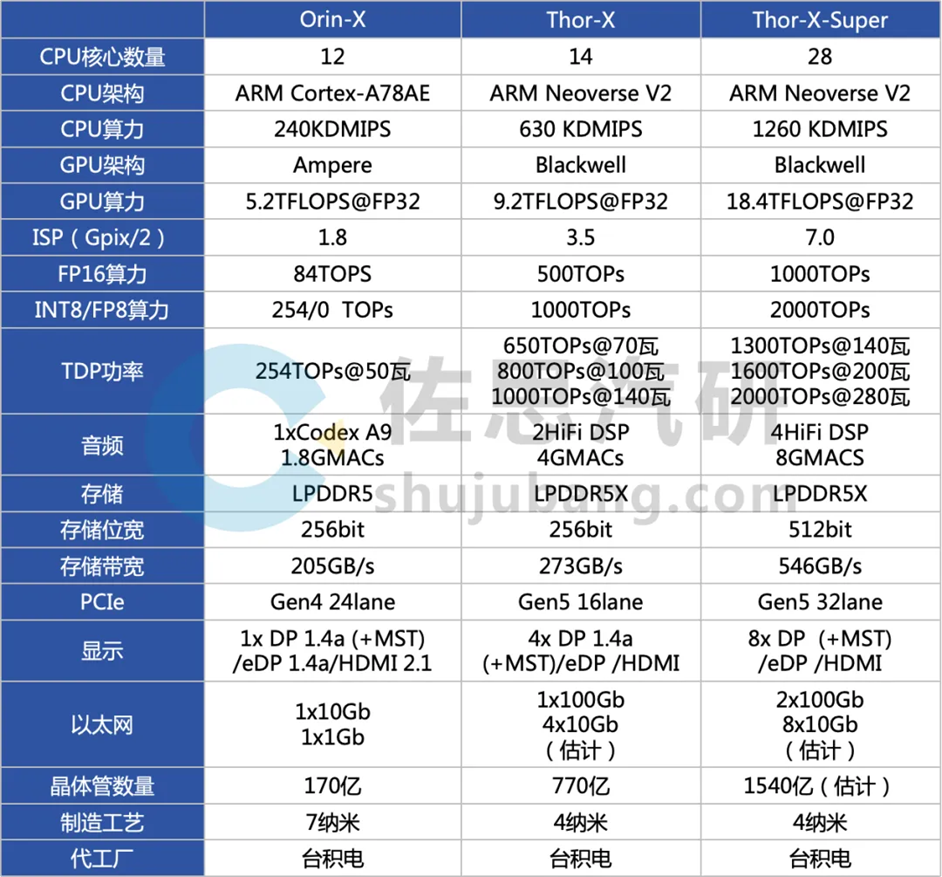
来源:佐思汽研《2025 年汽车存储芯片产业及对大模型影响研究报告》
美光 9600MTPS 的 LPDDR5X 已经有样片,主要面向移动端,但还没车规级产品。三星的 LPDDR5X 新品 K3KL9L90DM-MHCU,可用于 PC、服务器、汽车以及新兴的端侧 AI 应用,比前代快 1.25 倍、功耗效率提升 25%,最高工作温度 105℃,2025 年初量产,单片 8GB,x32 总线,使用 8 片,共 64GB。
随着 LPDDR5X 逐步迈入 9600Mbps 甚至 10Gbps 时代,JEDEC 已启动下一代 LPDDR6 的标准制定。面向 6G 通信、L4 自动驾驶、沉浸式 AR/VR 场景。LPDDR6 作为下一代内存技术,预计速率将突破 10.7Gbps,甚至最高可能达到 14.4Gbps,带宽和能效均有提升,比现在使用的 LPDDR5X 提升了 50%。然而,大规模量产 LPDDR6 内存可能还需要等到 2026 年,高通的下一代旗舰芯片骁龙 8 Elite Gen 2(代号 SM8850)将支持 LPDDR6。车规级 LPDDR6 则可能更为久远。
域控计算平台 LPDDR 演进(标准传输速率)

来源:佐思汽研《2025 年汽车存储芯片产业及对大模型影响研究报告》
- DRAM 存储芯片选择路径(2):GDDR6 虽已上车,但面临成本与能耗的问题,下一代 GDDR7+LPDDR5X 的混合存储架构或有可为
除了 LPDDR5X,另一条路径则是选择 GDDR6 或 GDDR7,特斯拉第二代 FSD 芯片就支持第一代 GDDR6,HW4.0 上的 GDDR6 容量为 32GB,型号为 MT61M512M32KPA-14,频率 1750MHz(LPDDR5 最低也是 3200MHz 之上),由于是第一代 GDDR6,速度较低。即使用了 GDDR6,要流畅运行百亿级别的大模型,还是无法实现,不过已经是目前最好的了。
特斯拉的第三代 FSD 芯片应该正在开发中,可能 2025 年底可以完成开发,至少支持 GDDR6X。
而再下一代的 GDDR7 正式标准在 2024 年 3 月公布,三星在 2023 年 7 月就发布了全球首款 GDDR7,目前 SK 海力士和美光也都有 GDRR7 产品推出。GDDR 需要特殊的物理层和控制器,芯片必须内置 GDDR 的物理层和控制器才能用上 GDDR,Rambus 和新思科技都有相关 IP 出售。

来源:SK 海力士
未来自动驾驶芯片可能采用混合存储架构,例如用 GDDR7 处理高负载 AI 任务,而 LPDDR5X 负责低功耗常规运算,以平衡性能与成本。
- DRAM 存储芯片选择路径(3):HBM2E 已部署到 L4 级 Robotaxi,但距离量产乘用车仍有较远距离,存储芯片厂商正推动 HBM 从数据中心向端侧技术迁移
HBM 主要用于服务器领域,将 SDRAM 用 TSV 工艺堆叠起来,增加的成本不仅仅是内存本身,还有台积电 CoWoS 工艺的成本,CoWoS 目前产能紧张,价格高昂。HBM 存储价格远远高于量产乘用车常用的 LPDDR5X、LPDDR5、LPDDR4X 等,不具备经济性。
SK 海力士的 HBM2E 正用于 Waymo 的 L4 级 Robotaxi,且是独家供应商,容量高达 8GB,传输速度达到 3.2Gbps,实现了惊人的 410GB/s 带宽,为行业树立了新标杆。
SK 海力士是目前市场上唯一一家能提供符合严苛 AEC-Q 车规标准的 HBM 芯片制造商。SK 海力士正积极与 NVIDIA、Tesla 等自动驾驶领域解决方案巨头的合作,将 HBM 的应用从 AI 数据中心拓展到智能汽车市场。
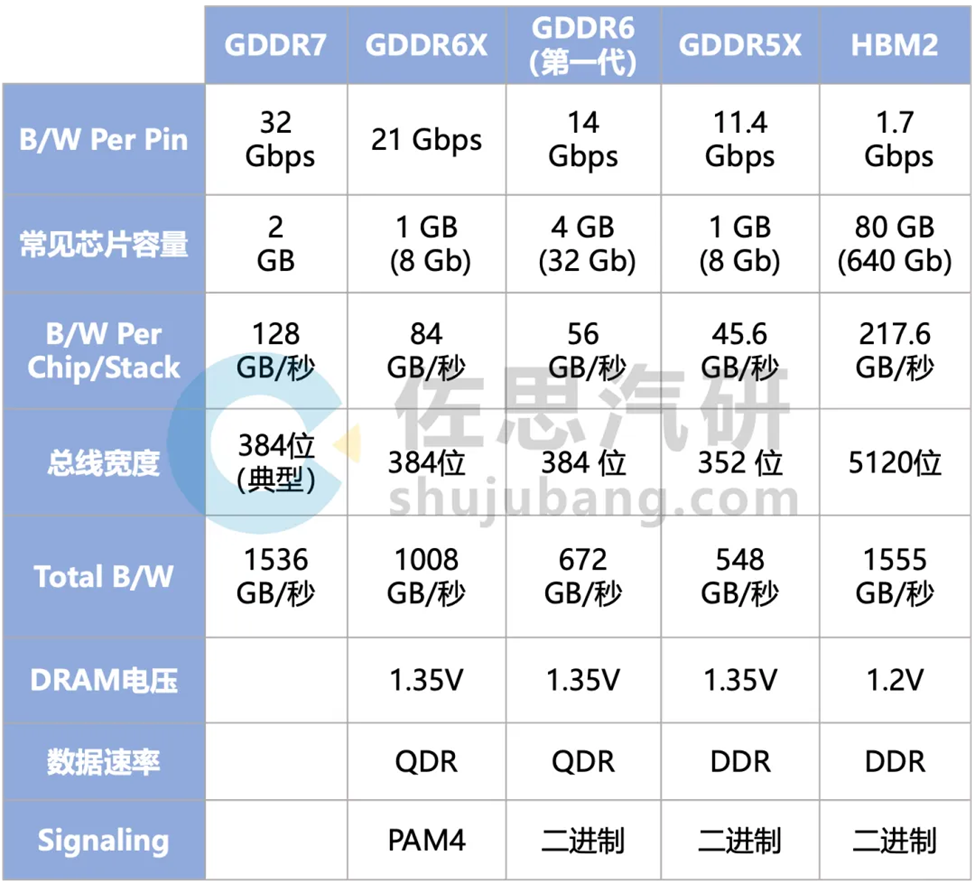
来源:佐思汽研《2025 年汽车存储芯片产业及对大模型影响研究报告》
SK 海力士和三星都正在将 HBM 从数据中心向手机、汽车等端侧应用迁移,HBM 在移动设备领域的渗透将围绕端侧 AI 性能提升和低功耗设计展开,技术创新与产业链协同是关键驱动力,成本与良率仍是短期主要挑战,主要涉及到 HBM 生产工艺改良。
- 核心差异:传统数据中心 HBM 是为高性能计算设计的“大带宽、高功耗”方案;而端侧 HBM 是为移动端定制的“中带宽、低功耗”解决方案。
- 技术路径:传统数据中心 HBM 依赖 TSV 和中介层;而端侧 HBM 则通过封装创新(如垂直引线键合)和低功耗 DRAM 技术实现性能突破。
以三星为例,采用类似技术的产品 LPW DRAM(LP Wide I/O DRAM),其具备低延迟和高达 128GB/s 的带宽性能,同时能耗仅为 1.2pJ/b,计划于 2025-2026 年实现商业化量产。
LPW DRAM 通过堆叠 LPDDR DRAM,大幅提升了 I/O 接口的数量,以达到提高性能和减少能耗的双重目标。其带宽可达 200GB/s 以上,较现有的 LPDDR5X 提升了 166%;同时其功耗降至 1.9pJ/bit,比 LPDDR5X 低 54%。

来源:三星
UFS3.1 已大规模上车,将逐渐迭代至 UFS4.0、UFS5.0,同时 PCIe SSD 将成为 L3/L4 高级别自动驾驶汽车的首选
目前,高阶自动驾驶汽车已将 UFS 3.1 存储作为主流选择,随着车载传感器、算力的不断提升,更高规格的数据传输方案势在必行,UFS 4.0 产品将成为未来主流的选择之一。UFS 3.1 版本最高 2.9GB/s,与 SSD 有几十倍的差距,下一代 4.0 版本 4.2GB/s,UFS 4.0 相较于 UFS 3.1,在速度上有所提升,功耗降低 30%;预计到 2027 年会有 5.0 版本,估计达到 10GB/s,跟 SSD 还是差距明显,但好在成本可控,供应链稳定。
考虑到大模型无论在座舱还是智能驾驶都有强烈需求,且为了留出足够的性能余量,更应该采用 SSD,目前主流的 UFS 不够快,eMMC 就更慢了。车规级 SSD 采用的是 PCIe 标准,PCIe 的弹性空间极大,潜力巨大。JESD312 确定的是 PCIe 4.0 标准,实际其包含多个速率,4 通道是最低的 PCIe 4.0 标准,16 通道双工可以到 64GB/s,而 PCIe 5.0 标准已于 2019 年发布了,PCIe5.0 将信号速率翻倍到了 32GT/s,x16 双工带宽更是接近 128GB/s。
目前,美光和三星都有车规级 SSD,三星是 AM9C1 系列,128GB 到 1TB 都有。美光则推出了 4150AT 系列,4150AT 系列有 220GB、440GB、900GB 和 1800GB 四种,其中 220GB 级别用于单独的座舱或智能驾驶,舱驾一体至少要用 440GB。
多端口 BGA SSD 可以作为汽车中央存储计算单元,通过各端口与座舱、ADAS、网关等 SoC 连接,高效处理并存储不同数据到所需区域。其独立性优势确保非核心 SoC 无法未授权访问核心数据,避免影响、识别、销毁核心 SoC 的数据,这将最大的保证对数据传输的阻并发性和数据独立性,并降低各个 SoC 对于车用存储的硬件成本。
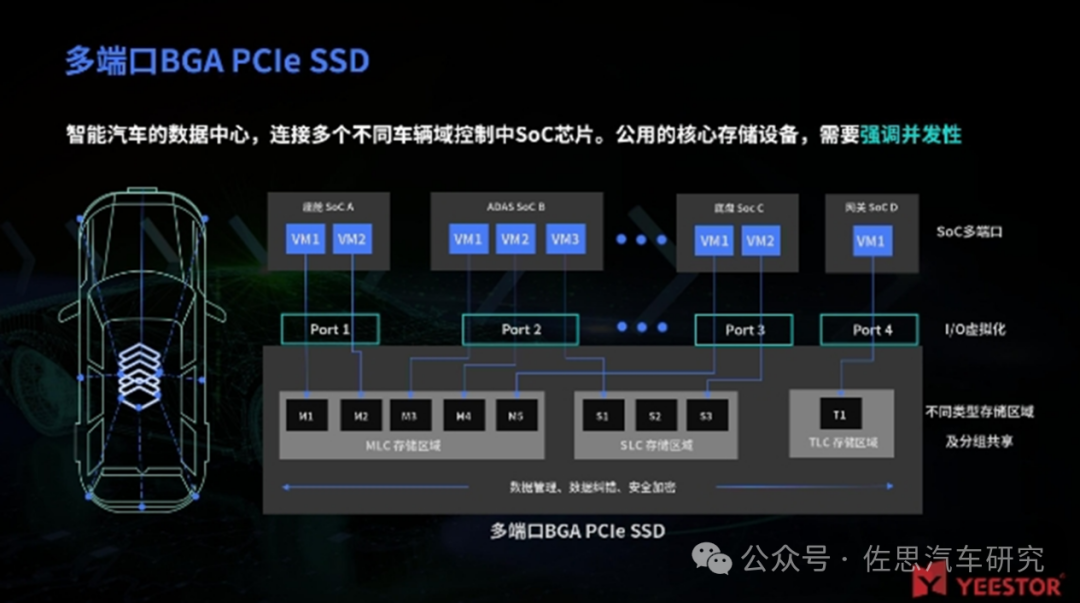
来源:得一微
对于再往后的 L3/L4 级高级别自动驾驶汽车,PCIe 5.0 x4 + NVMe 2.0 将是高性能存储的首选:
- 超高速传输:读取速度高达 14.5GB/s,写入速度达 13.6GB/s,是 UFS 4.0 的 3 倍
- 低延迟 & 高并发:支持更高队列深度(QD32+),并行处理多个数据流
- AI 计算优化:与车载 SoC 结合,可加速 AI 推理计算,满足全自动驾驶需求
在自动驾驶应用中,PCIe NVMe SSD 可用于缓存 AI 计算数据,减少内存访问压力,提高实时处理能力。例如,Tesla FSD 系统就采用高速 NVMe 方案存储自动驾驶训练数据,以提高感知和决策效率。
目前,新思科技(Synopsys)已推出了全球首款汽车级 PCIe 5.0 IP 解决方案,囊括了 PCIe 控制器、安全模块、物理层设备(PHY)以及验证 IP,并遵循 ISO 26262 和 ISO/SAE 21434 标准。这意味着 PCIe 5.0 将很快进入车规应用。
END
作者:佐思汽研
来源:佐思汽车研究
推荐阅读:
- 具身智能与人形机器人发展的六大趋势
- Zone 和 Domain,差别在哪里?
- 功能安全研究:“智驾平权”下,SOTIF 设计至关重要
- AI/AR 眼镜研究:2030 年销量预计 9000 万台,将大幅增强座舱功能
更多汽车电子干货请关注汽车电子与软件专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

