

导读
近期,零样本异常检测(ZSAD)已成为一种识别未见类别缺陷的关键范式,无需在训练阶段使用目标样本。然而,现有的 ZSAD 方法由于表示不足,在处理小型和复杂缺陷的边界上存在困难。其中大多数方法使用单一手动设计的 Prompt ,无法适用于多样化的目标和异常。在本文中,作者提出了 MFP-CLIP,这是一种基于 Prompt 的 CLIP 框架,旨在探索多形式 Prompt 在零样本工业异常检测中的有效性。作者采用图像到文本 Prompt (I2TP)机制以更好地表示图像中的目标。MFP-CLIP 通过自 Prompt(SP)和多块特征聚合(MPFA)模块增强了多尺度复杂异常的感知能力。为了精确定位缺陷,作者引入了 Mask Prompt (MP)模块,引导模型关注潜在的异常区域。在两个广泛使用的工业异常检测基准 MVTecAD 和 VisA 上进行了大量实验,证明了 MFP-CLIP 在 ZSAD 中的优越性。
1. 引言
异常检测(AD)在众多领域具有巨大潜力,包括工业产品质量控制、医疗诊断等。工业异常检测(IAD)专注于识别工业图像中的异常模式。由于异常样本稀缺和数据标注成本高昂,出现了许多无监督异常检测方法[1, 6-8, 11, 21-24, 26, 28-32, 34, 35]。这些方法通过测量与正常数据分布的偏差来检测和定位缺陷。然而,工业图像在物体类别和异常类型方面的巨大变异性阻碍了无监督方法的进一步发展。
因此,零样本范式持续发展。其目标是检测在训练阶段未参与的新类别中的异常。最近,许多零样本异常检测(ZSAD)方法[3-5, 10, 37-39]依赖于预训练的视觉语言模型(VLMs)以利用其强大的泛化能力。由于 CLIP[19]在下游任务中的出色迁移性、出色的图像-文本对齐和表示能力,许多基于 CLIP 的 ZSAD 方法[3, 5, 20, 38, 39]应运而生。这些方法计算 CLIP 中视觉和文本嵌入的相似性作为异常图,如图 1(a)所示。文本嵌入仅通过文本模板提取。
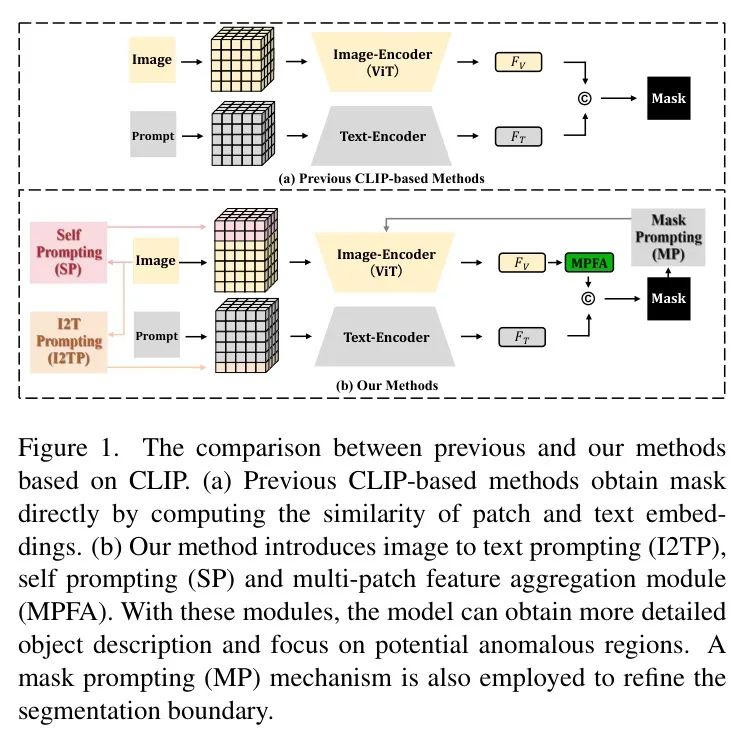
WinCLIP [10] 使用了未经额外微调或训练的预训练视觉语言模型(VLMs)和手动设计的 Prompt 。然而,预训练的 CLIP 是在偏离工业图像数据集的自然图像数据集上训练的,这导致 WinCLIP 在工业图像分析(IAD)中存在一定的局限性。为了克服这些局限性,一些方法[3, 38, 39]使用了辅助工业数据进行微调。特别是,AnomalyCLIP [39] 使用额外的数据将模型从自然图像域迁移到工业图像域。AdaCLIP [3] 引入了一个混合语义融合模块来捕获语义丰富的图像特征,从而提高了异常检测的性能。尽管做出了这些努力,但准确定位小型和逻辑缺陷仍然具有挑战性。他们手动设计文本 Prompt 来描述目标及其状态(正常/异常),难以泛化所有图像,导致性能不佳。此外,涉及视觉 Prompt 以细化 Patch 嵌入并强调特定区域的方法还相对较少。
为解决上述问题,作者提出了一种名为 MFP-CLIP 的新框架,该框架基于 CLIP 构建。如图 1(b)所示,MFP-CLIP 采用了一个图像文本 Prompt (I2TP)模块,用于提供除文本 Prompt 模板之外的具体物体描述。为了增强图像表示和潜在异常区域的感知,作者引入了自 Prompt (SP)和 Mask Prompt (MP)机制。SP 使用 CNN 的图像特征作为自身的视觉 Prompt ,以获取特定图像的更详细的局部嵌入。然后,作者将 Prompt 与视觉 Transformer(ViT)的 Patch 嵌入相结合,以获得深度表示,结合局部和全局上下文感知。MP 机制作为一个边界细化器,利用分割 Mask 作为视觉 Prompt ,引导模型更精确地关注潜在异常区域。此外,为了增强检测小型和复杂缺陷的能力,作者引入了一个多 Patch 特征聚合(MPFA)模块,通过邻域 Patch 嵌入细化特征表示,以增强空间连续性和上下文一致性。SP 和 MPFA 使模型适用于多尺度异常,特别是小型和复杂异常。
主要贡献总结如下:
- 作者提出了一种基于 CLIP 的新型框架 MFP-CLIP,用于增强对未见目标的检测。通过 I2TP 将视觉和文本嵌入相结合,以获得更详细的物体描述。作者采用自 Prompt (SP)和 Mask Prompt (MP)来调整 Patch 嵌入,并专注于潜在的异常区域。
- 提出了一种多块特征聚合(MPFA)策略,以增强邻域块之间的特征感知。
- 在两个主要的工业数据集上进行了广泛的实验,分别是 MVTehcAD [2] 和 VisA [41]。MFPCLIP 在零样本异常检测方面展现了其优越性。
2. 相关工作
2.1 异常检测
鉴于工业领域异常数据稀缺且成本高昂,收集大量缺陷图像进行训练较为困难。因此,目前主要有两种主要范式,它们大多遵循“一个模型对应一个类别”的方式。
无监督异常检测方法仅依赖于目标类别中的正常样本,在训练时对这些样本进行建模以模拟正常图像的分布,并通过获取具有正常分布的测试样本之间的偏差来定位异常。基于嵌入的方法[1, 6-8, 13, 21-27, 32, 35]通常使用预训练模型提取正常样本的特征,然后对正常特征分布进行建模。这些方法在目标类别上实现了显著的性能,但在测试未见过的目标时面临严重的性能下降。类似内存库的 Patch-Core[6, 7, 22]方法需要额外的空间来存储正常特征,限制了推理速度。基于重建的方法[11, 14, 28-31, 33, 34, 36]假设仅使用正常样本训练的模型无法准确重建异常样本。但这些方法通常对缺陷区域具有较强的泛化能力,导致重建结果几乎等于输入图像。
半监督异常检测方法[9]利用正常样本和若干异常图像来实现比无监督异常检测方法更好的性能。尽管它们通过利用缺陷图像来提升性能,但它们在处理未见过的类别时仍然面临挑战,这与无监督 AD 类似。
2.2. Prompt 学习
作为自然语言处理领域的一项新兴技术, Prompt 学习近年来受到了广泛关注。其核心思想是设计合适的 Prompt 来引导预训练模型适应特定任务,无需大量特定任务的标注数据。随着研究的深入, Prompt 学习逐渐从单一文本任务扩展到多模态领域。例如,CoOp [37] 将可学习的 Prompt Token 引入文本分支,首次在 CLIP 中引入 Prompt 学习。随后,DenseCLIP [20] 和 CoCoOp [38] 使用视觉上下文 Prompt 来适应目标领域。在本工作中,作者提出了自 Prompt 机制,同时考虑全局和局部上下文理解,更好地检测小而复杂的异常。
2.3 零样本异常检测
近期,大型视觉语言预训练模型如 MiniGPT-4 [16]、LLAVA [12]、Otter [40]和 CLIP [19]展现了有前景的零样本能力。特别是 CLIP 引起了广泛关注,其目标是使视觉和语言模态的特征空间对齐。零样本异常检测方法 [3-5, 10, 20, 37-39]通常在训练过程中利用少量已见目标和异常来识别新类别,依赖于视觉语言模型(VLM)的出色泛化能力。鉴于预训练的 VLM CLIP [19]强大的图像文本对齐和泛化能力,许多现成的零样本异常检测(ZSAD)方法选择 CLIP 作为 Baseline 。特别是 WinCLIP [10]手动设计正常/异常文本 Prompt ,然后计算图像特征嵌入和文本特征嵌入之间的余弦相似度,随后通过插值模块获得异常图。与无训练方法相比,一些 [4, 5, 39] 使用标注的辅助数据训练一个线性 Adapter ,缩小自然和工业领域之间的差距。然而,考虑到手工 Prompt 的成本高昂和效率低下,AnomalyCLIP [39]引入了两个用于正常/异常状态的统一可学习文本 Prompt ,以减少劳动和时间消耗,从而提高了 ZSAD 性能。在本工作中,作者探索了多形式 Prompt 在利用 CLIP 进行 ZSAD 中的有效性。
3. 方法
3.1 问题定义

3.2 概述
作者采用 CLIP 作为 MFP-CLIPMFPCLIP 的主干。MFP-CLIP 概述如图 2 所示。CLIP 用于提取图像和文本特征,并将它们映射到一个共享的嵌入空间中。为了充分利用 CLIP 的图像-文本对齐能力,作者通过计算视觉嵌入和文本嵌入之间的余弦相似度来检测和定位异常,遵循先前工作的方法[5, 10]。
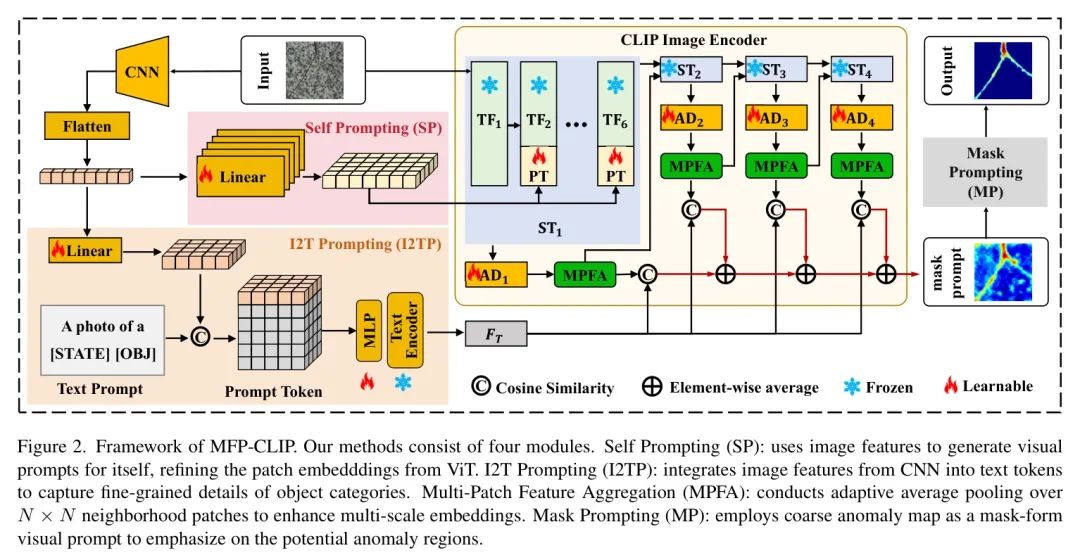
在图像分支中,将一张图像输入到 CLIP 图像编码器中,获得 Patch 嵌入。自 Prompt (SP)模块为自己生成基于 CNN 的局部特征,以细化 Patch 嵌入。经过细化的特征将随后进行线性投影和多 Patch 特征聚合(MPFA),分别调整特征维度和聚合多尺度特征。在文本分支中,作者采用图像到文本 Prompt (I2TP)机制,通过整合视觉特征来增强文本 Prompt ,从而更好地表示物体。然后,作者计算聚合的 Patch 嵌入与更详细的文本嵌入之间的余弦相似度,作为粗略异常图。最后,粗略分割结果作为 Mask 形式的 Prompt ,强调潜在的异常区域,细化边界。通过整合这些模块,MFP-CLIP 有效地增强了 CLIP 检测和定位未见类别异常的能力,提高了精度和鲁棒性。
3.3 图像到文本 Prompt (I2TP)

3.4 自 Prompt (SP)
受文本 Prompt 的启发,作者假设视觉 Prompt 将有助于特殊图像的视觉表示和理解。作者采用了一种自 Prompt 机制,其中模型使用图像特征为自己生成视觉 Prompt 。由于选择了 ViT 作为图像编码器,作者利用 CNN 提取的特征作为视觉 Prompt ,以同时受益于 ViT 的全局推理和 CN
Pu,以对齐不同架构的特征维度。前馈过程是:

其中,TFi(.)和concat(.,.)分别表示自注意力机制和沿第一维度的拼接。值得注意的是,SP 不仅整合了 CNN 强大的局部特征提取和 ViT 强大的全局上下文建模能力,而且通过在辅助数据上的训练,将 CLIP 图像编码器从自然图像领域迁移到专业领域。这种跨框架对齐确保了鲁棒的特征表示,并增强了模型检测特定领域异常的能力。
3.5 多块特征聚合(MPFA)

表示第 i 个线性投影层。
ViT 将图像分割成多个图像块,并使用自注意力机制对它们进行编码。为确保图像块边界处的表示更加平滑,并整合周围图像块之间的上下文,作者设计了一个多图像块特征聚合(MPFA)模块。MPFA 通过在邻域图像块上应用自适应平均池化(AAP)来增强局部上下文感知。为了使物体和缺陷的轮廓更加清晰,作者对每个图像块内的 N×N 邻域进行特征聚合,其中 N 控制特征聚合的尺度,默认设置为 3。

如图 3 所示,作者对比了在自适应平均池化处理 N×N 邻域块前后,块嵌入的注意力图。结果显示,经过 MPFA 处理后,特征图中的块边界变得更加清晰和突出,使模型能够关注更大、更复杂的异常。这种增强显著提高了模型检测复杂物体和缺陷的能力。

3.6 面具 Prompt (MP)

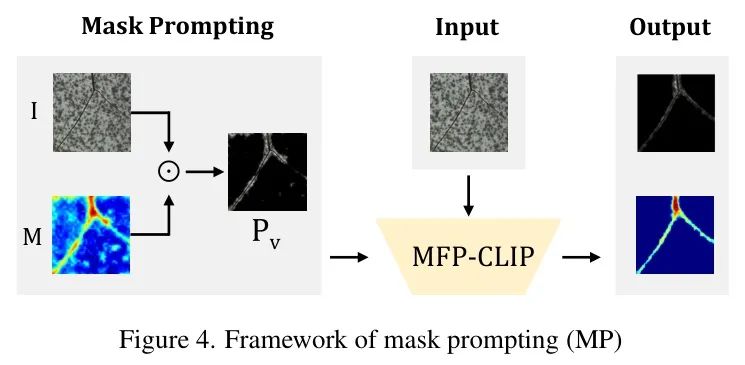

为了优化异常图 M,作者采用 Focal Loss[15]和 Dice 损失[18],这些方法能有效处理类别不平衡问题并提高分割精度。同时,对于异常分数 S,作者使用二元交叉熵(BCE)损失[17]进行训练。
4. 实验
4.1 实验设置
数据集。为了验证 MFP-CLIPMFP-CLIP,作者在两个广泛使用的工业异常检测数据集上进行了实验,即 MVTechAD [2] 和 VisA [41]。MVTec AD 是一个用于评估异常检测方法的基准数据集,重点关注工业检测。它包含超过 5000 张图像,分辨率为 700×700 至 1024×1024。这些图像分为十五个不同的目标(10 个)和纹理(5 个)类别。每个类别都包含一组无缺陷的训练图像和包含各种缺陷以及无缺陷图像的测试集。VisA 数据集包含 12 个子集,对应 12 个不同的目标,包含 10,821 张图像,其中 9,621 张为正常样本,1,200 张为异常样本。其中的图像分辨率为 1000×1000 至 1500×1500。MVTechAD 和 VisA 都包含原始图像和像素级标注。
评估指标。与大多数 ZSAD 方法类似,作者选择图像级和像素级受试者工作特征曲线下面积(I-AUC,P-AUC)来比较与其他 ZAsD 方法在异常检测和定位方面的性能。
实现细节。作者的实验选择 OpenAI 预训练的 CLIP 模型,以 ViT-L-14@336作为默认 Backbone 网络。图像大小在训练和测试时均调整为 518×518。具体来说,作者将图像编码器分为 4 个阶段,从 24 个 Transformer 层中提取第 6、12、18、24 层的图像块嵌入。由于测试中存在未见过的物体,作者选择 MVTechAD、VisA 中的一个作为辅助训练数据集,另一个作为测试数据集。CNN 特征 Adapter 的数量 K 设置为五,这意味着视觉 Prompt 的大小为 5×D。聚合尺度 N 也默认设置为五。模型训练 100 个 epoch,批大小为 1。作者使用 Adam 优化器,初始学习率(lr)为 0.001,lr 衰减因子为 1/(epoch+1)。所有实验均在单个 NVIDIA GeForce RTX 3090 24GB GPU 上运行。
比较方法。为了更好地评估 MFP-CLIP,作者将提出的 MFP-CLIP 与两种方法进行比较:无需训练和带辅助数据训练的方法。对于无需训练的方法,作者选择 WinCLIP [10]进行比较,这是第一个也是代表性的基于 CLIP 的方法,且无需辅助数据进行训练。对于第二种方法,作者选择 APRIL-GAN [4]、AdaCLIP [3]和 AnomalyCLIP [39]进行比较,这些方法在辅助数据上训练,并在未见过的目标上进行测试,正如作者所做的那样。
4.2 与现有方法的比较
表 1 报告了 MVTechAD 和 VisA 上的定量结果。加粗和下划线数值分别表示最佳和次佳结果。可以观察到,作者提出的 MFP-CLIP 在指标 AUC 上优于所有比较方法。使用可学习文本 Prompt 的 AnomalyCLIP 和采用混合语义融合的 AdaCLIP 表现出次优性能。在 MVTechAD 上,MFP-CLIP 比 AnomalyCLIP 和 AdaCLIP 分别高出 0.7%和 3.0%的 I-AUC。对于异常定位,MFP-CLIP 实现了 92.1%的 P-AUC,比次佳方法高 1.0%。作者还在具有挑战性的 VisA 数据集上进行了实验。如表 1 所示,作者的 MFPCLIP 在异常检测和定位方面均取得了最佳性能,分别达到 87.9%的 I-AUC 和 96.0%的 PAUC,分别比次佳结果高出 1.0%的 I-AUC 和 0.5%的 P-AUC。定量比较表明,MFP-CLIP 优于其他 ZSAD 方法。MVTechAD 和 VisA 上所有类别的详细定量结果将在补充材料中报告。
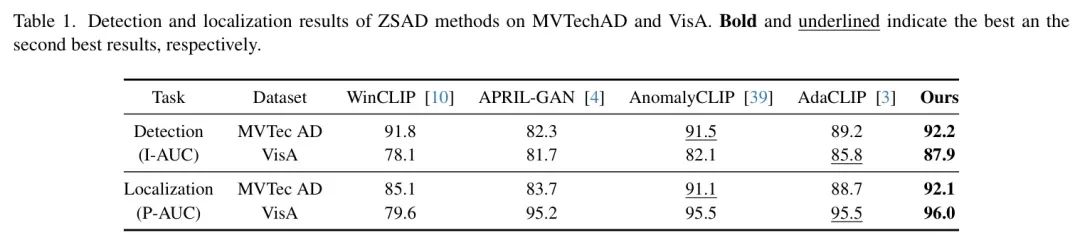
图 5(a)和图 5(b)分别展示了 MVTechAD 和 VisA 上的定性结果。存在许多小缺陷,如拉链的断裂牙齿,以及复杂的缺陷,如瓶子的断裂。它们的真实边界非常精细。图 5(a)展示了这些方法在 MVTechAD 上的定性结果,其中 MFP-CLIP 可以更准确地定位小和复杂的异常轮廓。相比之下,Tile、地毯和木材等类别的像素级结果展示了 MFP-CLIP 在检测和定位缺陷方面的优越性。作者将其卓越性能归因于 SP、MPFA 和 MP 模块产生的精细特征。此外,VisA 上的可视化结果如图 5(b)所示。作者的 Mask 更接近真实边界,而其他方法倾向于分割比真实边界更大的粗糙边界。相比之下,作者提出的 MFP-CLIP 可以更精确地描绘缺陷轮廓,并且作者的假阳性区域少于其他方法,这证明了多形式 Prompt 在零样本工业异常检测中的巨大功效。

4.3 消融研究
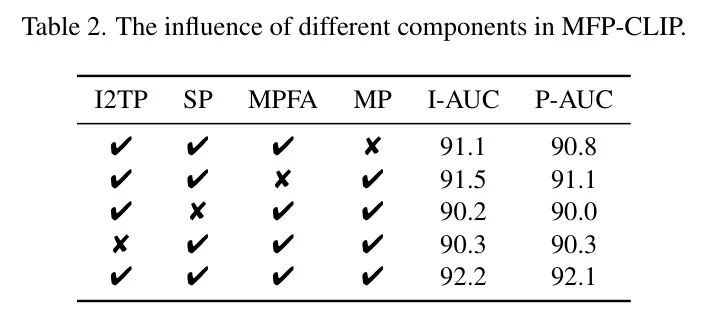
作者对 MVTechAD 进行了消融研究,以评估 MFP-CLIP 中所有组件的影响。表 2 报告了每个单独组件的重要性,展示了每个模块对整体性能的贡献。单一组件的消融可以清楚地识别每个组件的重要性,并提高对模型工作原理的理解。
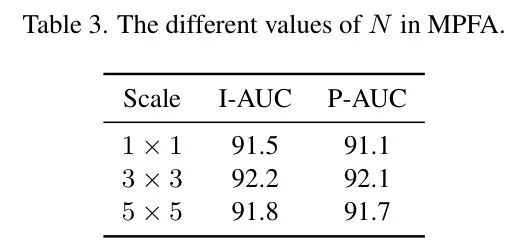
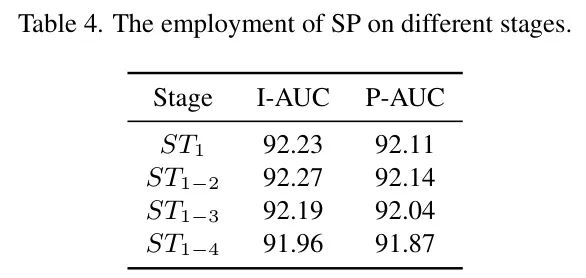
此外,作者还通过改变在多块特征聚合(MPFA)过程中聚合的 Patch 嵌入数量以及使用自 Prompt (SP)模块的阶段数量进行了程度分析。不同超参数的性能比较分别呈现于表 3 和表 4 中。
图像到文本 Prompt (I2TP)模块的消融实验。如表 2 所示,从第四行到最后行的性能提升表明了 I2TP 模块的优越性。手动设计的文本 Prompt ,如“一张正常/异常[物体]的图片”,难以准确表示详细的目标(类别)和状态(正常/异常)信息。没有 I2TP 模块,文本嵌入仅从文本模板中提取。性能下降了 1.9%的 I-AUC 和 1.8%的 P-AUC。这是因为从 CNN 提取的 I2T Prompt 将局部上下文引入文本 Prompt 中。它们提供了更详细的区域信息,有助于模型更好地理解目标类别和特征的空间分布。文本分支能够生成更精细和精确的文本嵌入,从而引导模型以更高的准确性识别异常。
自 Prompt (SP)模块的消融实验。为了评估 SP 模块的影响,作者在 MVTechAD 数据集上进行了消融实验,比较了 MFP-CLIP 在有和无 SP 模块时的性能。如表 2 的第三行所示,没有 SP 模块时,模型通过 ViT 提取图像特征,表现出次优的性能。没有 CNN 特征的校准,模型难以捕捉详细的局部上下文。相比之下,启用 SP 模块允许模型有效地校准 CNN 和 ViT 的特征,实现局部和全局表示的融合。例如,I-AUC 和 P-AUC 分别提高了 2.0%和 2.1%。此外,作者在表 4 中展示了在不同阶段使用 SP 模块时的性能。值得注意的是,当 SP 模块应用于第 2 至第 4 阶段时,性能没有显著提升。这可能与自注意力机制有关,它已经建立了跨框架特征之间的交互。为了降低计算成本,作者仅在第一阶段应用 SP 模块。
消融实验用于多块特征聚合(MPFA)。为了评估自适应平均池化在 N×N 邻域块嵌入中的重要性,其中默认将 N 设置为 3,作者进行了相应的消融研究,如表 2 所示。对于像药片裂缝和电缆弯曲这样的小而复杂的缺陷,MPFA 模块可以增强其边界的定位性能,这导致 I-AUC 提高了 0.7%,P-AUC 提高了 1.0%。此外,作者通过比较表 3 中报告的{1,3,5}的结果,寻找 N 的最佳值。不同尺寸块嵌入的聚合可视化如图 3 所示。适当地聚合邻域块嵌入有助于更大规模和复杂缺陷的处理,而当 N 过大时,特征将变得模糊。

消融实验针对 Mask Prompt (MP)模块。如图 6 所示,在没有 MP 模块的情况下,分割结果仍然不够精确,轮廓缺乏锐度,异常区域略大于真实值。当将 MP 作为视觉 Prompt 融入模型时,模型的定位精度从
提升至
P-AUC。异常区域变得更加明显,误检区域减少。
5. 结论
本文提出了一种名为 MFP-CLIP 的通用方法,通过跨框架特征对齐和边界细化来优化异常定位,尤其适用于小型和复杂缺陷。通过使用图像到文本 Prompt (I2TP)来增强文本 Prompt ,MFP-CLIP 能更好地表示图像中的物体,从而实现更精确的异常检测。自 Prompt (SP)模块结合了全局和局部特征。同时,还引入了多块特征聚合(MPFA)来增强对复杂和小型异常的感知。
最后,通过 Mask Prompt (MP),将异常的轮廓从粗粒度修改到细粒度。在两个主要的工业数据集上进行了大量实验,证明了 MFP-CLIP 在零样本异常检测中的优越性。
参考
[1]. MFP-CLIP: Exploring the Efficacy of Multi-Form Prompts for Zero-Shot Industrial Anomaly Detection
END
作者:小书童
来源:集智书童
推荐阅读
- ML-Triton:Intel 在 Triton GPU 编程的多级编译与语言扩展的工作
- MobilePlantViT 破局边缘 AI | 0.69M 超轻混合 ViT 实现 99% 分类
- Paddle-MLIR:编译时间减少 20%!边缘智能设备 AI 加速的革命性突破
- 一起聊聊 Nvidia Hopper 新特性之计算切分
欢迎大家点赞留言,更多 Arm 技术文章动态请关注极术社区嵌入式AI专栏欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

