本文图表数据来自甲子光年分析师团队;文内一手信息来自甲子光年记者团队对十余名SaaS渠道相关从业者的采访。

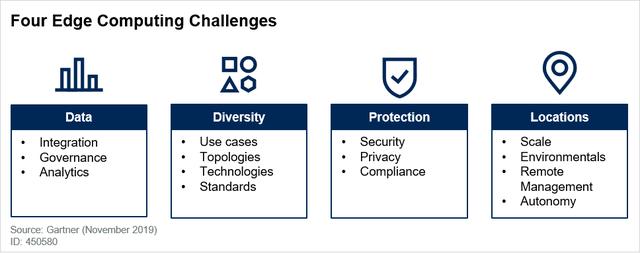
边缘计算用例范围很广,它的早期部署是高度定制的。基础设施和运营领导者需要制定一个多年的边缘计算战略,以应对多样性、位置、保护和...
本文将继续延续之前两篇文章(可以在文末查看链接),意在为在为开源云从业者道明开源与产业的发展方向及技术布局储备。前面两篇文章笔...

本文摘自于由阿里云高级技术专家王夕宁撰写的《Istio 服务网格技术解析与实践》一书,文章从基础概念入手,介绍了什么是服务网格及 Isti...

Arm中国创新教育中心(Arm Innovation Education Center China ,AIECC)是Arm中国和江北新区研创园共同打造,为南京江北新区打造集成电...

在快速开始中,我们演示了接入本地示例数据方式,但Druid其实支持非常丰富的数据接入方式。比如批处理数据的接入和实时流数据的接入。本...

阿里云-通过全盘镜像实现ECS(云服务器)从A账号迁移至B账号一. 在 A账号的ECS创建快照(系统盘+数据盘)与全盘镜像

因为疫情的关系,大部分人都熟悉了「霍尼韦尔(Honeywell)」这个略显拗口的名字,成为了人们口中大名鼎鼎的口罩制造商。

Service Mesh 架构下,服务间调用会通过服务名(Service Name)互相调用,比如在 Kubernetes 、Docker Swarm 集群中,服务 IP 均由集群...

概要本篇介绍怎样在全文字段中搜索到最相关的文档,包含手动控制搜索的精准度,搜索条件权重控制。手动控制搜索的精准度搜索的两个重要...

SpringBoot基于Spring框架进行“变态级“封装和扩展,由于上手简单、配置简单、集成简单,使得SpringBoot一跃成为近几年Java开发界的网红...

这篇文章写着写着,篇幅就变得有点长了,但是这对你很有帮助,因为我在写Java代码过程中进行了两步优化,过程都写下来了。

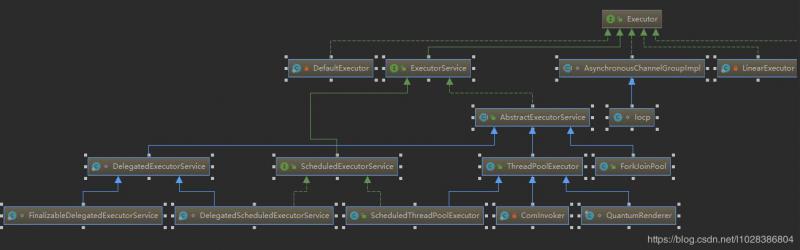
在上一篇《高并发之——不得不说的线程池与ThreadPoolExecutor类浅析》一文中,从整体上介绍了Java的线程池。如果细细品味线程池的底层源...
二维矩阵可以不产生一个图结构,直接在二维矩阵上计算。相应地,会设定一个布尔值数组visited[ i ] [ j ],表示某一个位置是否被遍历,t...

程序员不想直接点击运行,使用javac编译了Sample.java文件,可以看到Sample.java所在的目录下,生成了Sample.class文件。

既然Java中支持以多线程的方式来执行相应的任务,但为什么在JDK1.5中又提供了线程池技术呢?这个问题大家自行脑补,多动脑,肯定没坏处...
HDFS High AvailabilityYARN High AvailabilityHBase High AvailabilityMost aspects of HBase are highly available in a standard con...
1、环境说明操作系统CentOS Linux release 7.4.1708 (Core)Ambari2.6.xHDP2.6.3.0Spark2.xPhoenix4.10.0-HBase-1.22、条件HBase 安装完...

在Druid快速入门其实已经简单的介绍过最简化配置的单节点部署,本文我们将详细描述Druid的多种部署方式,对于测试开发环境可以选用轻量...
本次Release版本修复1.2K个问题,对Flink作业的整体性能和稳定性做了重大改进,同时增加了对K8S,Python的支持。