从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取...

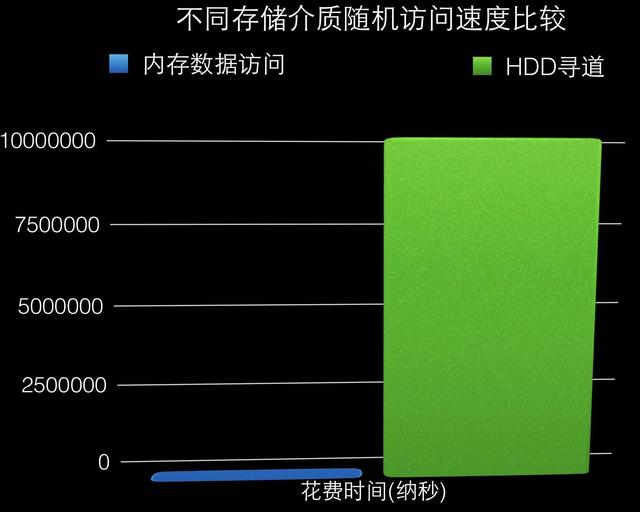
作为一名应用系统开发人员,为什么要关注数据内部的存储和检索呢?首先,你不太可能从头开始实现一套自己的存储引擎,往往需要从众多现...
在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根...

今天,随着移动互联网、物联网、AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的“资产”。如何从数据中获得有价...

🚙 Index数据采样的原因常见的采样算法失衡样本的采样采样的Python实现📚 数据采样的原因其实我们在训练模型的过程,都会经常进行数据采样...
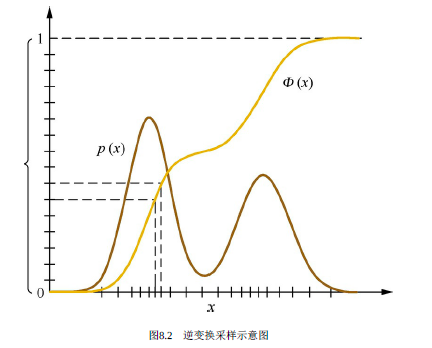
我们在用Python进行机器学习建模项目的时候,每个人都会有自己的一套项目文件管理的习惯,我自己也有一套方法,是自己曾经踩过的坑总结...

在 QCon 北京 2019 大会上,赵云讲师做了《苏宁 OLAP 引擎发展之路》主题演讲,主要内容如下。

今天我们来看一下淘宝、美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图。通...
结束比赛有几天了,这几天一直在处理前段时间堆积的工作,今天得空对自己的方案进行梳理总结。今年7月多结束魔镜杯后,将之前的内容整理...
资金流动性管理迄今仍是金融领域的经典问题。在互联网金融信贷业务中,单个资产标的金额小且复杂多样,对于拥有大量出借资金的金融机构...

在正式开始前,千万不要把这一步与数据可视化或数据结果统计混淆——数据可视化或数据结果统计意味着结果。

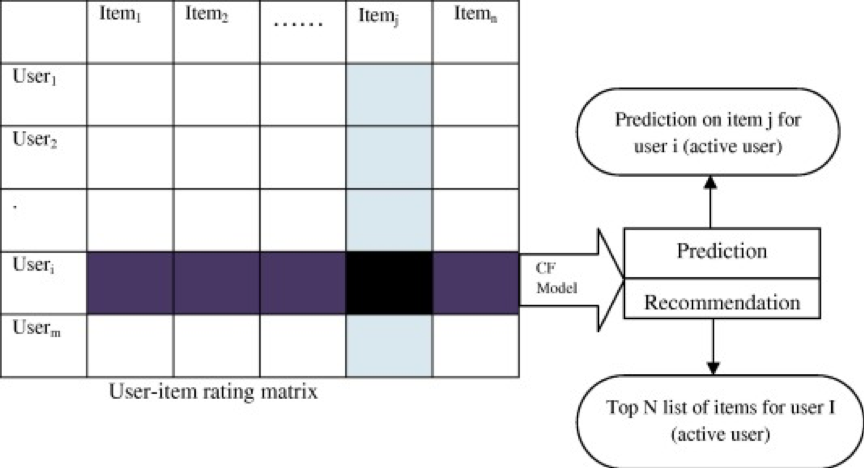
与基于内容的过滤(CBF)不同,协同过滤(Collaborative Filtering)技术独立于域,适用于无法利用元数据充分描述的项目,如电影、音乐等。
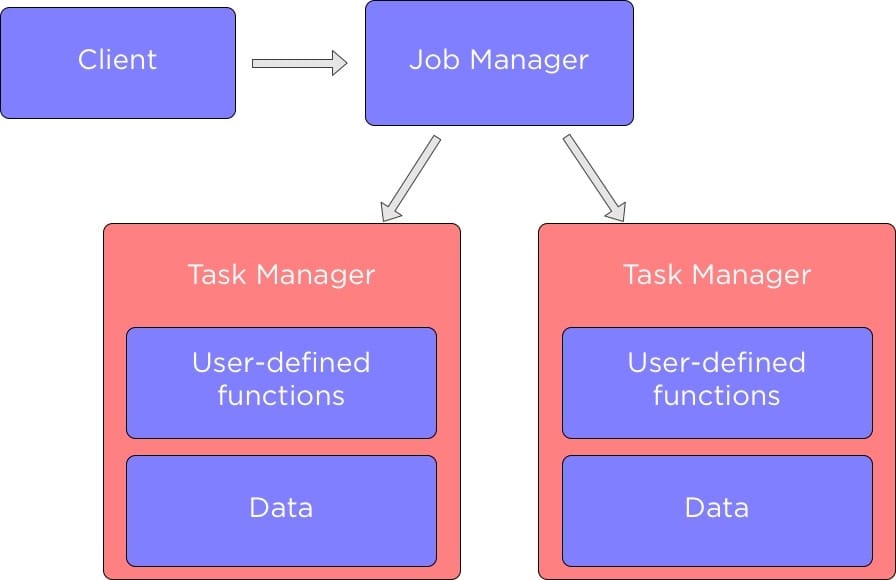
JobManager 的作用<!--more-->[链接]博客1、Flink 从0到1学习 —— Apache Flink 介绍2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6...
如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的。最着名的例子是 Apache Hadoop,还有较新的框架...

更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他...
之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处...

如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据。但是在某些情况下,我们需要将配置...
要问什么水果和夏天最搭,答案一定是西瓜。作为西瓜生产与消费大国,中国在 2018 年以全世界 20% 的人口消耗掉全世界 70% 的西瓜,人均 ...

数据科学就业市场变化迅速。以前,只有少数卓越的科学家才有能力创建机器学习模型。但如今,仅有基本编码经验的人也可以按照步骤训练简...
图解:机器学习、人工神经网络、深度学习、数学基础、深度学习之外的人工智能、深度学习框架下的神经网络