
转载于:知乎
作者:djh
文本分类
1、概述
文本分类是在nlp中很重要的模块。也是nlp任务中比较基础的模块。可以应用到很多领域:比如情感分析,新闻分类,垃圾邮件过滤等等。应用是非常广泛的。目前文本分类分为传统方法和深度学习的方法。在深度学习中文本分类又可以分文有监督学习的和无监督学习。但是无论何种方法文本分类最终应该是属于数学的集合的归类问题。
假设给定字符串集合 ,在给定类别集合。存在一个函数 ,R取值{0,1}。如果,表示文本 属于 类。反之不属于。(当然,从上面的f分类器,可知 可以属于多个,则变成多分类问题)f函数,我们称之为f分类器或者说文本分类模型。根据分类器的发展,通常可以将文本分类的发展分为两个阶段:1、传统方法阶段 2、深度学习阶段
本文将文本分类开发过程中关键的几个模块进行描述,包括前期的分类体系,数据工程和模型,测试。主要描述工程方面遇到的一些问题。
2、确定分类体系。
其实在分类前期除了做数据处理和特征的选择外,最应该先了解的是分类体系。确定好分类类型和分类体系是完成任务好任务的关键。如果是简单的几个分类倒是还好。但是一旦类别多了就很难说的清楚谁应该属于哪一类别。确定好的分类体系应该明确以下几点:
- 1.类别之间有无重叠边界是否清晰
- 2.类别之间有无上下级关系
- 3.输入数据是否存在于所有类别。
整个分类体系的建立,需要专业性,完备性和系统性。前期如果对算法的输入没有个完备的分类体系后期对于算法开发人员,测试以及产品人员都是不好的。会有很多没必要的争吵。
3、数据的预处理。
数据预处理包括中文分词、去除噪音和数据增强。当然还有pca降维等方式对数据进行处理,根据工程任务也可能会有其他很多方式这里不详细讲述。
分词:分词应该很容易理解了,有很多分词的工具比如jieba分词,ltp分词等等。其实在后面会讲到在用一些比较强大的深度学习模型以后可能不需要分词。
去除数据的噪音:比如停用词(的,是,了等等),还有就是业务上需要去除的,有些文本不是很干净的,有的是有乱码或者其他字符,可能也是需要你把他去除。比如我在业务中又遇到过ocr后数据会有很多句号,很多“囧”,或者韩国的文字,或者日本的文字出现。
数据增强:在文本太少的时候,模型或者算法达不到好的效率,可以采用一些数据增强的方法进行数据的增加。
4、特征工程
4.1、文本表示
在字符串集合 ,其中,是由多个字符(设字符 构成的字符串(如:“关羽是一个厉害的角色”),在机器处理中,我们首先要将这些文本转换为机器可识别的数学表示。就是对文本进行向量化。可以分词以后进行向量化,也可以不分词直接使用字符进行向量化。
- Onehot
OneHot 是最原始,最直接的文本向量化的方法。对于词向量为例子,假设词典中有N个词语。每个词的词向量可表示为: ,该词在对应位置编号为1,其他的为0。onehot编码的缺陷是很明显的,每个词或者字向量之间没有关联性非常的独立,而且当N过大时,词向量或者字向量变得非常的稀疏。
- Word2Vec
伴随着onehot,以及文本向量表示带来的问题,人们需要这总文本向量的表示并非冷冰冰的独立,上个字和和下一个字,上一个词语和下词语是有关联性,这个时人们的常识。于是Mikolov等人提出了Word2vec的词向量训练的方法。通过训练得到词语之间的联系。从而形成一定的向量表示。
Word2vec的参考文章:
https://zhuanlan.zhihu.com/p/...
- Embedding
随着神经网络的发展和word2vec的提出,Word Embedding的概念深入人心。与训练出一个好的embedding变得非常重要,embedding的任务就是将文本之间的额关联性表示出来,也就是设计各种网络训练出一个表示文本语义的文本向量。这种网络除了,word2vec,glove,fastext等,还有后面google的bert。一个好的embedding对文本分类任务时至关重要的,以至于后面的网络越来越复杂,维度越来越高,bert的与训练模型达到几百兆个参数。
Bert分类的参考文章:
https://zhuanlan.zhihu.com/p/...
4.2、特征工程
特征工程在传统的机器学习中经常使用,虽然在深度学习中已经不经常用到,但是其思想还是有必要学习的,有些方法在现在的很多文本处理中依然很实用。其中有TFIDF、信息论(信息增益,期望交叉熵,互信息,卡方校验),文档话题语义(LDA,LSI)和文本相似提取等多种方式。我们挑了其中的一些
- Tf-idf
TFIDF主要描述的是某个词语出现在某个文章中的频率越高,而且在其他的文章中出现的频率越少,说明这个词语专有属性是属于这篇文章的。TFIDF的参考文章:
https://zhuanlan.zhihu.com/p/...
- 期望交叉熵
用一个本身的概率统计信息量和目前实验的信息量之间的距离值作为一种衡量标准。表示词条对该类别的距离。交叉熵的参考文章:
https://zhuanlan.zhihu.com/p/...
- 文本相似度
文本相似度用于前期的数据处理,可以提升工程的效率。也有传统的,也有深度学习语义相似度的方法。具体参考如下文章。
短文本相似度:
https://zhuanlan.zhihu.com/p/...
语义文本相似度:
https://zhuanlan.zhihu.com/p/...
5、分类模模型
5.1、传统方法
- Knn
最好的传统统计的方法就是knn了,通过已经标注好的数据,全部输入库中,在取用的时候取出K个相邻的数据点,查看K个数据点成分最多的是哪个类别就标注为哪个类别。
- 朴素贝叶斯分类
它是基于条件概率里面的贝叶斯定理扩展开来的分类算法。有可靠的理论基础。朴素贝叶斯详细的分类文章参考如下:
https://zhuanlan.zhihu.com/p/...
- 支撑向量机(SVM)
SVM的分类方法的基本思想是在向量空间中找到一个决策平面,这个平面能最好地分割两个分类中的数据点。
5.2、深度学习的方法
深度学习的分类方法有很多,主要的好处是通过神经网络去提取文本的特征,自动的进行分类。但是这样不好的地方就是说,解释性和可控性变弱。深度学习的模型有很多,fastText,cnn,attention,TextRNN + Attention,TextRCNN(TextRNN + CNN),bert等等。我挑选其中几个讲解下。
- FastText
Fasttext是Facebook AI Research最近推出的文本分类和词训练工具,其以及开源。Fasttext最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快,在普通的CPU上可以实现分钟级别的训练,比深度模型的训练要快几个数量级。同时,在多个标准的测试数据集上,Fasttext在文本分类的准确率上,和现有的一些深度学习的方法效果相当或接近。
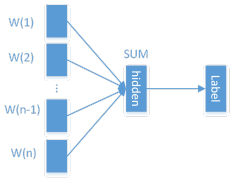
Fasttext解决的问题有很多比如多分类的性能问题和精确到字的N-Gram的问题。但是在这里我们使用它主要是看中它的精确度和性能能力。
- TextCNN
CNN用于我们的文本分类时,前期的CNN卷积卷积层能够提取大量的语言特征,再经过池化进行特征衰减,最后经过softmax进行归一化从而得到最终需要的分类。
①输入层是将语料经过预训练好的Word2Vec模型得到的词向量表达,然后在经过卷积层,其中卷积核的宽度是固定的,等于词向量的维度,而卷积核的宽度为3/4/5,在输入的句子上进行一维卷积,其实这就相当于构造3-gram,4-gram,5-gram的特征。再用最大池化操作提取最关键的特征,最后拼接池化后的向量,再接输出层,完成分类操作。
②使用CNN的其中一个最大的优势在于:能快速构造n-gram特征,相比于传统的n-gram算法,当n=5时,计算量已经非常巨大,而卷积操作的算法的复杂度远远小于传统的n-gram算法。
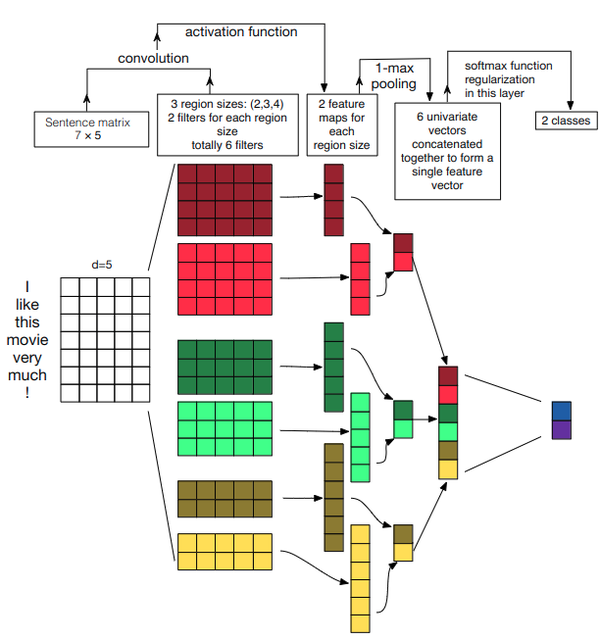
- TextRNN
①尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter\_size 的视野,一方面无法建模更长的序列信息,另一方面 filter\_size 的超参调节也很繁琐。
②RNN的数学基础可以认为是马尔科夫链,即认为后续的值是有前者和一些参数的概率决定的。
③RNN非常适合于时间序列问题,善于捕获长时间序列,然而朴素RNN结构存在梯度消失和爆炸问题,对于梯度爆炸,可以通过裁减的方式解决,而梯度消失问题,显得捉襟见肘。所以衍生出了LSTM网络结构,该网络结构能够很好解决梯度消失问题。由于标准的循环神经网络(RNN)在时序上处理序列,他们往往忽略了未来的上下文信息。所以设计出了Bi-RNN网络结构
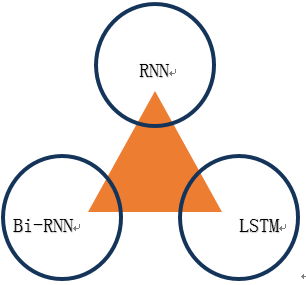
对比上面的三个模型,CNN、RNN和Fasttext。各有各的优势。CNN对于特征提取比较明显,RNN对于字词的关联性比较好,Fasttext相对于前面两个模型最大的优势是性能好,速度快。
- Bert
Bert模型是google2018年推出的语言模型,语言模型预训练可以显著提高许多自然语言处理任务的效果,在各个领域都有很大的提升。
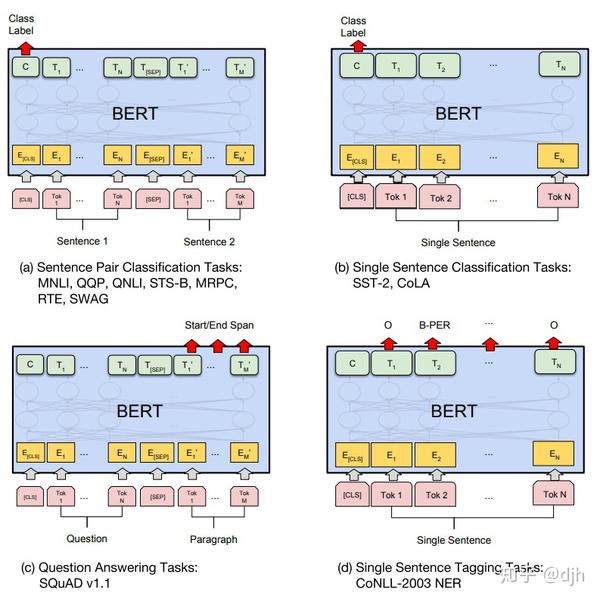
Bert文本分类的简单参考:
https://zhuanlan.zhihu.com/p/...
5.3、多模型融合
通常来说多模型融合是最后工程阶段的提升准确率的大招,不轻易出手,一出手确实能达到好一点的效果,但是带来的性能的下降。下面多模型的经验文章供大家参考。
模型融合(Blending & stacking) & 数据增强mp.weixin.qq.com
6、分类评价指标
1.准确率(Acc):
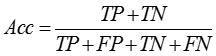
2.精确率(P):
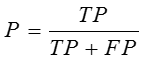
3.召回率(R):
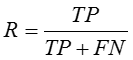
4.F1 score:
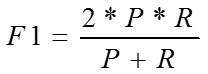
7、分类实践
在工程中提升文本分类准确率的方法,按照我的经验总结了一些内容供大家参考。
- 在前面开始工程化阶段一定要对输入的数据要有个清晰的认识,就是对输入的类别,类型,要有个系统化得认识。然后如果输入数据有脏数据,要有好的方法对数据进行清洗,包括聚类,相似度等等方法,而不是人为的一个个挑选。
- 挑选一个好的模型,如bert等。然后基于模型的结构调整模型超参数,这个也是基于你对你将要分类的数据的认识,而不是乱调。
- 尽量丰富模型的输入数据的特征。
- 关于分词还是部分词,目前我的实践来看,不分词直接用字挺好的。Bert也是字符级别的。
- 多模型融合要分开数据分开多种模型,最终其实也是增加特征,然后进行投票选择。后面实在准确率提升不了的话可以用多模型提升一两个点,但是带来的是工作量和性能的损失。
6、如果你有充分的算力和时间,可以训练自己领域内的embedding。也能提升一两个点。
END
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

