
增量推理
鹏程.盘古的基础结构是Transformer的Decoder模块,这种自回归(Auto-regressive)的语言模型会根据上文预测下一个字,因此在推理时会根据输入的文本逐字(词)生成。显然这种方式会导致每一步推理的网络输入shape在不断变大。
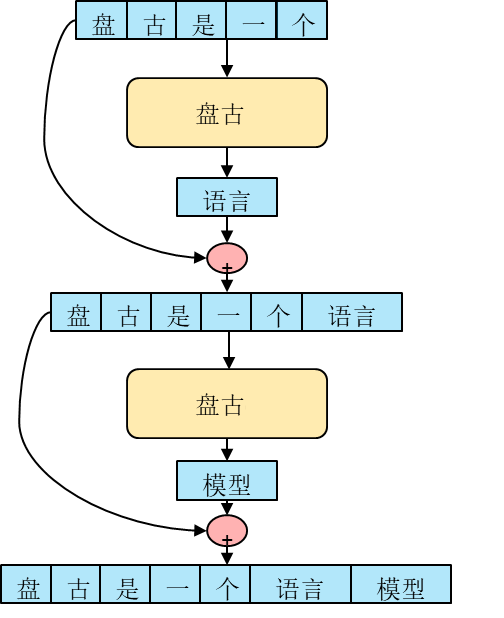
静态图执行时,要求图中每个算子的shape不能改变,否则执行会报错;动态图执行时,在不同迭代间,图中每个算子的shape可以改变,不过改变了算子shape,就无法利用之前缓存的算子编译信息,每次都需重新编译,会影响性能。因此对于这种自回归模型,通用做法一般为将输入padding到固定长度(如1024),以此保证每一步推理各个算子的shape保持一致。
这种padding的方式易于实现,无需做算法修改,但是明显会引入冗余计算,会极大地降低推理的性能。
结合Transformer的attention结构特点,业界有一种状态复用(state reuse)的改进算法,以下称增量推理。
Attention机制可以由下式表示
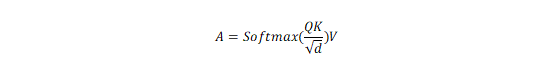
其中Q和V的shape为(batch_size, num_heads, seq_length, size_per_head);K的shape为(batch_size, num_heads, size_per_head, seq_length)。
对应维度为seq_length这一维,每一个位置分别对应输入的相应位置,回顾图1的形式,不同步的输入,其前面的部分完全相同,当计算seq-index为i的位置时,前面0\~i-1位置对应的state在上一步推理中已经计算过,因此在整个推理过程中存在很多的重复计算,如果能够通过某种方式保存下当前步计算出的state供给下一步使用,即可省掉这些重复计算,这便是增量计算的思想,下图展示了增量推理的计算逻辑。
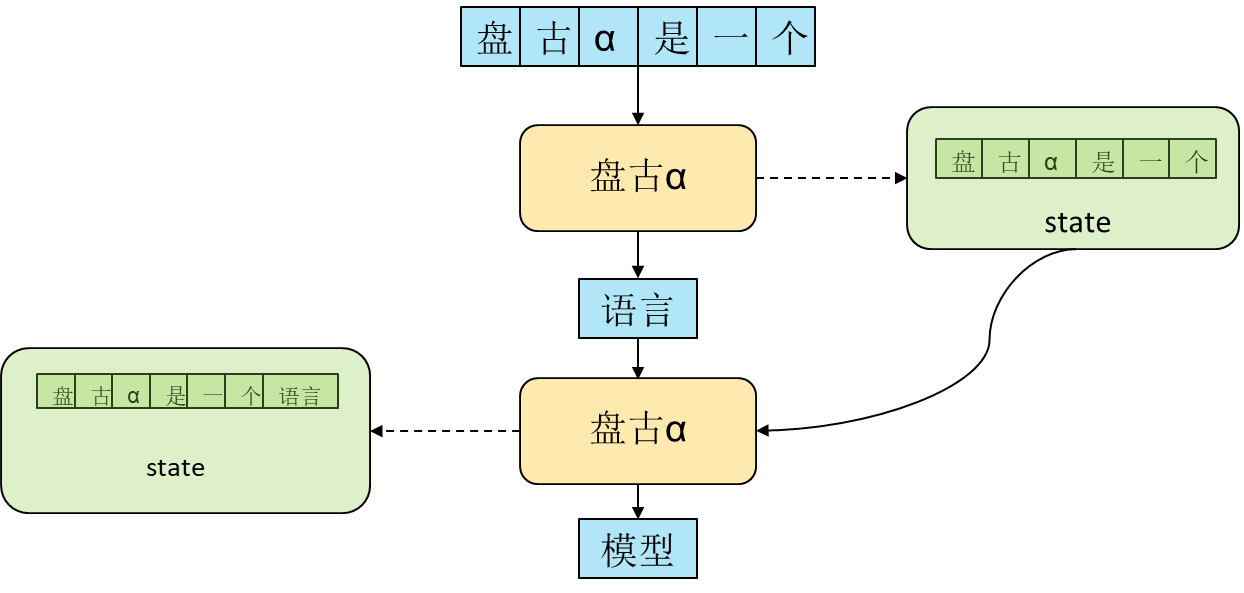
当使用增量推理的时候,
- 首先将使用完整输入推理一步,此时通过某种方式保存下来输入对应的state,
- 在第二步推理时,输入仅为上一步推理得到的字(词),然后将本步推理得到的state与保存下来的前序state拼接,作为本步推理的完整state,同时再次保存state,得到本步的输出字(词)
- 重复步骤2,直到推理结束。
通过这种方式,在需要多次运行的步骤2中,可以保证最小的输入shape(seq_length=1),这样可以极大提升推理性能。
MindSpore1.3实现增量推理
详细分析上述增量推理的步骤,有两个问题:一是第一步推理的输入是不定长的,后续推理步骤的输入是固定长度(seq_length=1);二是如何通过“某种方式”保存下中间的state。
对于第一个问题,当使用动态图模式时,每次推理的第一步都会遇到一个不定长的输入,在后续步中,将本次推理的state与前序state拼接时也会遇到长度不断增加的情况,不过这种不定长的情况对于动态图来说,不会出现执行错误的问题,只会有些许性能损失。而当使用静态图时,这两个不定长的情况则会直接导致执行错误。
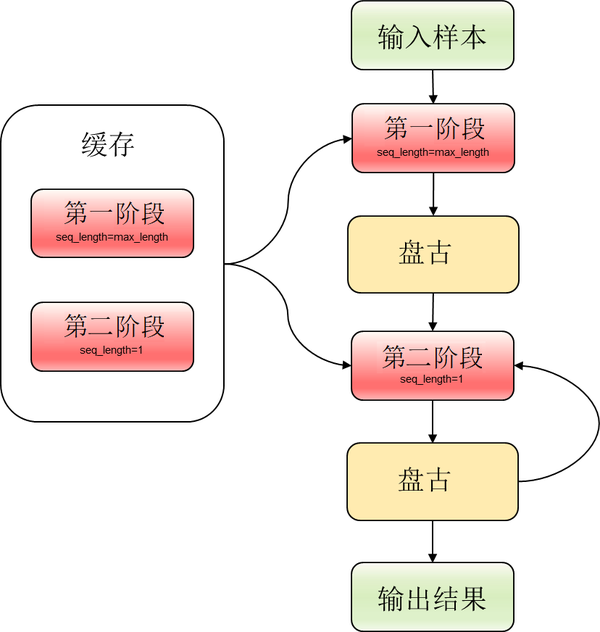
在使用MindSpore实现时,对于第一步推理,我们将输入padding到max_length(1024长度),这样应对不同输入语句时不会遇到shape改变的情况。对于state拼接时,我们并没有使用concat来进行拼接,而是使用加法来进行“拼接”,将所有的state存储到max_length长度的向量中,只更新其有效对应位置的值,其余位置置零,最后使用加法进行“拼接”,具体流程如下图所示。
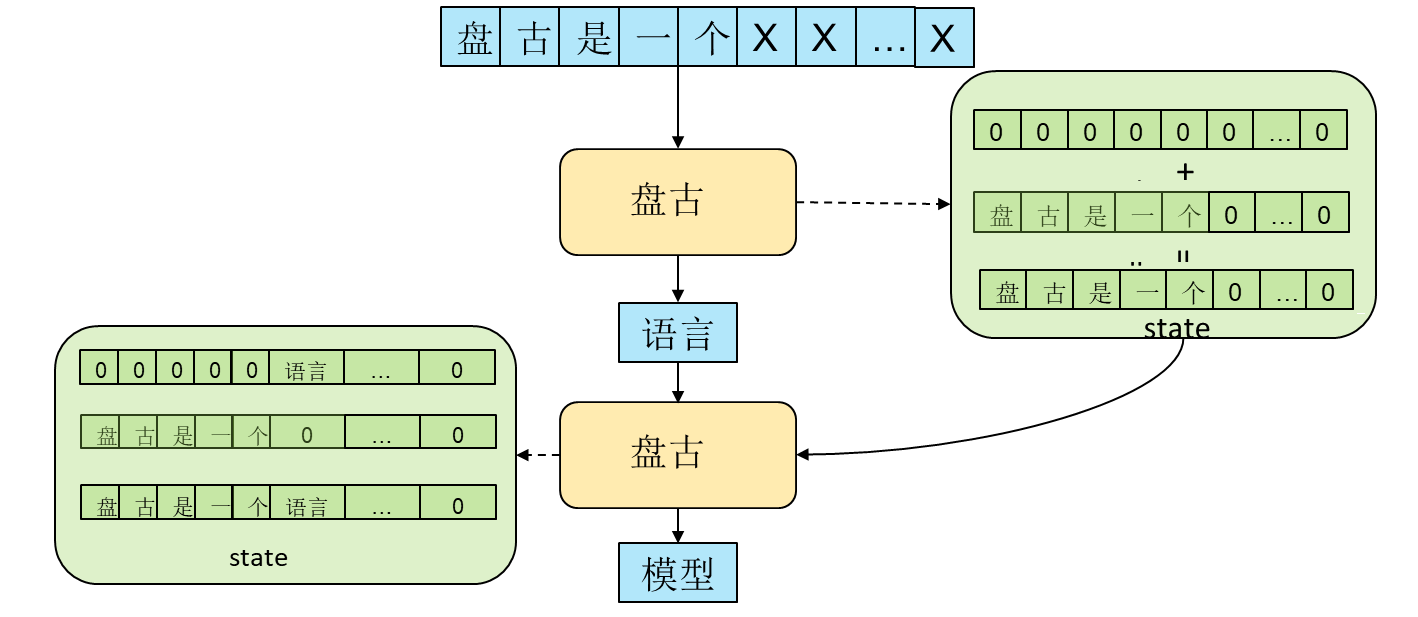
由于使用增量推理的方式,我们将推理过程分为两个阶段,两阶段共享参数。第一阶段(seq_length=max_length)执行一步,然后执行第二阶段(seq_length=1)若干步。当对下一个样本进行推理时再重复上述步骤,具体流程如下。
对于问题二,该如何通过“某种方式”保存中间的state。最直接的想法是将state作为网络的输出返回到host侧,再下一步推理时,再将state作为输入传递给网络。这种方式明显的问题在于每一步的state的传入与传出,很遗憾的是,state的维度过大,经我们实验发现对于鹏程.盘古13B的模型,当输入seq_length=1时,推理耗时基本与state的传出耗时接近。因此很自然的我们将state保存在了device上,作为一个网络的parameter,从而避免了state的传入传出。
我们通过鹏程.盘古在Ascend910上进行了一系列实验,结果如下图所示:
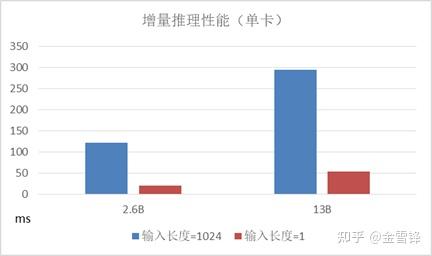
可以看出使用了这种增量推理的方式,第二阶段(输入长度=1)的执行速度可以达到第一阶段(输入长度=1024)的5倍,随着bs的增大,提升愈发明显。而且在增量推理过程中,第一阶段只执行一次,而第二阶段会执行多次,整体性能提升比较明显。
需要指出的是,由于网络中LayerNorm算子的存在,增量推理与常规推理在数学原理上并不完全等价,不过在我们的下游任务实验中发现,增量推理与常规推理的精度基本一致。
分布式推理
盘古alpha是最大的稠密形式的中文预训练语言模型,拥有2000亿参数。如此庞大的模型在推理时,无法简单地部署在单卡上,需要使用分布式推理。
分布式推理是指推理阶段采用多卡进行推理,分布式推理与单卡推理相比,大部分流程相似,其中并行策略的给定和分布式训练情况下脚本一致,即通过设置并行策略配置模型并行、通过设置pipeline_stage配置pipeline并行,相应的HCCL集合通信算子会由自动并行模块自动插入。
对于鹏程.盘古模型的分布式推理,我们使用了如下图所示的两种并行策略,分别是OP-Level和PipeLine模型并行。
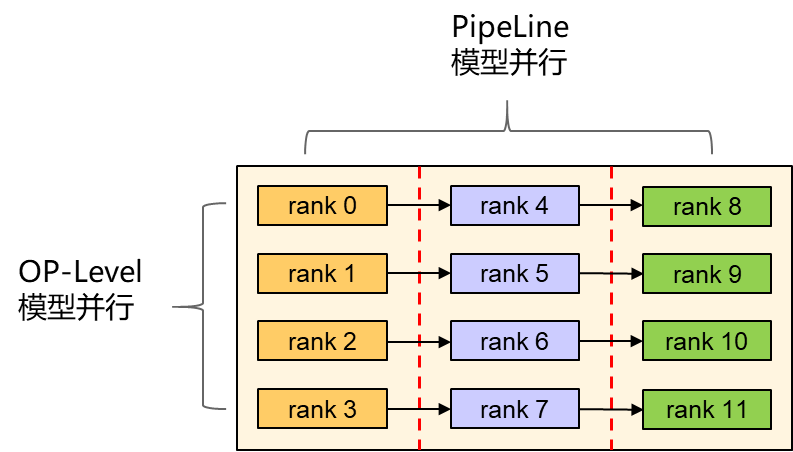
OP-Level模型并行是算子级别的并行,会将单个tensor在不同的维度进行切分,每块卡只保存tensor的一部分;pipeline模型并行是将整个模型切分为几张子图,每张子图放置在若干节点上。跨子图的通信需要使用Send/Recv算子,而不同分布的tensor之间需要使用AllReduce/AllGather等算子进行tensor的重新排布。需要正确的插入通信算子才能保证执行结果的正确性。
具体可参考往前文章:
如何看待华为 4 月 25 日发布的盘古智能大模型?在这个行业处于什么水平?www.zhihu.com
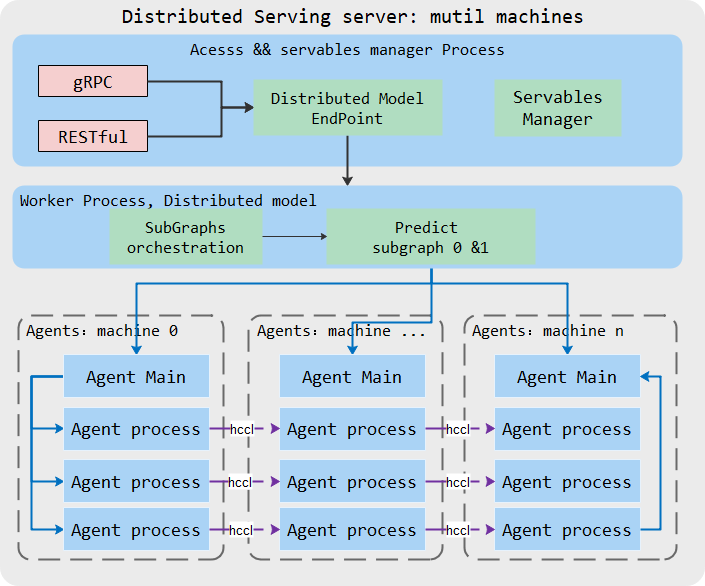
MindSpore1.3 Serving部署盘古推理
一次完整的推理会话包括多个tokens的生成,增量推理的两个阶段的每次推理将生成一个token,需要多次推理,且过程中需要保持和共享权重数据(包括state数据)。
在MindSpore Serving中实现上述增量推理部署,将遇到以下两个问题:两个阶段的推理输入长度不同,存在两个推理入口;由于推理的state在每单次推理后更新,以用于下一次增量推理,所以增量推理是有状态的模型,在一次请求执行结束前不能有其他请求中间干扰。
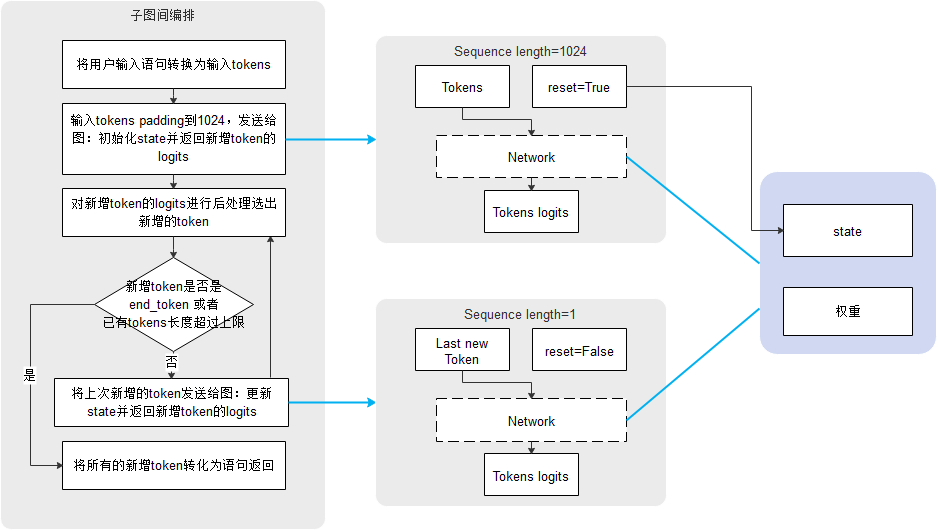
为解决上述问题,通过子图间编排串接两个阶段(体现为两个子图)的执行,一次子图编排脚本的执行作为一次推理会话,仅当上次推理会话执行结束后,才会执行下一次会话,避免多个会话同时执行相互干扰。具体的推理过程如下:
- 在模型配置Python脚本中定义串接两个阶段的编排脚本。
- 启动Serving服务器,加载模型。
- 客户端通过gRPC或者RESTful将请求文本语句发送给Serving服务器;
- Serving服务器执行编排脚本。
- 在编排脚本中,输入文本语句转换为一组tokens,传递给子图0(输入长度为1024),初始化state数据,产生一个新的token。
- 新增的token数据将传给子图1(输入长度为1),子图1每次接受上一次新增token,更新state数据,继续产生下一个token。
- 持续步骤6,直到满足条件退出生成。
- 将所有新增的tokens转换为文本语句返回给客户端。
注:分布式推理目前还只支持昇腾,其他芯片的支持正在进行中。
原文:知乎
作者:金雪锋
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

