
本文转自:知乎
作者:金雪锋本次小伙伴们带来的是论文《TT-REC: Tensor Train Compression For Deep Learning Recommendation Model Embeddings》分析,很有意思的论文,对解决Embedding Table太大耗内存的问题有比较好的参考意义。
一.介绍
在工业界,深度学习推荐网络(DLRM)中的Embedding表的大小往往以GB到TB的量级,对计算资源例如内存提出了更高的需求。为了解决此问题,本文通过将Embedding表分解为多个小矩阵的乘积的方式进行压缩,以计算换取空间。本文证明了一种针对DLRM的Tensor Train decomposition方法的优势,设计一种优化的kernel方法(TT-EmbeddingBag),在内存占用,模型精度和耗时三个维度上对TT-Rec方法进行了评估,证明TT-Rec方法能够在Kaggle数据上压缩模型4倍和221倍,而对应的loss精度仅损失0.03%和0.3%。而在Terabtye数据集上,能够实现112倍的模型压缩,并且和非压缩方法的baseline相比,没有loss精度损失和训练时间的增加。
代码开源地址:https://github.com/facebookresearch/FBTT-Embedding
二.背景
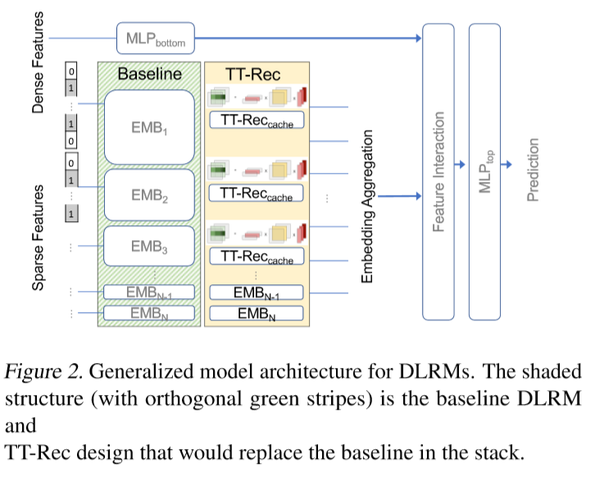
下图展示了DLRM模型的通用结构,左边方框表示非压缩版本的基线,右边方框表示本文提出的TT-Rec结构。DLRM主要由两个部分组成,多层感知机(MLP)和Embedding表(EMBs),其中MLP是用来处理连续特征的,EMBs通过将高维稀疏的输入编码成低维度稠密的表示,来处理类别特征。Embedding表中通常有数千万行并且在未来会呈现指数级别的上升,因此对内存提出了TB级别的需求。而且,EMB查找的过程中会在表之间同时收集多个embedding向量,会造成内存带宽的挑战。
Tensor-train decomposition方法
和例如奇异值分解(SVD),主成分分析(PCA)等矩阵分解方法类似。Tensor-Train decomposition通过将多维数据的表征转换为一系列矩阵的乘操作,以进行矩阵分解。给定一个d阶的张量A,A中的某个元素值可以通过多个三维的Tensor的乘操作得到。
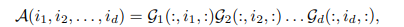
其中Gk的维度为(Rk-1, Ik,Rk),序列 {Rk}叫做TT-Ranks,每个三维张量Gk叫做TT-core.
TT分解也可以应用到一个(M,N)的矩阵W。在此假设M,N均可以分解为一系列整数的乘积,可以将W矩阵reshape为2维度的tensor w
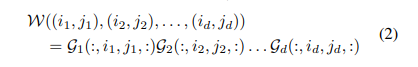
其中每个4维度Gk属于(Rk-1, mk, nk,Rk), 并且R0=Rd=1. 假设R,m,n表时k=1,..,d个TT-Core中最大的rk,mk和nk。单个TT-core最大的空间占用R*m*n*R, 所以TT格式能够将存储矩阵的空间从O(MN)降低为O(dR2max(m,n)2)
三. 建模方法
Embedding查找表示:每个embedding的查找操作可以用一个独热编码的向量矩阵乘法w=eW表示,其中ei表示第i个位置为1,其他都为0. 可以通过如下式子,将Embedding表w进行压缩,因此一个第i行的embedding查找操作可以多个张量乘积来表达
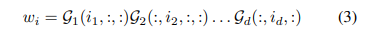
在实际操作中,通过展开TT-Core的表达式,可以将张量的乘积操作变成矩阵乘法。通过梯度来更新TT-core的参数。
权值初始化:通常情况下更大的TT-ranks会拥有更低的压缩率和更小的精度损失,但是本文作者发现随着TT-ranks变大,精度的提升很快达到一定程度就不再上升。TT-Cores的权重初始化能够显著的影响模型的质量。在非压缩模型中,通常采用均匀分布或者高斯分布去初始化Embedding表就能取得较好的效果。然而采用高斯或者均匀分布初始化TT-core时,一系列的乘积操作会将权重初始化变换为非期望的部分(下图左)。因此,作者以非压缩模型的均匀分布作为标准,采用KL散度描述高斯分布和[a,b]上面的均匀分布之间的距离,通过最小化KL散度,得到近似均匀分布的最佳高斯分布参数N(0, 1/3n)
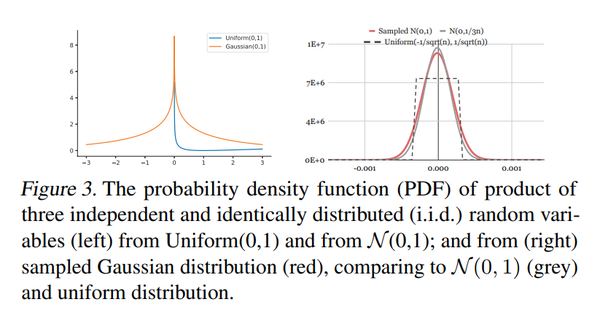
性能优化:在推荐领域,输入的稀疏特征往往呈现近似的长尾分布,使得一些embedding向量会频繁在训练中进行更新。因此作者针对这个出现频次高的embedding向量设计了一种缓存机制。给定输入的id,首先会被分成两个组别:缓存部分和tt部分。缓存组别的id会直接从cache中读取非压缩的embedding向量 ,而tt部分的id会使用TT-Rec方法去计算对应的embedding向量。
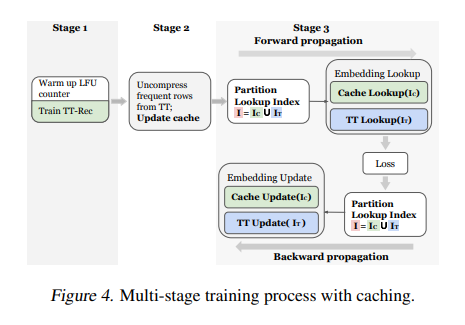
四.实验
作者从内存消耗,模型精度和训练时间三个方面给出了TT-Rec的结果。
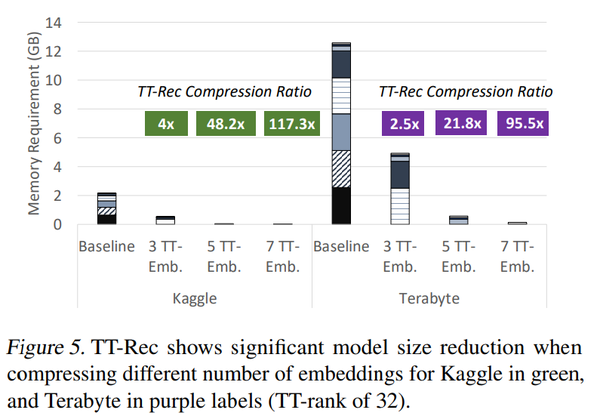
内存:在Terabyte和Kaggle数据集上面,TT-Rec最大能达到327倍的模型压缩倍率和平均181倍的压缩率。在非压缩的基线模型中,7个最大的表内存占用了模型的99%。通过使用TT-Rec,在Kaggle数据集上面将7个表的内存占用从2.16GB降低到18MB,达成112倍的模型压缩。如下图给出了在两个数据集上,将7个最大的表分别通过3,5,7个TT-Embs去表示而达成的模型压缩率。
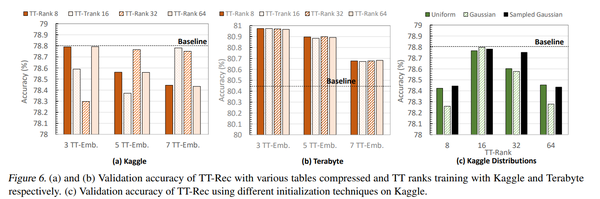
精度:在Kaggle数集上,采用TT-Rec方法去训练前3,5,7个最大的表时,达到近似基线模型精度的最优rank是不一样的,而在Terabtye数据上,采用TT-Rec方法能够提升模型精度,并且随着使用TT-Rec方法训练的表越多,模型精度也就下降的越多。下图表c表示了TT-core的权值初始化的影响,可以看到sampled高斯分布的精度较高,是因为近似最佳的初始化部分N(0,1/3n)
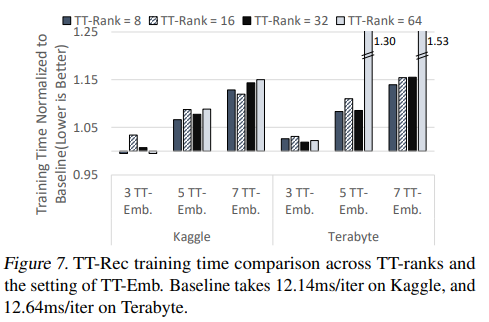
时间:随着TT-Emb的数量越多,训练时间都呈现上升的趋势。因此在实际使用中,需要结合内存要求,模型质量和训练时间考虑选择最优的参数。
五. 结论
TT-Rec的核心是使用基本的参数化方法帮助控制对计算设施过度的需求上。将巨大的Embedding表替换为一系列的矩阵乘积操作,能够将模型内存压缩112倍同时仅增加13.9%的训练时间,并且在模型精度上没有损失。
六. 参考文献
Yin C, Acun B, Wu C J, et al. TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models[J]. Proceedings of Machine Learning and Systems, 2021, 3.
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

