
Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting、Self-Consistency等;项目实战搭建知识库内容机器人

1.ChatGPT Prompt Framework
看完基础篇的各种场景介绍后,你应该对 Prompt 有较深的理解。之前的章节我们讲的都是所谓的「术」,更多地集中讲如何用,但讲「道」的部分不多。高级篇除了会讲更高级的运用外,还会讲更多「道」的部分。高级篇的开篇,我们来讲一下构成 prompt 的框架。
1.1Basic Prompt Framework
查阅了非常多关于 ChatGPT prompt 的框架资料,我目前觉得写得最清晰的是 Elavis Saravia 总结的框架,他认为一个 prompt 里需包含以下几个元素:
- Instruction(必须): 指令,即你希望模型执行的具体任务。
- Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
- Input Data(选填): 输入数据,告知模型需要处理的数据。
- Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式。
只要你按照这个框架写 prompt ,模型返回的结果都不会差。
当然,你在写 prompt 的时候,并不一定要包含所有4个元素,而是可以根据自己的需求排列组合。比如拿前面的几个场景作为例子:
- 推理:Instruction + Context + Input Data
- 信息提取:Instruction + Context + Input Data + Output Indicator
1.2 CRISPE Prompt Framework
另一个我觉得很不错的 Framework 是 Matt Nigh 的 CRISPE Framework,这个 framework 更加复杂,但完备性会比较高,比较适合用于编写 prompt 模板。CRISPE 分别代表以下含义:
- CR: Capacity and Role(能力与角色)。你希望 ChatGPT 扮演怎样的角色。
- I: Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。
- S: Statement(指令),你希望 ChatGPT 做什么。
- P: Personality(个性),你希望 ChatGPT 以什么风格或方式回答你。
- E: Experiment(尝试),要求 ChatGPT 为你提供多个答案。
以下是这几个参数的例子:
| Step | Example |
|---|---|
| Capacity and Role | Act as an expert on software development on the topic of machine learning frameworks, and an expert blog writer.<br/>把你想象成机器学习框架主题的软件开发专家,以及专业博客作者。 |
| Insight | The audience for this blog is technical professionals who are interested in learning about the latest advancements in machine learning.<br/>这个博客的读者主要是有兴趣了解机器学习最新进展技术的专业人士。 |
| Statement | Provide a comprehensive overview of the most popular machine learning frameworks, including their strengths and weaknesses. Include real-life examples and case studies to illustrate how these frameworks have been successfully used in various industries.<br/>提供最流行的机器学习框架的全面概述,包括它们的优点和缺点。包括现实生活中的例子,和研究案例,以说明这些框架如何在各个行业中成功地被使用。 |
| Personality | When responding, use a mix of the writing styles of Andrej Karpathy, Francois Chollet, Jeremy Howard, and Yann LeCun.<br/>在回应时,混合使用 Andrej Karpathy、Francois Chollet、Jeremy Howard 和 Yann LeCun 的写作风格。 |
| Experiment | Give me multiple different examples.<br/>给我多个不同的例子。 |
2.Zero-Shot Prompting
在基础篇里的推理场景,我提到了 Zero-Shot Prompting 的技术,本章会详细介绍它是什么,以及使用它的技巧。Zero-Shot Prompting 是一种自然语言处理技术,可以让计算机模型根据提示或指令进行任务处理。各位常用的 ChatGPT 就用到这个技术。
传统的自然语言处理技术通常需要在大量标注数据上进行有监督的训练,以便模型可以对特定任务或领域进行准确的预测或生成输出。相比之下,Zero-Shot Prompting 的方法更为灵活和通用,因为它不需要针对每个新任务或领域都进行专门的训练。相反,它通过使用预先训练的语言模型和一些示例或提示,来帮助模型进行推理和生成输出。
举个例子,我们可以给 ChatGPT 一个简短的 prompt,比如 描述某部电影的故事情节,它就可以生成一个关于该情节的摘要,而不需要进行电影相关的专门训练。
2.1 Zero-Shot Prompting 缺点
但这个技术并不是没有缺点的:
- Zero-Shot Prompting 技术依赖于预训练的语言模型,这些模型可能会受到训练数据集的限制和偏见。比如在使用 ChatGPT 的时候,它常常会在一些投资领域,使用男性的「他」,而不是女性的「她」。那是因为训练 ChatGPT 的数据里,提到金融投资领域的内容,多为男性。
- 尽管 Zero-Shot Prompting 技术不需要为每个任务训练单独的模型,但为了获得最佳性能,它需要大量的样本数据进行微调。像 ChatGPT 就是一个例子,它的样本数量是过千亿。
- 由于 Zero-Shot Prompting 技术的灵活性和通用性,它的输出有时可能不够准确,或不符合预期。这可能需要对模型进行进一步的微调或添加更多的提示文本来纠正。
2.2 技巧 :Zero-Shot Chain of Thought
基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。
这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。
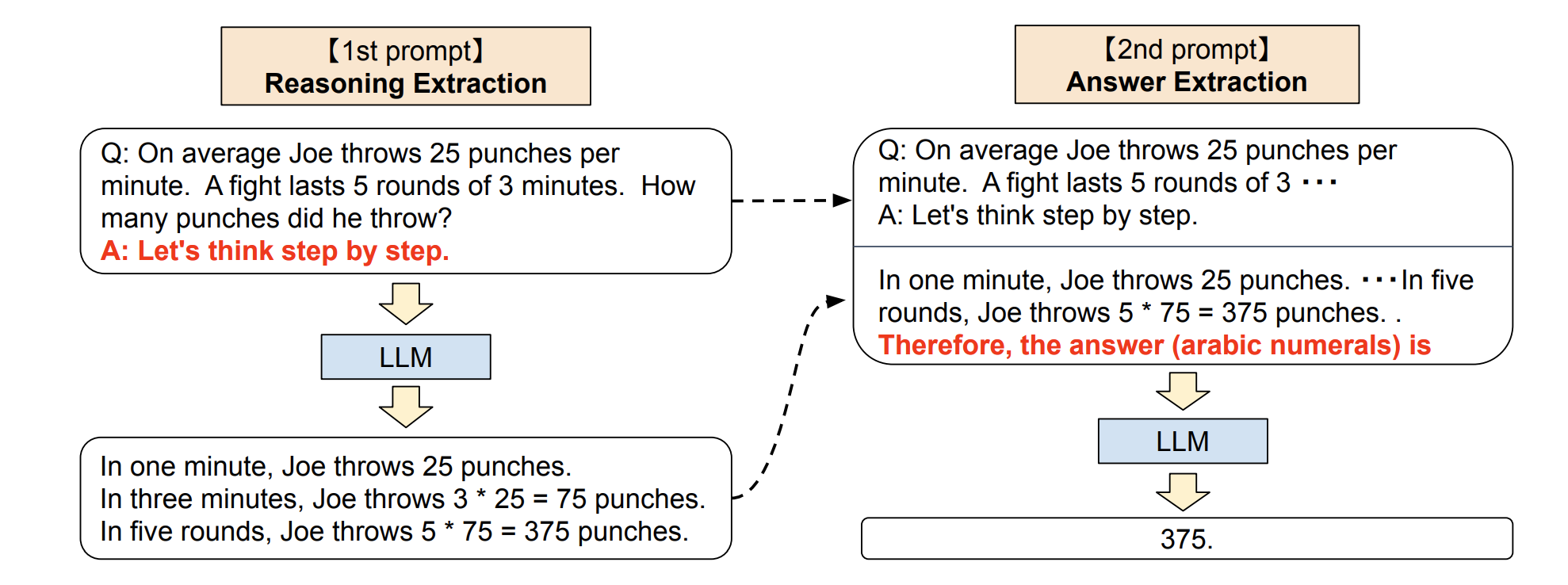
这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zero-Shot Reasoners。在论文里提到,当我们向模型提一个逻辑推理问题时,模型返回了一个错误的答案,但如果我们在问题最后加入 Let‘s think step by step 这句话之后,模型就生成了正确的答案:

论文里有讲到原因,感兴趣的朋友可以去看看,我简单解释下为什么(🆘 如果你有更好的解释,不妨反馈给我):
- 首先各位要清楚像 ChatGPT 这类产品,它是一个统计语言模型,本质上是基于过去看到过的所有数据,用统计学意义上的预测结果进行下一步的输出(这也就是为什么你在使用 ChatGPT 的时候,它的答案是一个字一个字地吐出来,而不是直接给你的原因,因为答案是一个字一个字算出来的)。
- 当它拿到的数据里有逻辑,它就会通过统计学的方法将这些逻辑找出来,并将这些逻辑呈现给你,让你感觉到它的回答很有逻辑。
- 在计算的过程中,模型会进行很多假设运算(不过暂时不知道它是怎么算的)。比如解决某个问题是从 A 到 B 再到 C,中间有很多假设。
- 它第一次算出来的答案错误的原因,只是因为它在中间跳过了一些步骤(B)。而让模型一步步地思考,则有助于其按照完整的逻辑链(A > B > C)去运算,而不会跳过某些假设,最后算出正确的答案。
按照论文里的解释,零样本思维链涉及两个补全结果,左侧气泡表示基于提示输出的第一次的结果,右侧气泡表示其收到了第一次结果后,将最开始的提示一起拿去运算,最后得出了正确的答案:
这个技巧,除了用于解决复杂问题外,还适合生成一些连贯主题的内容,比如写长篇文章、电影剧本等。
但需要注意其缺点,连贯不代表,它就一定不会算错,如果其中某一步骤算错了,错误会因为逻辑链,逐步将错误积累,导致生成的文本可能出现与预期不符的内容。
另外,根据 Wei 等人在 2022 年的论文表明,它仅在大于等于 100B 参数的模型中使用才会有效。如果你使用的是小样本模型,这个方法不会生效。
根据 Yongchao Zhou 等人的最新论文,更好的 prompt 是:
Let's work this out in a step by step way to be sure we have the right answer.在吴恩达的 ChatGPT Prompt Engineering 课程中,有提到一个这个技巧的另一种用法,不仅仅只是让 AI 按步骤行事,还会告知 AI 每一步要做什么。比如这个案例(注意这个是 python 代码):
prompt_2 = f"""
Your task is to perform the following actions:
1 - Summarize the following text delimited by
<> with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the
following keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in Italian summary>
Output JSON: <json with summary and num_names>
Text: <{text}>
"""简单解释下这个代码:
- 开头是让 AI 按照 1 ~ 4 步运行
- 然后再让 AI 根据特定格式输出内容
最后 AI 的输出是这样的:
Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed.
Translation: Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.
Names: Jack, Jill
Output JSON: {"french_summary": "Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2}上述的案例只是将任务拆解,能让 AI 生成的结果更加符合要求,这个方法同样能提升 AI 的回答准确性,比如这个案例:
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need help working out the financials.
Land costs $100 / square foot
I can buy solar panels for $250 / square foot
I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
Land cost: 100x
Solar panel cost: 250x
Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
AI 的回答是「The student's solution is correct」。但其实学生的答案是错误的,应该 360x + 100,000,我们将 prompt 调整成这样:
prompt = f"""
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
###
question here
###
Student's solution:
###
student's solution here
###
Actual solution:
###
steps to work out the solution and your solution here
###
Is the student's solution the same as actual solution \
just calculated:
###
yes or no
###
Student grade:
###
correct or incorrect
###
Question:
###
I'm building a solar power installation and I need help \
working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations \
as a function of the number of square feet.
###
Student's solution:
###
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
###
Actual solution:
"""本质上,也是将任务分拆成多步,这次 AI 输出的结果是这样的(结果就是正确的了):
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 10x
Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000
Is the student's solution the same as actual solution just calculated:
No
Student grade:
Incorrect下一章我们会结合 Few-Shot Chain of Thought 来详细讲讲逻辑链的限制。
3. Few-Shot Prompting
我们在技巧2 中,提到我们可以给模型一些示例,从而让模型返回更符合我们需求的答案。这个技巧其实使用了一个叫 Few-Shot 的方法。
这个方法最早是 Brown 等人在 2020 年发现的,论文里有一个这样的例子,非常有意思,通过这个例子你应该更能体会,像 ChatGPT 这类统计语言模型,其实并不懂意思,只是懂概率
Brown 输入的内容是这样的(whatpu 和 farduddle 其实根本不存在):
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses
the word whatpu is:
We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses
the word farduddle is:Output 是这样的:
When we won the game, we all started to farduddle in celebration.不过这并不代表,Few-Shot 就没有缺陷,我们试试下面这个例子:
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:Output 是这样的:
The answer is True.输出的答案其实是错误的,实际上的答案应该是:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.那我们有没有什么方法解决?
技巧8:Few-Shot Chain of Thought
要解决这个缺陷,就要使用到新的技巧,Few-Shot Chain of Thought。
根据 Wei 他们团队在 2022 年的研究表明:
通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
下面是论文里的案例,使用方法很简单,在技巧2 的基础上,再将逻辑过程告知给模型即可。从下面这个案例里,你可以看到加入解释后,输出的结果就正确了。
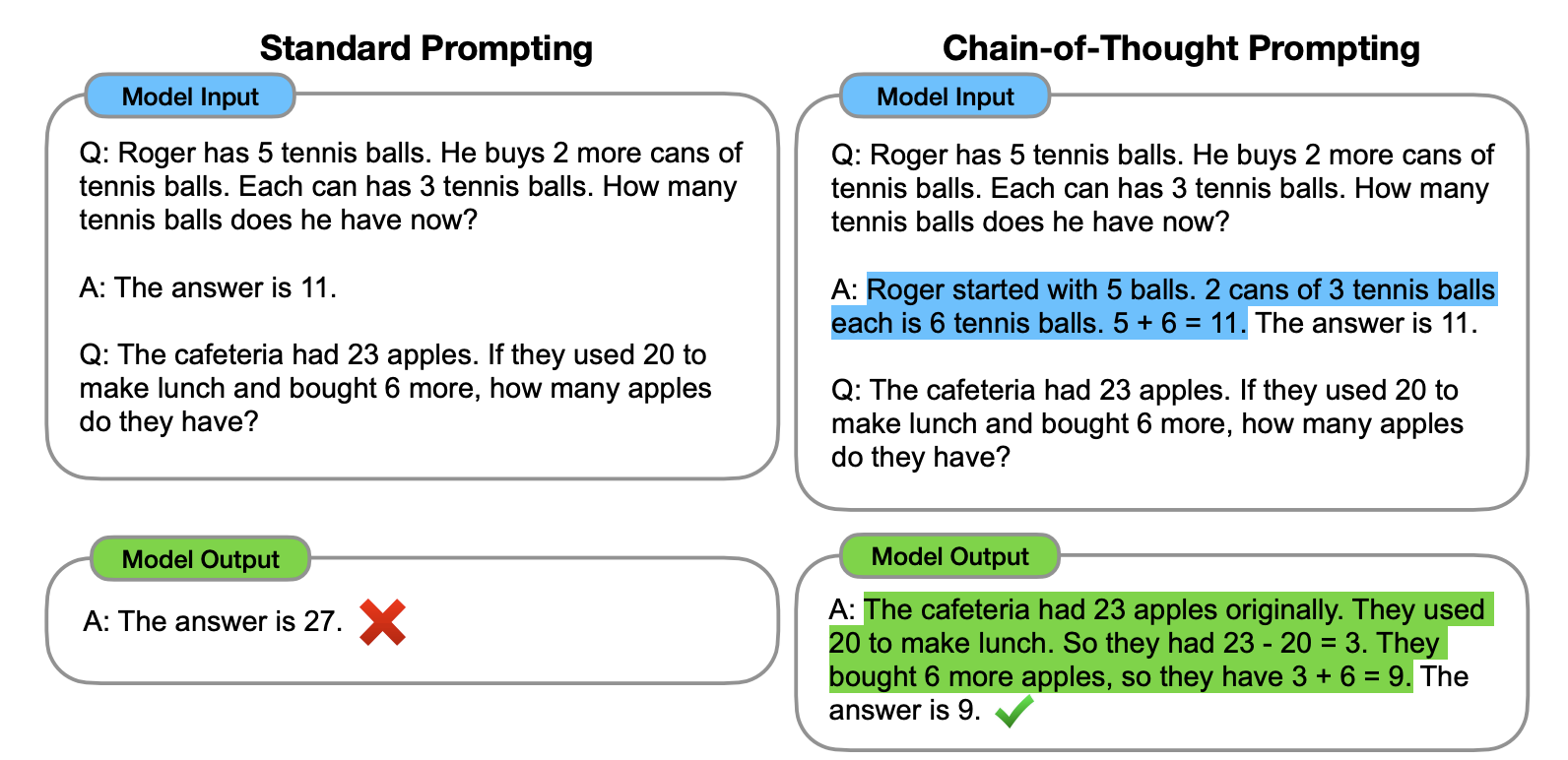
那本章开头提的例子就应该是这样的(注:本例子同样来自 Wei 团队论文):
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:聊完技巧,我们再结合前面的 Zero-Shot Chain of Thought,来聊聊 Chain of Thought 的关键知识。根据 Sewon Min 等人在 2022 年的研究 表明,思维链有以下特点:
- "the label space and the distribution of the input text specified by the demonstrations are both key (regardless of whether the labels are correct for individual inputs)" 标签空间和输入文本的分布都是关键因素(无论这些标签是否正确)。
- the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all. 即使只是使用随机标签,使用适当的格式也能提高性能。
理解起来有点难,我找一个 prompt 案例给大家解释(🆘 如果你有更好的解释,不妨反馈给我)。我给 ChatGPT 一些不一定准确的例子:
I loved the new Batman movie! // Negative
This is bad // Positive
This is good // Negative
What a good show! //Output 是这样的:
Positive在上述的案例里,每一行,我都写了一句话和一个情感词,并用 // 分开,但我给这些句子都标记了错误的答案,比如第一句其实应该是 Positive 才对。但:
- 即使我给内容打的标签是错误的(比如第一句话,其实应该是 Positive),对于模型来说,它仍然会知道需要输出什么东西。 换句话说,模型知道 // 划线后要输出一个衡量该句子表达何种感情的词(Positive or Negative)。这就是前面论文里 #1 提到的,即使我给的标签是错误的,或者换句话说,是否基于事实,并不重要。标签和输入的文本,以及格式才是关键因素。
- 只要给了示例,即使随机的标签,对于模型生成结果来说,都是有帮助的。这就是前面论文里 #2 提到的内容。
最后,需要记住,思维链仅在使用大于等于 100B 参数的模型时,才会生效。
BTW,如果你想要了解更多相关信息,可以看看斯坦福大学的讲义:Natural Language Processing with Deep Learning
4. Self-Consistency
elf-Consistency 自洽是对 Chain of Thought 的一个补充,它能让模型生成多个思维链,然后取最多数答案的作为最终结果。
按照 Xuezhi Wang 等人在 2022 年发表的论文 表明。当我们只用一个逻辑链进行优化时,模型依然有可能会算错,所以 XueZhi Wang 等人提出了一种新的方法,让模型进行多次运算,然后选取最多的答案作为最终结果:
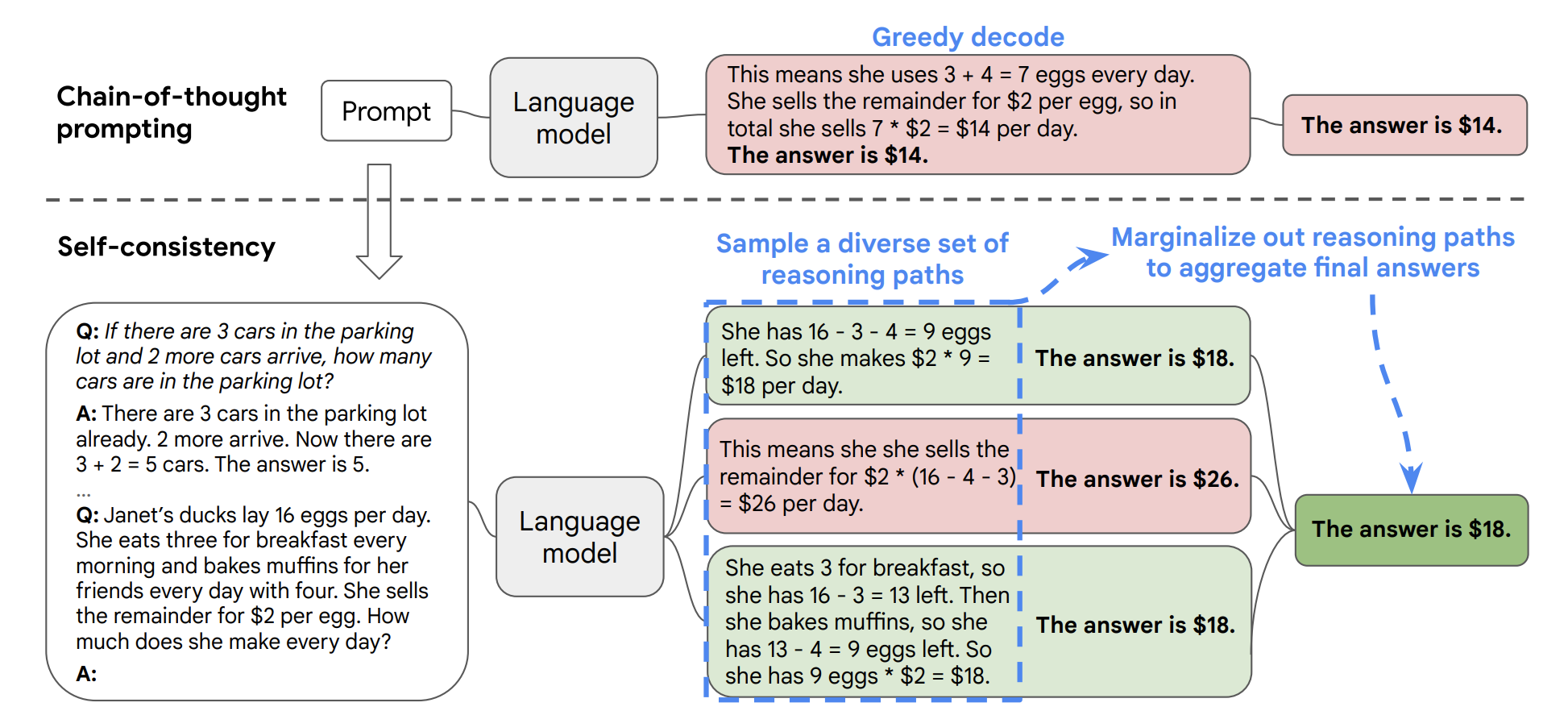
就我目前使用下来,在 ChatGPT 上,其自洽性非常高,暂时没有遇到过出现多种答案的情况。查阅多份资料,我发现这个自洽性可能更多的用于评估模型的优劣,好的模型一般自洽性会比较高。
在此案例中,考虑如下多步推理问题:
Consider a multi-step reasoning problem like the following:
Question: If a store has 10 apples and 8 oranges, and it sells 6 apples and 4 oranges, how many fruits are left in the store?
Instead of directly answering the question, the chain-of-thought prompting would require the language model to produce a series of short sentences that mimic a human's reasoning process:
The store has 10 apples.
The store has 8 oranges.
6 apples are sold.
4 oranges are sold.
There are 10 - 6 = 4 apples left.
There are 8 - 4 = 4 oranges left.
The store now has 4 apples + 4 oranges = 8 fruits.
Using self-consistency, the language model generates multiple reasoning paths:
Reasoning Path A:
The store has 10 apples.
The store has 8 oranges.
6 apples are sold.
4 oranges are sold.
There are 10 - 6 = 4 apples left.
There are 8 - 4 = 4 oranges left.
The store now has 4 apples + 4 oranges = 8 fruits.
Reasoning Path B:
The store initially has 10 apples and 8 oranges.
It sells 6 apples, so there are 10 - 6 = 4 apples left.
It sells 4 oranges, so there are 8 - 4 = 4 oranges left.
The store now has 4 apples + 4 oranges = 8 fruits.翻译过来则为:
问题:如果一家商店有 10 个苹果和 8 个橙子,此时店里卖出了 6 个苹果和 4 个橙子,那么店里还剩下多少水果?
思维链提示(chain-of-thought prompting)不是直接回答问题,而是要求语言模型生成一系列模仿人类推理过程的短句:
商店有 10 个苹果。
店里有 8 个橙子。
卖了 6 个苹果。
卖了 4 个橙子。
还剩下 10 - 6 = 4 个苹果。
剩下 8 - 4 = 4 个橙子。
商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。使用 Self-consistency,语言模型生成多个推理路径:
推理路径A:
商店有 10 个苹果。
店里有 8 个橙子。
卖了 6 个苹果。
卖了 4 个橙子。
还剩下 10 - 6 = 4 个苹果。
剩下 8 - 4 = 4 个橙子。
商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。
推理路径 B:
商店最初有 10 个苹果和 8 个橙子。
商店卖了 6 个苹果,所以还剩下 10 - 6 = 4 个苹果。
商店卖了 4 个橙子,所以还剩下 8 - 4 = 4 个橙子。
商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。Self-consistency 从生成的多个推理路径中选择最一致的答案。在这个例子中,推理路径 A 和 B 都得出相同的答案(8 个水果)。可以看到这种做法增加了模型对最终答案正确的信心。
5. Program-Aided Language Models
PAL Models,全称为 Program-Aided Language Models。需要各位注意,这个方法,真的非常高级,甚至我觉得有点 Hack,而且经过我的多次测试,我觉得以 ChatGPT 目前的能力,已经不再需要使用这个方法。
但我在很多 PE 的教程里都有看到这个方法,所以我这里就简单介绍一下,这个方法来自于 2022 年,Luyu Gao 等人的研究,根据他们的研究,在 LLM 模型中,即使使用了前面提到的 Chain of Thought 的方法,也未必能拿到答案,论文中使用的 prompt 是这样的:
Q: Roger has 5 tennis balls. He buys 2 more cans of
tennis balls. Each can has 3 tennis balls. How many
tennis balls does he have now?
A: Roger started with 5 tennis balls. 2 cans of 3 tennis
balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The bakers at the Beverly Hills Bakery baked 200
loaves of bread on Monday morning. They sold 93 loaves
in the morning and 39 loaves in the afternoon. A grocery
store returned 6 unsold loaves. How many loaves of
bread did they have left?论文里提到,当年他们的模型的 Output 是这样的:
A: The bakers started with 200 loaves. They sold 93 in
the morning and 39 in the afternoon. So they sold 93 +
39 = 132 loaves. The grocery store returned 6 loaves. So
they had 200 - 132 - 6 = 62 loaves left.
The answer is 62.如果你现在将这个 prompt 输入到最新的 ChatGPT 答案已经是正确的:
A: The bakers baked 200 loaves of bread. They sold 93 + 39 = 132 loaves. After the grocery store returned 6 unsold loaves, the bakery had 200 - 132 + 6 = 74 loaves of bread left. The answer is 74.当年 Luyu Gao 的解决方法是在 prompt 里引入代码,并引导模型使用代码来运算和思考,最后答案就是正确的:

6.OpenAI Playground 使用方法
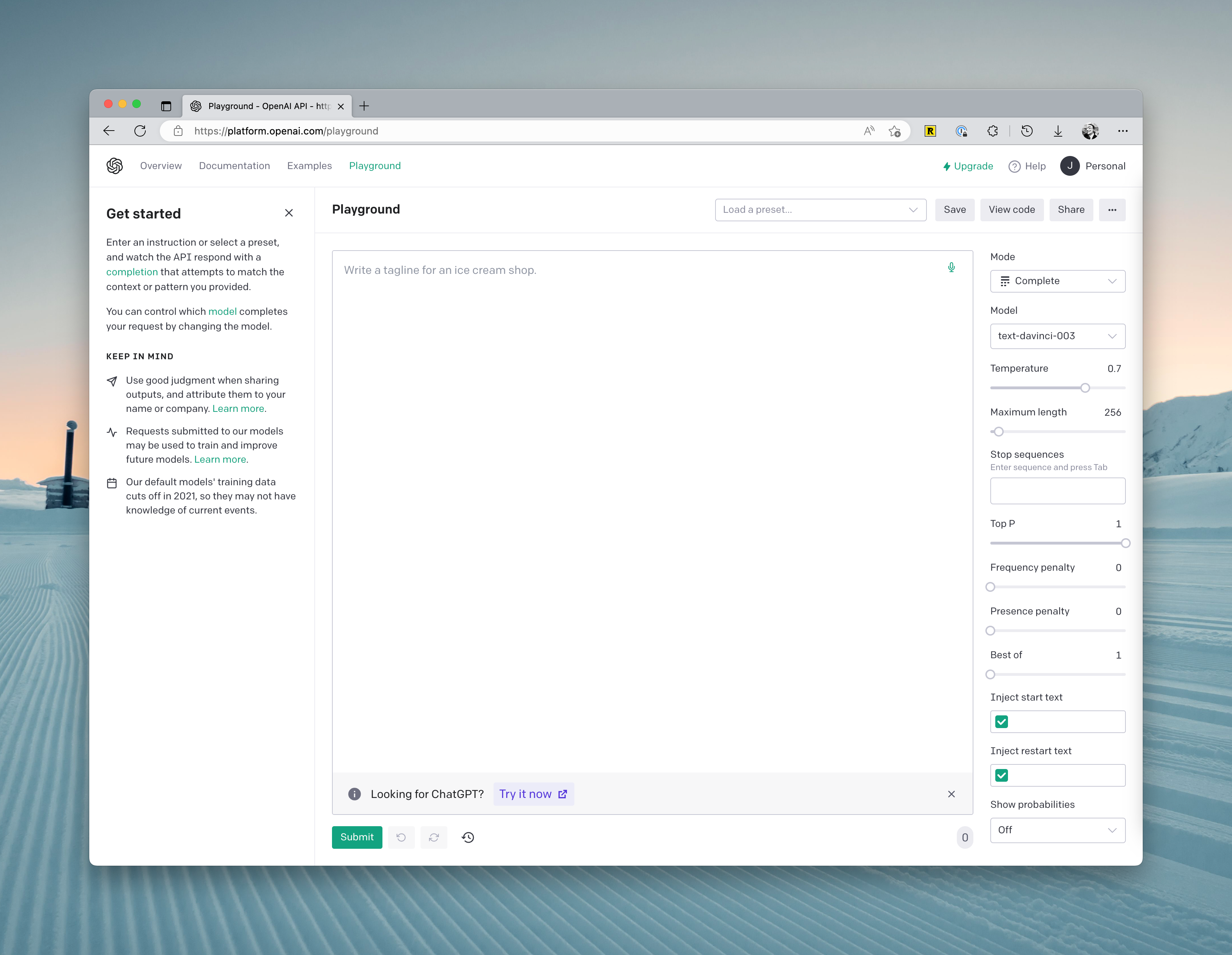
你会在界面的右侧看到以下几个参数:
- Mode: 最近更新了第四种 Chat 模式,一般使用 Complete 就好,当然你可以用其他模式,其他模式能通过 GUI 的方式辅助你撰写 prompt。
Model: 这里可以切换模型。不同的模型会擅长不同的东西,根据场景选对模型,能让你省很多成本:
- Ada:这是最便宜,但运算速度最快的模型。官方推荐的使用场景是解析文本,简单分类,地址更正等。
- Babbage:这个模型能处理比 Ada 复杂的场景。但稍微贵一些,速度也比较快。适合分类,语义搜索等。
- Curie:这个模型官方解释是「和 Davinci 一样能力很强,且更便宜的模型」。但实际上,这个模型非常擅长文字类的任务,比如写文章、语言翻译、撰写总结等。
- Davinci:这是 GPT-3 系列模型中能力最强的模型。可以输出更高的质量、更长的回答。每次请求可处理 4000 个 token。适合有复杂意图、因果关系的场景,还有创意生成、搜索、段落总结等。
- Temperature: 这个主要是控制模型生成结果的随机性。简而言之,温度越低,结果越确定,但也会越平凡或无趣。如果你想要得到一些出人意料的回答,不妨将这个参数调高一些。但如果你的场景是基于事实的场景,比如数据提取、FAQ 场景,此参数就最好调成 0 。
- Maximum length: 设置单次生成内容的最大长度。
- Stop Sequence: 该选项设置停止生成文本的特定字符串序列。如果生成文本中包含此序列,则模型将停止生成更多文本。
- Top P: 该选项是用于 nucleus 采样的一种技术,它可以控制模型生成文本的概率分布,从而影响模型生成文本的多样性和确定性。如果你想要准确的答案,可以将它设定为较低的值。如果你想要更多样化的回复,可以将其设得高一些。
- Presence Penalty: 该选项控制模型生成文本时是否避免使用特定单词或短语,它可以用于生成文本的敏感话题或特定场景。
- Best of: 这个选项允许你设置生成多少个文本后,从中选择最优秀的文本作为输出。默认为1,表示只生成一个文本输出。
- Injection start text: 这个选项可以让你在输入文本的开头添加自定义文本,从而影响模型的生成结果。
- Injection restart text: 这个选项可以让你在中间某个位置添加自定义文本,从而影响模型继续生成的结果。
- Show probabilities: 这个选项可以让你查看模型生成每个单词的概率。打开此选项后,你可以看到每个生成的文本单词后面跟着一串数字,表示模型生成该单词的概率大小。
配置好参数后,你就可以在左侧输入 prompt 然后测试 prompt 了。
7.搭建基于知识库内容的机器人
<head>
<script defer="defer" src="https://embed.trydyno.com/embedder.js"></script>
<link href="https://embed.trydyno.com/embedder.css" rel="stylesheet" />
</head>
如果你仅想要直接实践,可以看最后一部分实践,以及倒数第二部分限制与注意的地方。
最早的时候,我尝试过非常笨的方法,就是在提问的时候,将我的 newsletter 文本传给 AI,它的 prompt 大概是这样的:
Please summarize the following sentences to make them easier to understand.
Text: """
My newsletter
"""这个方法能用是能用,但目前 ChatGPT 有个非常大的限制,它限制了最大的 token 数是 4096,大约是 16000 多个字符,注意这个是请求 + 响应,实际请求总数并没那么多。换句话来说,我一次没法导入太多的内容给 ChatGPT(我的一篇 Newsletter 就有将近 5000 字),这个问题就一直卡了我很久,直到我看到了 GPT Index 的库,以及 Lennys Newsletter 的例子。
试了下,非常好用,而且步骤也很简单,即使你不懂编程也能轻易地按照步骤实现这个功能。
我稍稍优化了下例子的代码,并增加了一些原理介绍。希望大家能喜欢。
7.1 原理介绍
其实我这个需求,在传统的机器人领域已经有现成方法,比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。
这种传统的机器人,通常是基于意图去回答人的问题。举个例子,我们构建了一个客服机器人,它的工作原理简单说来是这样的:
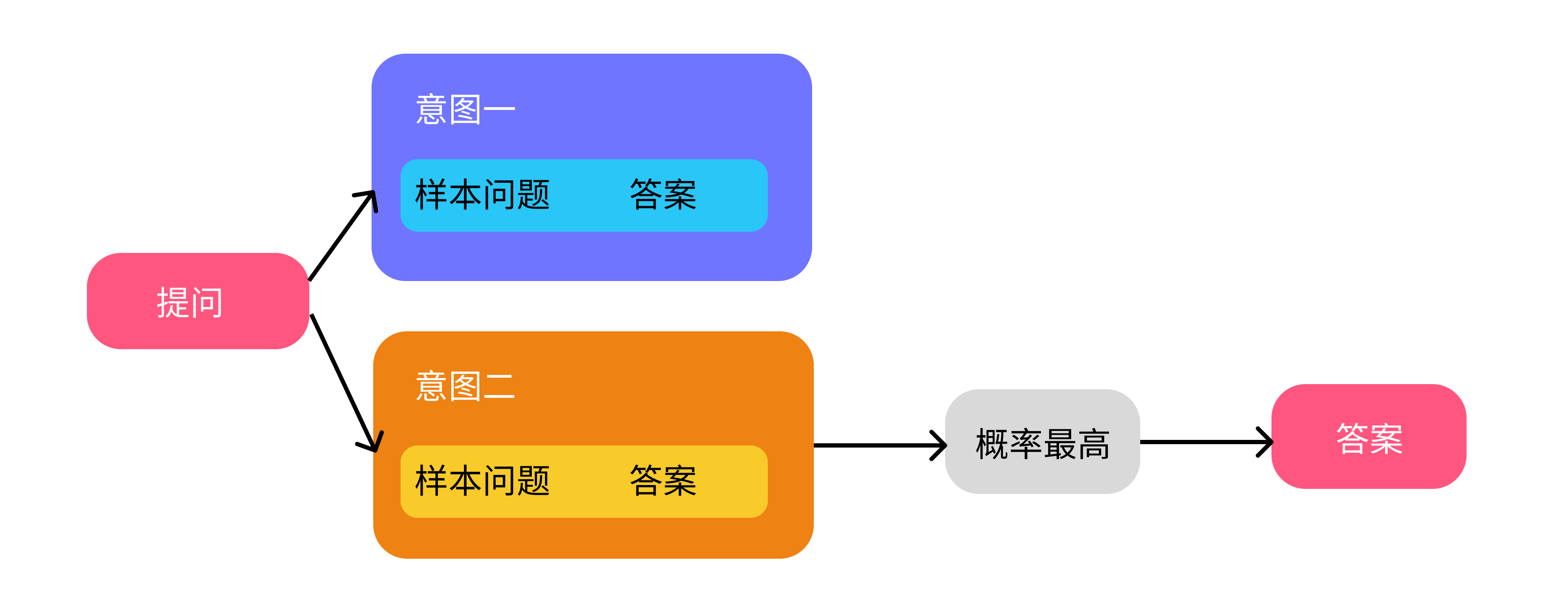
当用户问「忘记密码怎么办?」时,它会去找最接近这个意图「密码」,每个意图里会有很多个样本问题,比如「忘记密码如何找回」「忘记密码怎么办」,然后这些样本问题都会有个答案「点击 A 按钮找回密码」,机器人会匹配最接近样本问题的意图,然后返回答案。
但这样有个问题,我们需要设置特别多的意图,比如「无法登录」、「忘记密码」、「登录错误」,虽然有可能都在描述一个事情,但我们需要设置三个意图、三组问题和答案。
虽然传统的机器人有不少限制,但这种传统方式,给了我们一些灵感。
我们好像可以用这个方法来解决限制 token 的问题,我们仅需要传符合某个意图的文档给 AI,然后 AI 仅用该文档来生成答案:
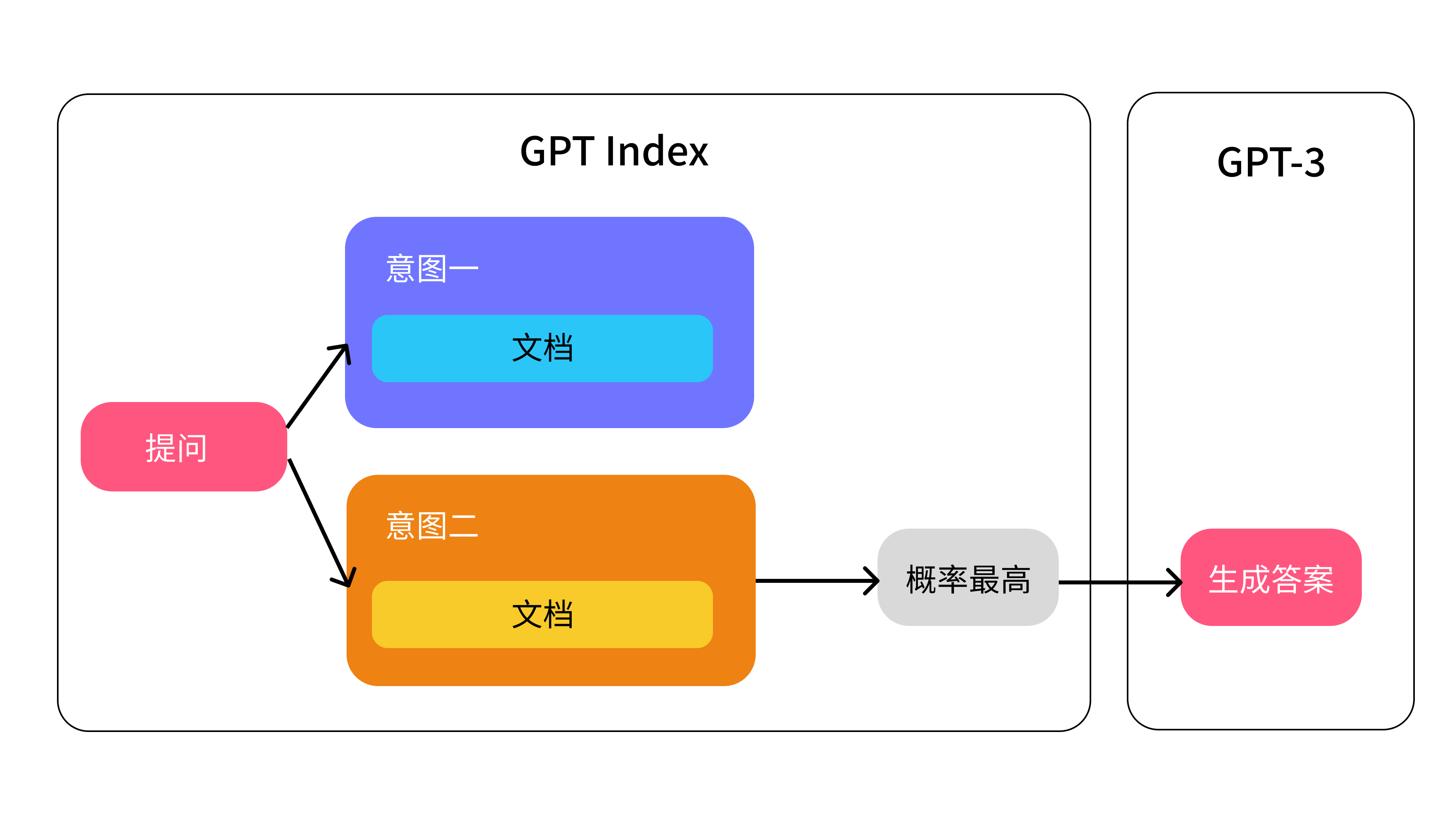
比如还是上面的那个客服机器人的例子,当用户提问「忘记密码怎么办?」时,匹配到了「登录」相关的意图,接着匹配知识库中相同或相近意图的文档,比如「登录异常处理解决方案文档」,最后我们将这份文档传给 GPT-3,它再拿这个文档内容生成答案。
GPTIndex 这个库简单理解就是做上图左边的那个部分,它的工作原理是这这样的:
- 创建知识库或文档索引
- 找到最相关的索引
- 最后将对应索引的内容给 GPT-3
虽然这个方法解决了 token 限制的问题,但也有不少限制:
- 当用户提一些比较模糊的问题时,匹配有可能错误,导致 GPT-3 拿到了错误的内容,最终生成了非常离谱的答案。
- 当用户提问一些没有多少上下文的信息时,机器人有时会生成虚假信息。
所以如果你想用这个技术做客服机器人,建议你:
- 通过一些引导问题来先明确用户的意图,就是类似传统客服机器人那样,搞几个按钮,先让用户点击(比如无法登录)。
- 如果相似度太低,建议增加兜底的回答「很抱歉,我无法回答你的问题,你需要转为人工客服吗?」
7.2 实践
为了让大家更方便使用,我将代码放在了 Google Colab,你无需安装任何环境,只需要用浏览器打开这个:
BTW 你可以将其复制保存到自己的 Google Drive。
第一步:导入数据
导入的方法有两种,第一种是导入在线数据。
导入 GitHub 数据是个相对简单的方式。如果你是第一次使用,我建议你先用这个方法试试。点击下方代码前的播放按钮,就会运行这段代码。

运行完成后,会导入我写的几份 newsletter。如果你也想像我那样导入数据,只需要修改 clone 后面的链接地址即可。
第二种方法是导入离线数据。点击左侧的文件夹按钮(如果你没有登录,这一步会让你登录),然后点击下图标识 2 的上传按钮,上传文件即可。如果你要传多个文件,建议你先建一个文件夹,然后将文件都上传到该文件夹内。
第二 & 三步:安装依赖库
直接点击播放按钮即可。
不过第三步里,你可以尝试改下参数,你可以改:
- num_ouputs :这个是设置最大的输出 token 数,越大,回答问题的时候,机器能回答的字就越多。
- Temperature: 这个主要是控制模型生成结果的随机性。简而言之,温度越低,结果越确定,但也会越平凡或无趣。如果你想要得到一些出人意料的回答,不妨将这个参数调高一些。但如果你的场景是基于事实的场景,比如数据提取、FAQ 场景,此参数就最好调成 0。
其他参数不去管它就好,问题不大。
第四步:设置 OpenAI API Key
这个需要你登录 OpenAI(注意是 OpenAI 不是 ChatGPT),点击右上角的头像,点击 View API Keys,或者你点击这个链接也可以直接访问。然后点击「Create New Secret Key」,然后复制那个 Key 并粘贴到文档里即可。
第五步:构建索引
这一步程序会将第一步导入的数据都跑一遍,并使用 OpenAI 的 embedings API。如果第一步你上传了自己的数据,只需要将 ' ' 里的 Jimmy-Newsletter-Corpus 修改为你上传的文件夹名称即可。
注意:
- 这一步会耗费你的 OpenAI 的 Credit,1000 个 token 的价格是 $0.02,运行以下代码前需要注意你的账号里是否还有钱。
- 如果你用的 OpenAI 账号是个免费账号,你有可能会遇到频率警告,此时可以等一等再运行下方代码(另外你的导入的知识库数据太多,也会触发)。解除这个限制,最好的方式是在你的 OpenAI 账号的 Billing 页面里绑定信用卡。如何绑卡,需要各位自行搜索。
第六步:提问
这一步你就可以试试提问了,如果你在第一步导入的是我预设的数据,你可以试试问以下问题:
- Issue 90 主要讲了什么什么内容?
- 推荐一本跟 Issue 90 里提到的书类似的书
如果你导入的是自己的资料,也可以问以下几个类型的问题:
- 总结
- 提问
- 信息提取

