

近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO 扮演着核心角色。本文将深入探讨 PPO 的基本原理和实现细节。
PPO 属于在线策略梯度方法的范畴。其基础形式可以用带有优势函数的策略梯度表达式来描述:
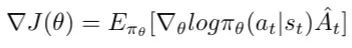
策略梯度的基础表达式(包含优势函数)。
这个表达式实际上构成了优势演员-评论家(Advantage Actor-Critic)方法的基础目标函数。PPO 算法可以视为对该方法的一种改进和优化。
PPO 算法的损失函数设计
PPO 通过引入策略更新约束机制来提升训练稳定性。这种机制很好地平衡了更新幅度:过大的策略更新可能导致训练偏离优化方向,而过小的更新则可能降低训练效率。为此,PPO 采用了一个特殊的替代目标函数,该函数由裁剪项和非裁剪项组成,并取两者的最小值。
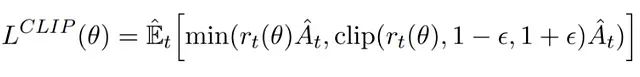
PPO 的损失函数结构。
替代损失函数的非裁剪部分分析
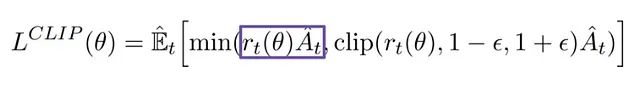
损失函数中的非裁剪部分示意图。
在 PPO 中,比率函数定义为在状态 st 下执行动作 at 时,当前策略与旧策略的概率比值。
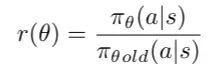
策略概率比率 r(θ)的定义。
这个比率函数 r(θ)为我们提供了一个度量新旧策略差异的有效工具,它可以替代传统策略梯度目标函数中的对数概率项。非裁剪部分的损失通过将此比率与优势函数相乘得到。
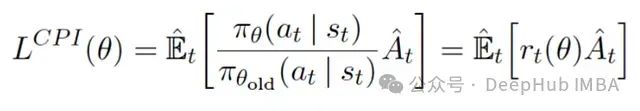
非裁剪部分损失计算示意图。
替代损失函数的裁剪机制
为了防止过大的策略更新,PPO 引入了裁剪机制,将策略比率 r(θ)限制在[1-ϵ, 1+ϵ]的区间内。其中 ϵ 是一个重要的超参数,在 PPO 的原始论文中设定为 0.2。这样,我们可以得到完整的 PPO 目标函数:
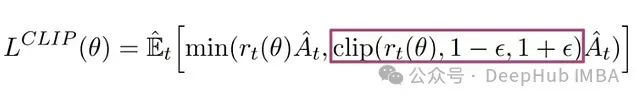
PPO 完整目标函数,包含非裁剪项和裁剪项。
PPO 的最终优化目标是在这两部分中取较小值,从而实现稳定的策略优化。
算法实现流程
1. 系统初始化
a. 设置随机种子
b. 初始化演员网络与评论家网络的优化器
c. 配置损失追踪器和奖励记录器
d. 加载超参数配置
2. 训练回合迭代
a. 环境重置
b. 回合内循环:
i. 通过演员网络预测动作概率分布并采样
ii. 记录动作的对数概率(作为old policy的参考)
iii. 执行环境交互,获取转移数据
c. 计算衰减回报
d. 存储回合经验数据
e. 按更新频率执行网络优化:
i. 评估状态价值
ii. 计算优势估计
iii. 构建PPO损失函数
iv. 执行梯度优化
3. 训练监控
a. 记录并可视化平均损失指标PyTorch 实现详解
1、初始化**
torch.manual_seed(self.cfg['train']['random_seed'])
actor_optim = optim.Adam(self.actor.parameters(), lr=self.cfg['train']['lr'], betas=self.cfg['train']['betas'])
critic_optim = optim.Adam(self.critic.parameters(), lr=self.cfg['train']['lr'], betas=self.cfg['train']['betas'])
avg_actor_losses = []
avg_critic_losses = []
actor_losses = []
critic_losses = []
eps = np.finfo(np.float32).eps.item()
batch_data = []2、回合循环
2.1 重置环境
for episode in range(self.cfg['train']['n_epidode']):
rewards = []
log_probs = []
actions = []
states = []
state_values = []
self.actor.train()
self.critic.train()
terminated, truncated = False, False ## 初始化终止和截断标志
state, info = self.env.reset()
## 转换为张量
state = torch.FloatTensor(state).to(self.device)2.2 当回合未结束时:
timesteps = 0
## 遍历时间步
while not terminated and not truncated:
timesteps += 1演员预测动作概率并从分布中采样动作。
## 演员层输出动作概率,因为演员神经网络在输出层有softmax
action_prob = self.actor(state)
## 我们知道我们不直接使用分类交叉熵损失函数,而是手动构建以获得更多控制。
## PyTorch中的分类交叉熵损失函数使用softmax将logits转换为概率到分类分布,
## 然后计算损失。所以通常不需要显式地将softmax函数添加到神经网络中。在这项工作中,
## 我们在神经网络上添加softmax层并计算分类分布。
## categorical函数可以从softmax概率或从logits(输出中没有softmax层)生成分类分布,
## 将logits作为属性
action_dist= Categorical(action_prob)
## 采样动作
action = action_dist.sample()
actions.append(action)获取对数概率,这被视为比率的 log pi_theta_old
## 获取对数概率以得到log pi_theta_old(a|s)并保存到列表中
log_probs.append(action_dist.log_prob(action))在环境中执行动作,获取下一个状态、奖励和终止标志。
## 动作必须从张量转换为numpy以供环境处理
next_state, reward, terminated, truncated, info = self.env.step(action.item())
rewards.append(reward)
## 将下一个状态分配为当前状态
state = torch.FloatTensor(next_state).to(self.device)2.3 计算折扣回报
R = 0
returns = [] ## 用于保存真实值的列表
## 使用环境在回合中返回的奖励计算每个回合的回报
for r in rewards[::-1]:
## 计算折扣值
R = r + self.cfg['train']['gamma'] * R
returns.insert(0, R)
returns = torch.tensor(returns).to(self.device)
returns = (returns - returns.mean()) / (returns.std() + eps)2.4 将每个回合的经验存储在 batch_data 中
## 存储数据
batch_data.append([states, actions, returns, log_probs, state_values])2.5 每 update_freq 回合更新网络:
if episode != 0 and episode%self.cfg['train']['update_freq'] == 0:
## 这是我们更新网络一些n个epoch的循环。这个额外的for循环
## 改善了训练效果
for _ in range(5):
for states_b, actions_b, returns_b, old_log_probs, old_state_values in batch_data:
## 将列表转换为张量
old_states = torch.stack(states_b, dim=0).detach()
old_actions = torch.stack(actions_b, dim=0).detach()
old_log_probs = torch.stack(old_log_probs, dim=0).detach()计算状态值
state_values = self.critic(old_states)计算优势。
## 计算优势
advantages = returns_b.detach() - state_values.detach()
## 规范化优势在理论上不是必需的,但在实践中它降低了我们优势的方差,
## 使收敛更加稳定和快速。我添加这个是因为
## 解决一些环境问题如果没有它会太不稳定。
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-10)计算演员和评论家的 PPO 损失。
## 现在我们需要计算比率(pi_theta / pi_theta__old)。为了做到这一点,
## 我们需要从存储的状态中获取所采取动作的旧策略,并计算相同动作的新策略
## 演员层输出动作概率,因为演员神经网络在输出层有softmax
action_probs = self.actor(old_states)
dist = Categorical(action_probs)
new_log_probs = dist.log_prob(old_actions)
## 因为我们取对数,所以我们可以用减法代替除法。然后取指数将得到与除法相同的结果
ratios = torch.exp(new_log_probs - old_log_probs)
## 替代损失函数的非裁剪部分
surr1 = ratios * advantages
## 替代损失函数的裁剪部分
surr2 = torch.clamp(ratios, 1 - self.cfg['train']['clip_param'], 1 + self.cfg['train']['clip_param']) * advantages
## 更新演员网络:loss = min(surr1, surr2)
actor_loss = -torch.min(surr1, surr2).mean()
actor_losses.append(actor_loss.item())
## 使用Huber损失计算评论家(价值)损失
## Huber损失对数据中的异常值比平方误差损失更不敏感。在基于价值的RL设置中,
## 推荐使用Huber损失。
## Smooth L1损失与HuberLoss密切相关
critic_loss = F.smooth_l1_loss(state_values, returns_b.unsqueeze(1)) #F.huber_loss(state_value, torch.tensor([R]))
critic_losses.append(critic_loss.item())使用梯度下降更新网络
actor_optim.zero_grad()
critic_optim.zero_grad()
## 执行反向传播
actor_loss.backward()
critic_loss.backward()
## 执行优化
actor_optim.step()
critic_optim.step()完整代码
https://avoid.overfit.cn/post/ff4d892c414a4b9c9391a1812690eceb

