AI for Science 作为科学发现的「第五范式」, 正在开创一场全新的科研革命,在材料化学领域,这场变革尤为显著。

Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 →Apache TVM 是一个端...

美国国家工程院外籍院士沈向洋曾强调:「如果说今天有什么事是我们一定要做的,那就是 AI for Science。难以想象今天还有什么事情比它更...

在地球科学研究中,地表热流 (Surface Heat Flow, SHF) 作为地球深层热能释放的重要表征,一直备受关注。地表热流不仅是地球内部能量驱...

AlphaFold2 自发布以来就在 AI4S 领域引起轰动,更拿下了今年的诺贝尔奖。AlphaFold3 作为其升级版,不仅能够预测蛋白质的结构,还能够...

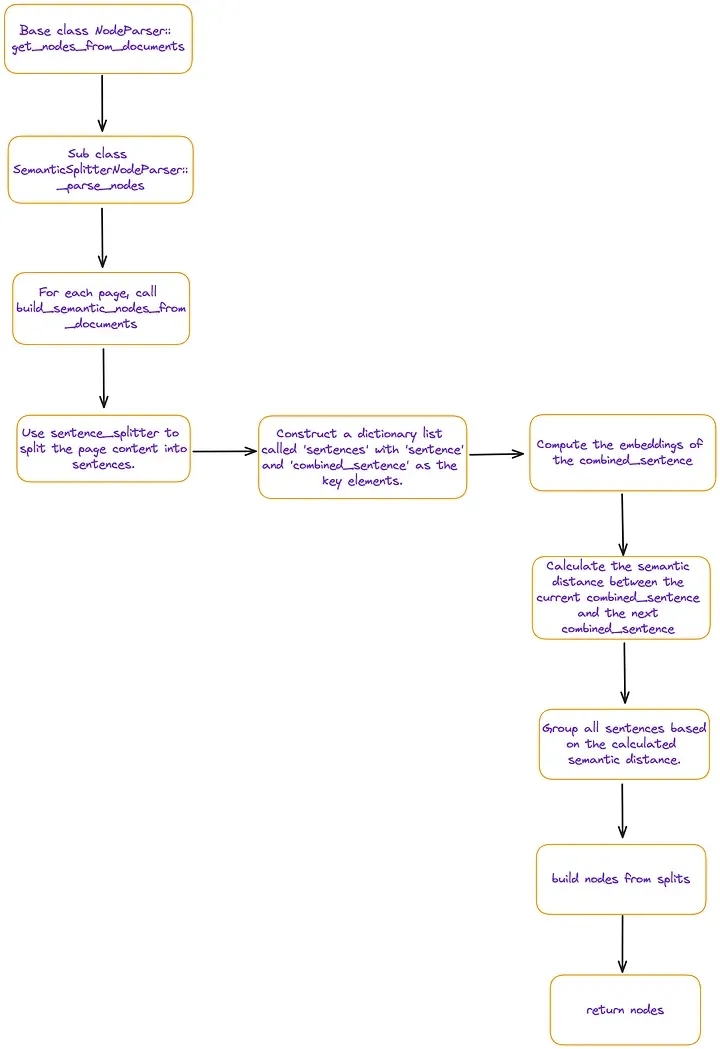
大多数常用的数据分块方法(chunking)都是基于规则的,采用 fixed chunk size(译者注:将数据或文本按照固定的大小进行数据分块)或 o...
Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 →Apache TVM 是一个端...
「Meet AI4S」系列直播第五期将于今晚 19:00 准时开播,HyperAI超神经有幸邀请到了浙江大学知识引擎实验室的博士研究生王泽元,他本次分...

「7 月份新能源汽车国内零售渗透率达 51.1%,比原定计划提前了 11 年」。 这是中国汽车流通协会乘用车市场信息联席分会于今年 8 月份发...

近年来,高熵材料 (HEMs) 在材料设计和功能控制领域展现出巨大的潜力。其中,高熵氧化物 (HEOs) 由于丰富的活性位点、可调节的比表面积...

Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → Apache TVM 是一个...
设想你正致力于构建一个智能问答系统,该系统旨在从庞大的知识库中迅速而精确地提取关键信息,并据此生成自然流畅的回答。然而,随着数...

大型语言模型 (LLM) 如 GPT-4 彻底革新了自然语言处理 (NLP) 领域,在生成类人文本、回答问题和执行各种语言相关任务方面展现出卓越的能...

Text Embedding 榜单:MTEB、C-MTEB 《MTEB: Massive Text Embedding Benchmark(海量文本嵌入基准)》 判断哪些文本嵌入模型效果较好,通...

Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU ...

[【ChatGLM2-6B 入门】清华大学开源中文版 ChatGLM-6B 模型学习与实战]论文名称:ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语...

检索增强生成 (RAG) 是一种强大的技术,它将信息检索与生成式 AI 相结合,以产生更准确、上下文更丰富的响应。本文将探讨 15 种高级 R...

Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → [链接]

在当今社会的快节奏生活下,人们对于心理健康的关注度也在持续提升。然而,如今的心理健康医疗资源明显不足,尤其是在低收入和中等收入...

在当今数字化进程飞速发展的时代,OCR(光学字符识别)技术虽已普及,但仍存在诸多瓶颈。传统 OCR 模型在面对复杂多变的情况时,识别准...






