Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → [链接]

Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU ...

Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → [链接]

Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU ...
Apache TVM 是一个端到端的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 → [链接]
arXiv上面看到的综述“The Deep Learning Compiler: A Comprehensive Survey([链接])”,2020年2月上传第一版,4月已经是第三版。
围绕GPU硬件上的低精度算子开展了一系列优化工作,以充分发掘NV新硬件提供的以TensorCore为代表的专用硬件加速单元的计算效率。

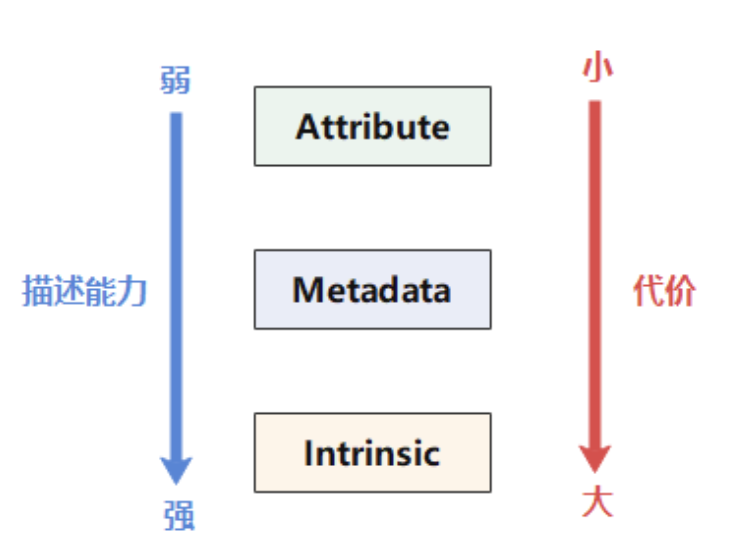
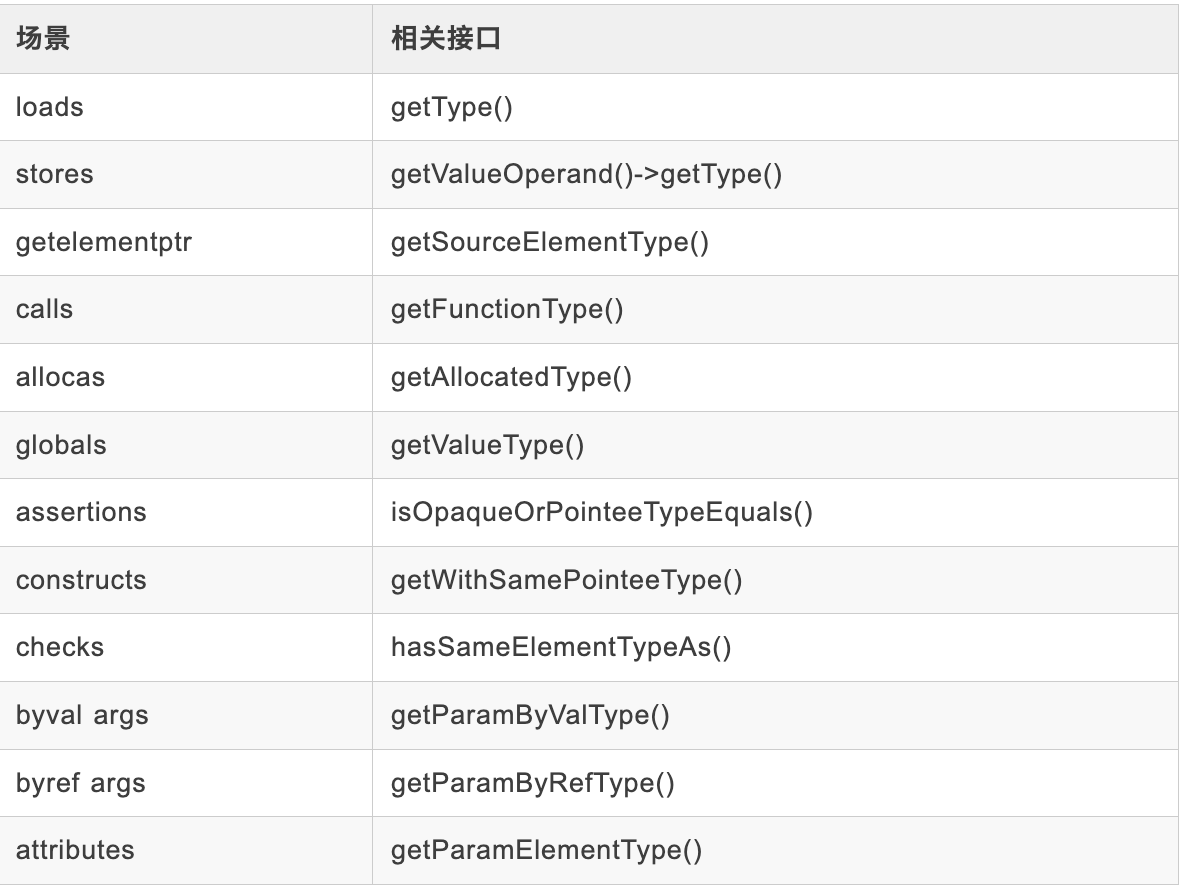
由于 LLVM IR Opcode 的表达能力有限,为了将额外的信息传递给优化器和代码生成器,LLVM 通常有三个解决方法,分别是 Attribute、Metada...
MLIR(Multi-Level Intermediate Representaion,多级中间表示)是一种用来构建可重用和可扩展编译的新方法。MLIR的设计初衷是为了解决...
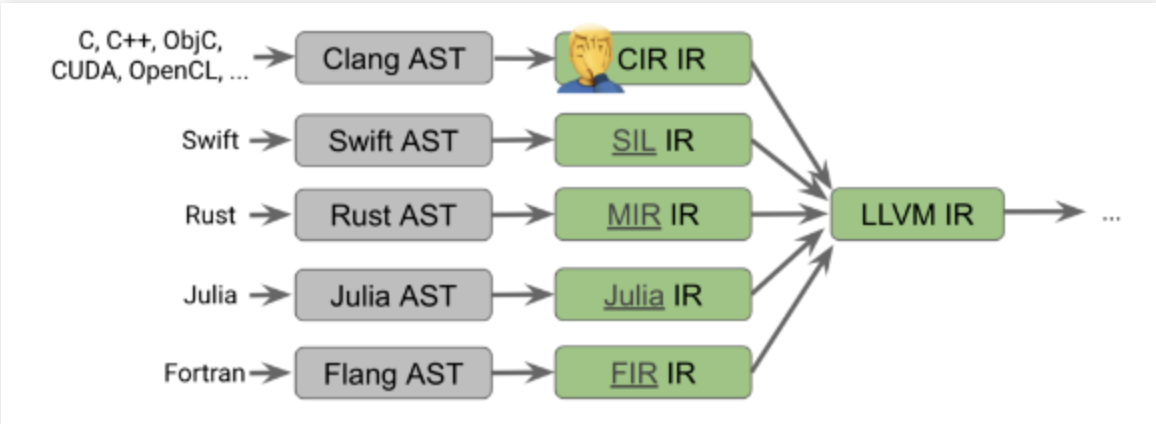
IR (Intermediate Representation):LLVM提供的一套编译器系统的中间语言,与具体的语言、指令集、类型系统无关,其中每条指令都是静态...
本文内容,主要来自官方文档的整合翻译与理解,涉及到的文档是《Blitz Course to TensorIR》,对TensorIR的实现与优化这部分介绍的Sched...

作者:三羊、李宝珠、李玮栋、Yudi、xixi 编辑:李宝珠 在大模型时代的浪潮中,机器学习系统正经历着前所未有的变革。模型规模的急剧膨...

接上三篇:【XR806开发板试用】+1.嵌入式【XR806开发板试用】+2.鸿蒙内核【XR806开发板试用】+3.实战OpenHarmony固件编译大家好,今天我...
2023 Meet TVM · 深圳站于 2023 年 9 月 16 日在腾讯大厦成功举办,百余名参与者亲临现场,聆听讲师们的精彩分享。

TableGen[1]是LLVM的一个工具,其可执行文件的名字为llvm-tblgen。通常在build目录下的bin目录里。

唯一要做的是链接到 target 平台中的 TVM runtime。 TVM 给出了一个最小 runtime,它的开销大约在 300K 到 600K 之间,具体值取决于使用...
本篇文章译自英文文档 Deploy Models and Integrate TVM tvm 0.14.dev0 documentation更多 TVM 中文文档可访问 →Apache TVM 是一个端到...
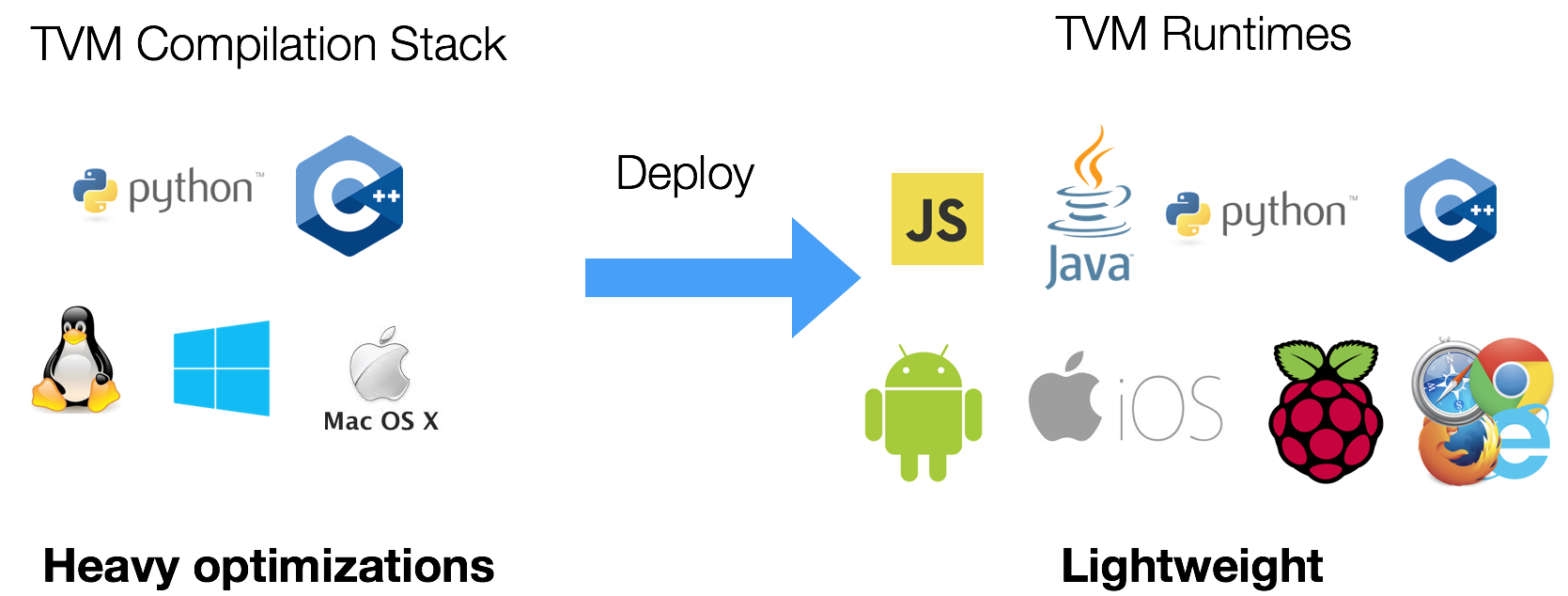
本篇文章译自英文文档 Compile OneFlow Models tvm 0.14.dev0 documentation作者是 BBuf (Xiaoyu Zhang) · GitHub更多 TVM 中文文档可访...
本文介绍如何用 Relay 部署 PaddlePaddle 模型,首先安装 PaddlePaddle(版本>=2.1.3),可通过 pip 快速安装:
本文介绍如何用 TVM 部署 DarkNet 模型。所有必需的模型和库都可通过脚本从 Internet 下载。此脚本运行带有边界框的 YOLO-V2 和 YOLO-V3...







