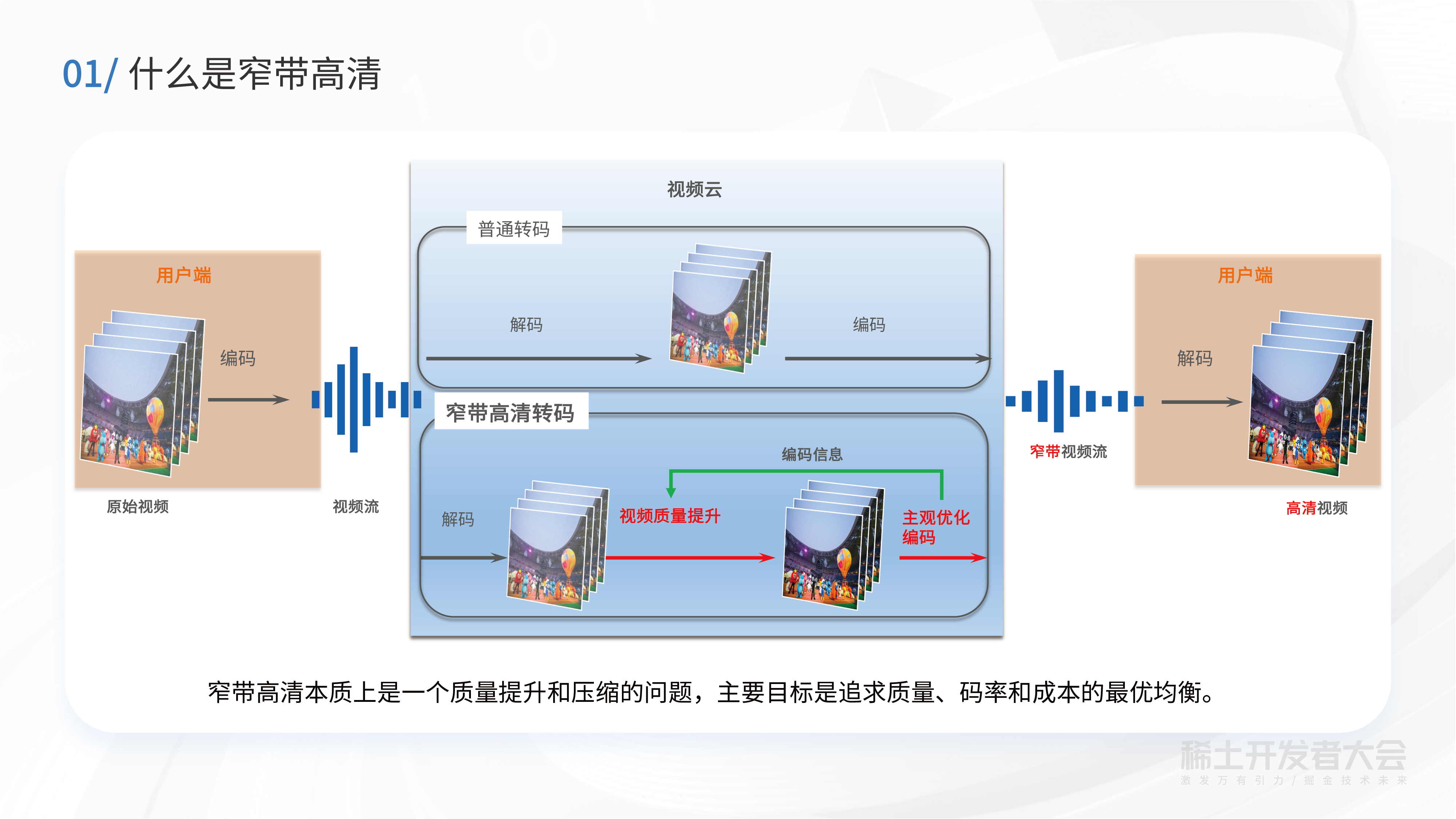
随着5G时代的到来,互联网短视频、电影电视剧、电商直播、游戏直播、视频会议等音视频业务呈井喷式发展。
Anchor-free检测器基本上将目标检测表述为密集分类和回归。对于流行的Anchor-free检测器,通常会引入一个单独的预测分支来估计定位的质...

在很早以前我就隐隐约约有种感觉,姿态估计任务跟目标检测实在是太像了,但是目标检测当中很多的技术姿态估计都没有用上,存在很多可以...

目前人体姿态估计总体分为Top-down和Bottom-up两种,与目标检测不同,无论是基于热力图或是基于检测器处理的关键点检测算法,都较为依赖...
7 月 27 日的 HarmonyOS 3 及华为全场景新品发布会上,华为发布了三款可穿戴运动健康新设备:

论文标题:SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos

这里推荐一个YOLO系列的算法实现库YOLOU,此处的“U”意为“United”的意思,主要是为了学习而搭建的YOLO学习库,也借此向前辈们致敬,希望...

在过去的几年里,目标检测问题的解决有了很大的发展。在存在硬件限制的情况下需要更轻的模型,并且需要为移动设备量身定制模型。在本文...

现实中的数据通常存在长尾分布,其中一些类别占据数据集的大部分,而大多数稀有样本包含的数量有限,使用交叉熵的分类模型难以很好的分...
前不久,一段国外女生模仿 NPC(游戏中非玩家角色)的视频走红,画面中女生无论面部表情、肢体动作都与 NPC 非常相像,一度让人分不清到...

提起 Google 今年给人印象最深的新品,除了还未发售的 Google Pixel Watch 外,恐怕就是 Google I/O 2022 结尾时的 AR 眼镜原型机了。

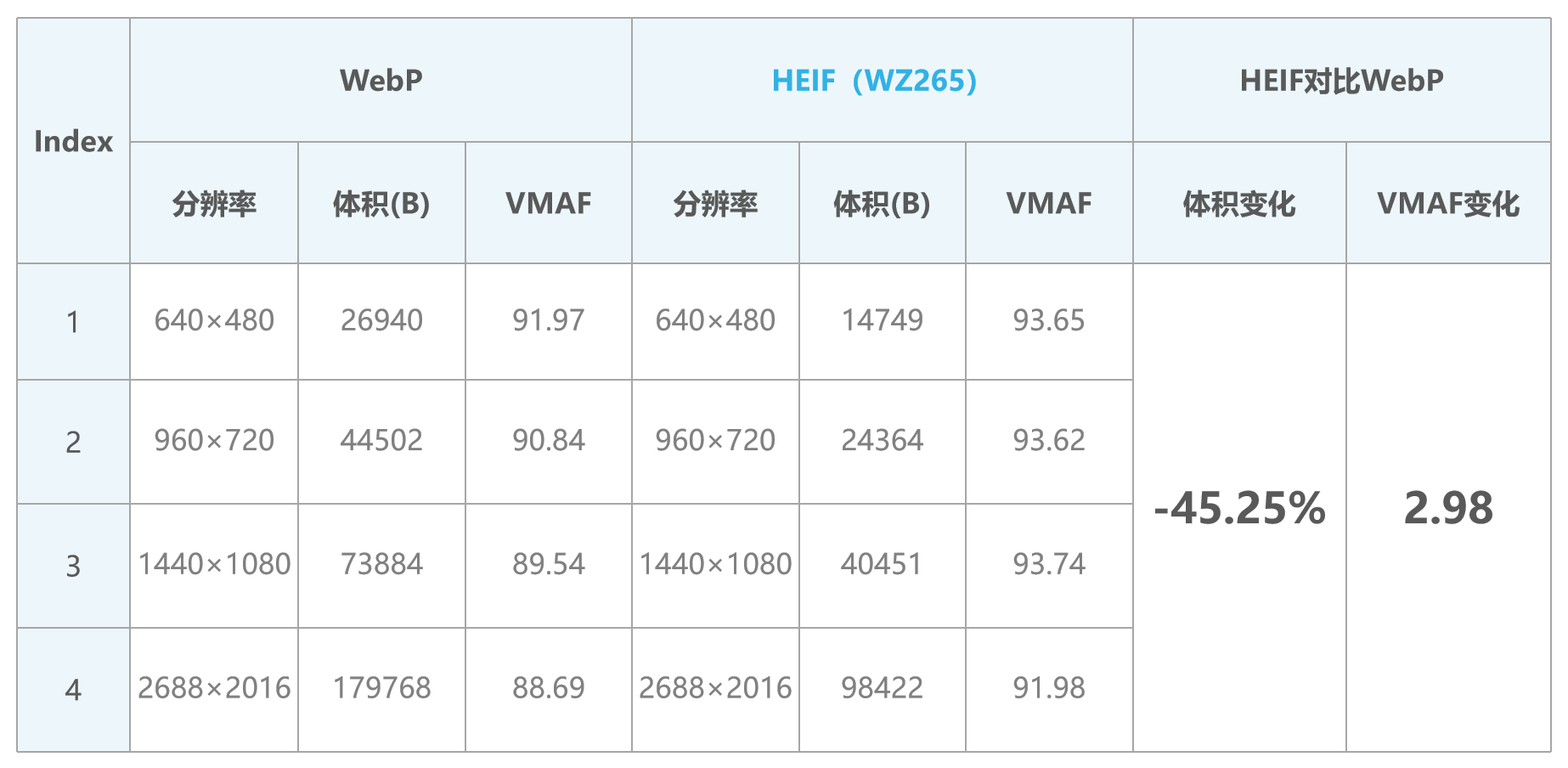
用户体验一直是网民最关注的事情之一,不少社交平台常因为对UGC内容的图像压缩问题,受到过用户的吐槽,比如“精心拍摄的视频照片一发出...
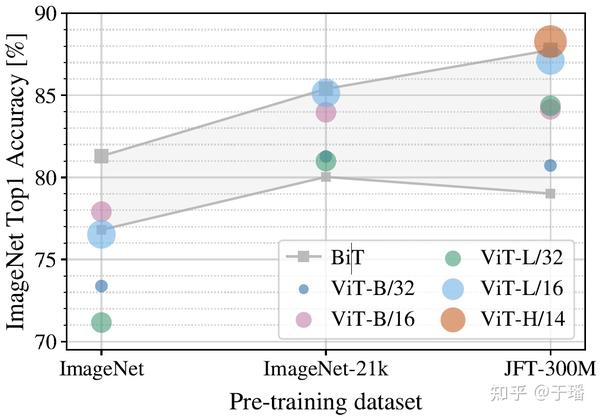
ViT 的最新进展在视觉识别任务中取得了出色的表现。卷积神经网络 (CNN) 利用空间归纳偏差来学习视觉表示,但这些网络是空间局部的。ViTs...

论文标题:ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation

尽管 2021 年 2 月 Magic Leap 的首席执行官 Peggy Johnson 透露了二代产品预计于 2021 年第四季度面世,但毫无悬念地迎来了跳票。

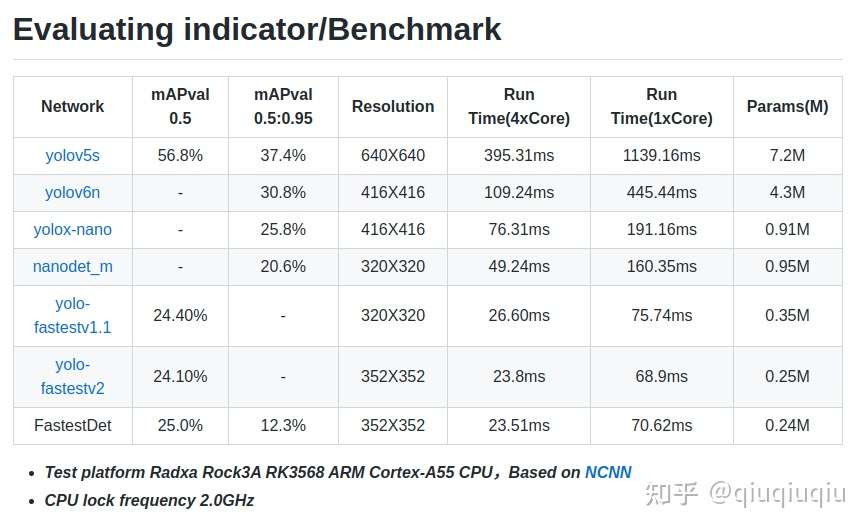
表中耗时是用NCNN测的,测试平台为RK3568 ARM-CPU,FastestDet相比于yolo-fastest单核耗时减少了10%,mAP0.5的指标要比yolo-fastestv2提...
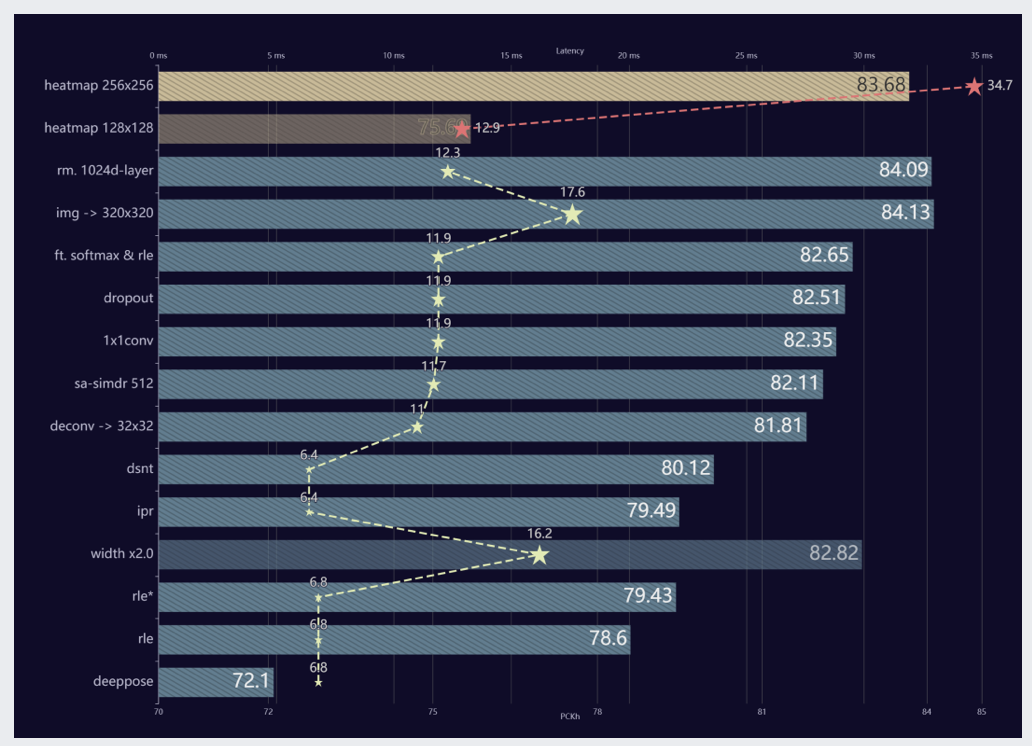
【CPU下12ms】轻量姿态估计模型Regression方法如何做到比Heatmap方法快近3倍且精度更高
自从Vision Transformer网络面世以来,Transformer模型在CV领域的应用也逐渐开始崭露头角。然而如图1所示,原始的ViT网络模型在小数据集...
据 IDC 2021 年第四季度可穿戴设备全球出货量报告显示,在以智能眼镜、智能戒指等为核心的细分领域,该季度获得了 94.1% 的增长,其中深...

2022年7月,YOLOv7来临, 论文链接:[链接] 代码链接:[链接] 在v7论文挂出不到半天的时间,YOLOv3和YOLOv4的官网上均挂上了YOLOv7的链...