多年来,心理健康问题越来越受到关注。心理健康领域也因此涌现出许多新的分支,尤其是对女性心理健康的研究,引起了广泛的公众关注。如...

中国香港的击剑女将江旻憓,在巴黎奥运会上勇夺金牌,成为众人瞩目的焦点。而她曾经的一段话更是触动了众多网友的心:'我从未在任何领域...

心理咨询的定义与重要性心理咨询通过咨询师与来访者之间的语言、思想和情感交流,在特定心理氛围中应用心理学知识和技术,帮助来访者解...
3-8岁是宝宝的关键期,在这个阶段也是父母最费心的时候:孩子吃饭、洗澡、睡觉总爱拖延、玩玩具三分钟热度、上课小动作多、语言能力弱,...
在快速变化的社会中,随着人们对自我健康认识的不断加深,心理健康已成为影响生活质量的关键因素,许多成年人在其一生中会遇到心理健康...

人工智能技术的迅猛发展已经渗透到各个行业,尤其在心理健康和情感分析领域,AI展现出其独特的洞察力和分析能力。如数业智能心大陆,作...

中国患抑郁症的人数目前已达数千万,心理健康问题已成为全民性议题。尽管生活水平提高,但现代社会对个人的多方面要求增加,家庭、人际...

在数字时代,心理健康的重要性日益凸显,而科技的进步为我们提供了全新的解决方案。"数业智能心大陆",将人工智能的深度洞察力和专业心...

在这个快节奏、高压力的社会中,年轻人面临着前所未有的心理挑战。从职场竞争到人际关系,再到经济压力,这些因素共同构成了年轻一代的...

人类通过融合视觉、听觉和触觉等多种感官获取和处理信息,形成对世界的全面理解。多模态人工智能(Multimodal AI)正在模拟并扩展这种综...

在探索人类复杂心理世界的旅途中,科学与技术正携手开启一扇通往深层次理解的大门。数业智能心大陆AI大模型,作为这一领域的先锋,正以...
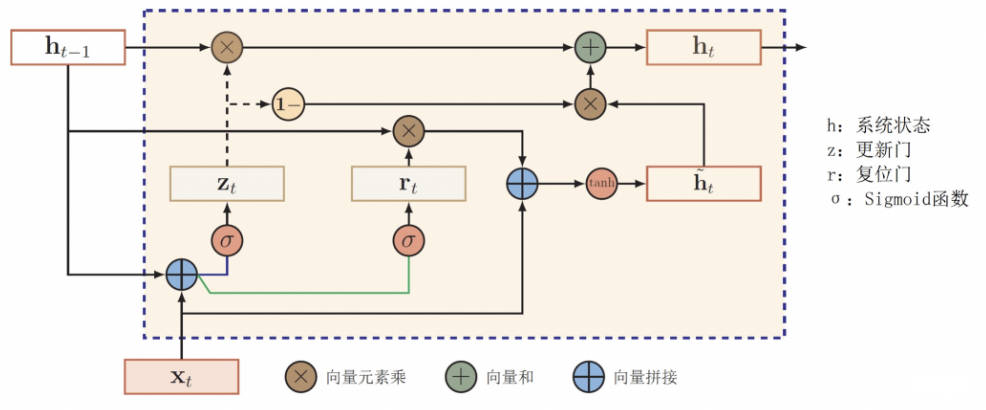
GRU(Gate Recurrent Unit)门控循环单元,是[循环神经网络](RNN)的变种种,与 LSTM 类似通过门控单元解决 RNN 中不能长期记忆和反向...
作者:xixi 编辑:李宝珠、三羊 2023 年 12 月 21 日,由 HyperAI超神经参与编撰的「可信开源大模型案例集汇编(第一期)」在 2024 中国...

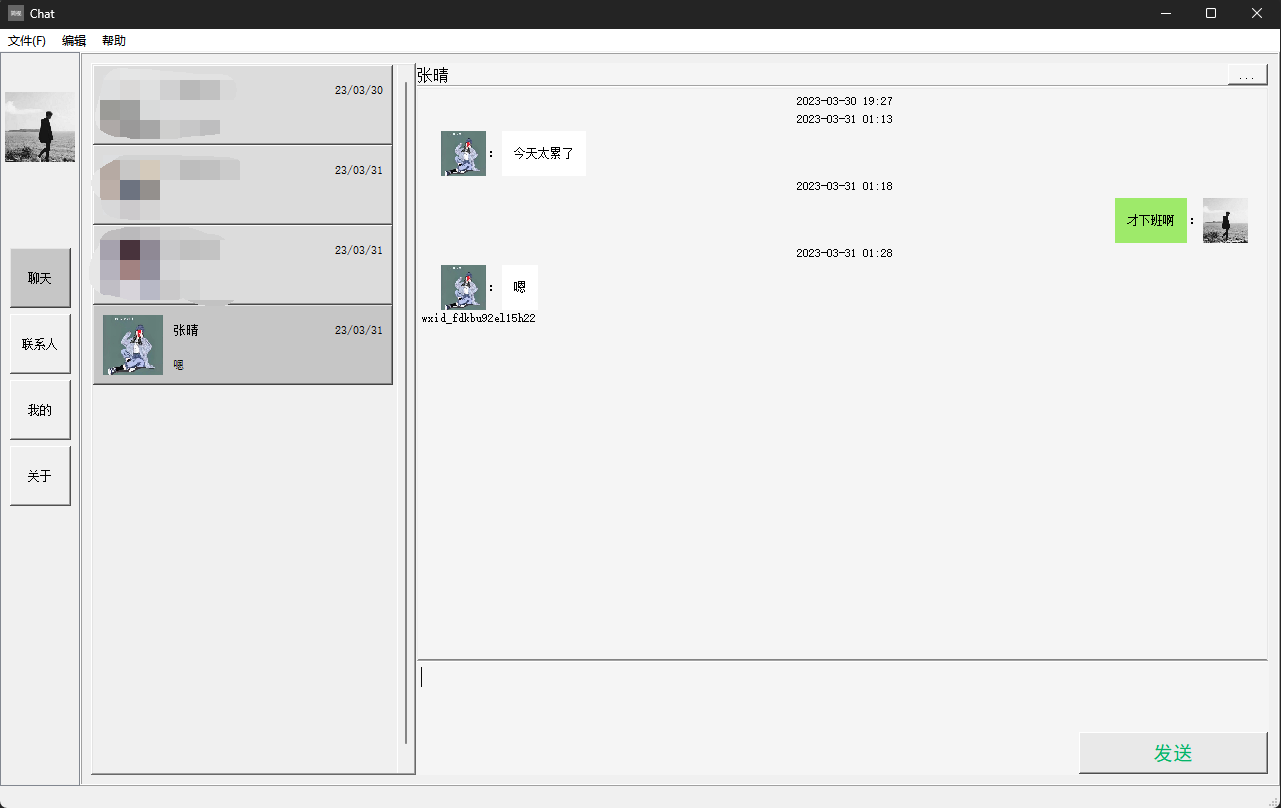
一个用于提取微信聊天记录的工具,支持将聊天记录导出成HTML、Word、CSV文档,以实现永久保存。此外,该工具还具有对聊天记录进行分析的...
近半年来如火如荼的「百模大战」让越来越多的终端厂商卷进来,机器人、音箱、手表、眼镜等硬智能硬件产品加持大模型能力,让产品快速接...

生物信息学 (Bioinformatics) 是指利用应用数学、信息学、统计学和计算机科学的方法,研究生物学问题。随着计算机科学技术的发展,AI 在...

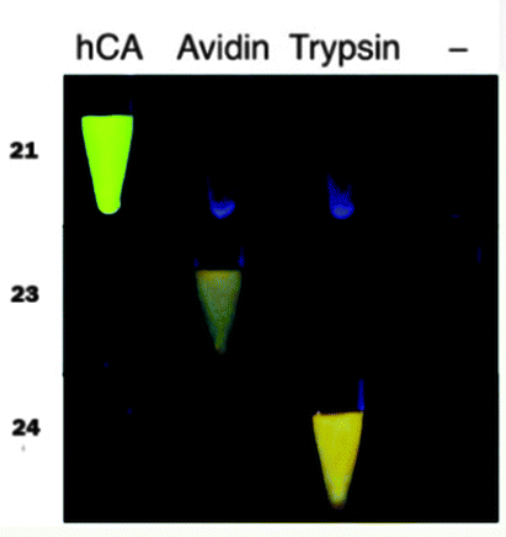
多肽是两个以上氨基酸通过肽键组成的生物活性物质,可以通过折叠、螺旋形成更高级的蛋白质结构。多肽不仅与多个生理活动相关联,还可以...
在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的...

近日,位于澳大利亚悉尼的微软 Azure 服务突发中断,导致用户在超过 24 小时内无法访问 Azure、Microsoft 365 和 Power Platform 服务。...
进入2023年,ChatGPT推动世界步入一个全新时代——大模型时代,它不仅引发了AI产业的整体升级换代,同时也让各种大模型层出不穷,背后的关...








