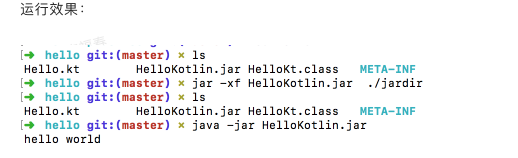
安装Kotlin编译器 {代码...} 命令行方式写kotlin {代码...} {代码...} {代码...} {代码...} {代码...} {代码...} {代码...} {代码...}
最近 TL 分享了下 《Elasticsearch基础整理》[链接] ,蹭着这个机会。写个小文巩固下,本文主要讲 ES -> Lucene的底层结构,然后详细...

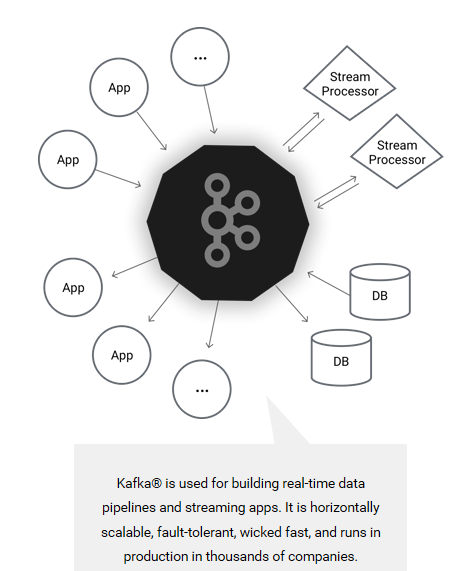
通过Kafka的快速入门 [链接]能了解到Kafka的基本部署,使用,但他和其他的消息中间件有什么不同呢?Kafka的基本原理,术语,版本等等都...
今年上半年,我国一级市场的整体情况非常惨淡,募资规模与融资额规模均有30% - 50% 的下跌,哪怕是风口上的 AI 行业,行业投资总额也较...

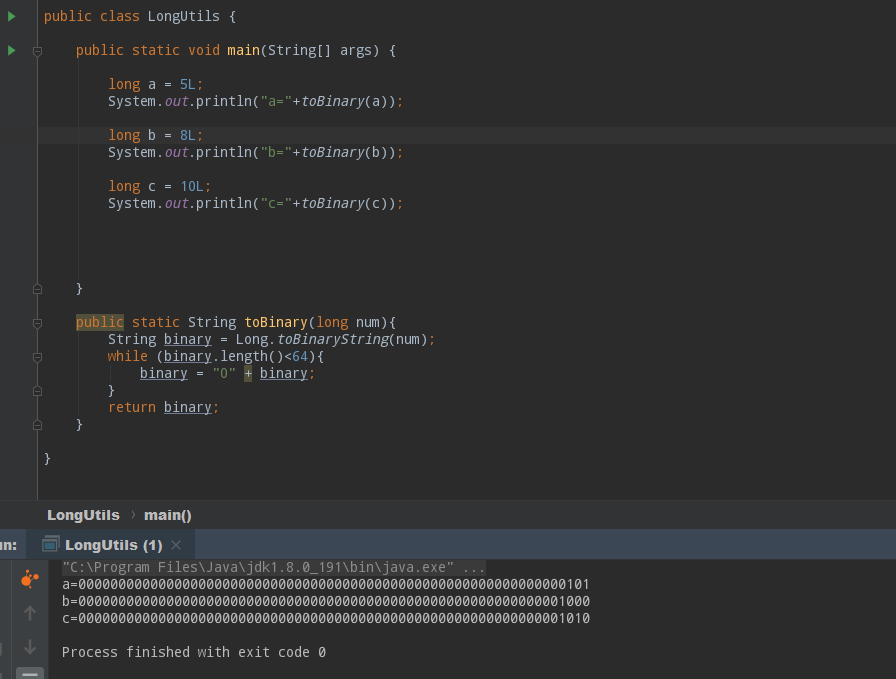
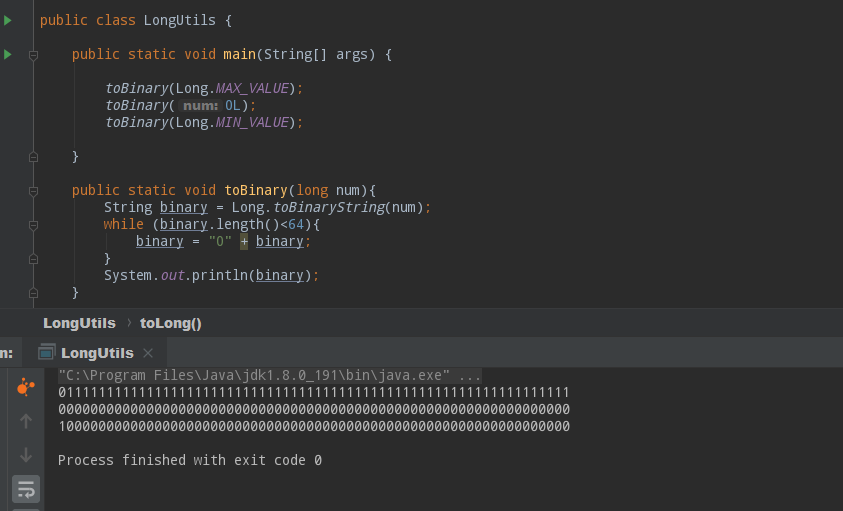
雪花算法初步完成后,我们讨论了几个位运算的写法,大家知道雪花算法一旦确定后,很多数字都是定死的,比如机器占多少位,或者时间向左...
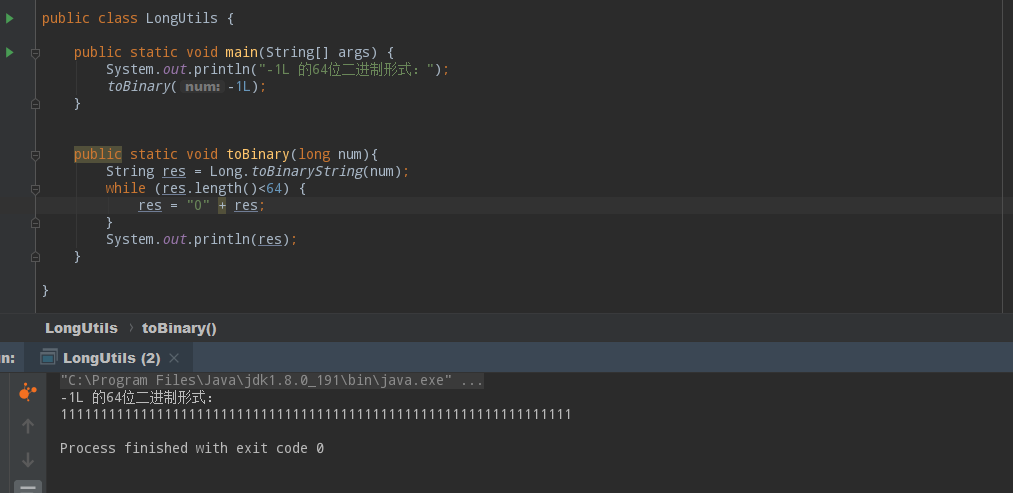
这里注意二进制数字的思路是相反的,在负整数中,除去负号外,那个数字越大,这个负数就越小,在Java的二进制形式中,首位代表正负号,...
前面的内容把雪花算法的时间部分和机器信息部分都生成了,下面来生成最后一部分,就是毫秒内的序列。什么意思呢?我们在生成时间部分获...

Docker中部署tomcat相信大家也都知道,不知道的可以google 或者bing 一下。这里主要是为了记录在我们启动容器之后,tomcat需要直接定位...

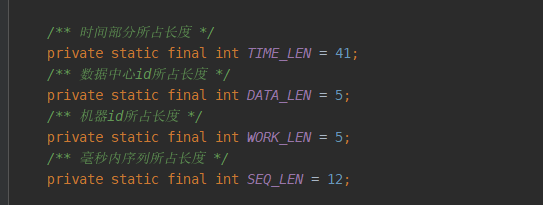
时间部分生成后,下一步是机器信息,占10位。我们这里把机器信息分成两部分,一部分是数据中心id,占5位,一部分是机器id,占5位。这两...

前面的理论基础和位运算都了解了,下面我们来生成雪花算法的第一部分,也就是时间部分。时间部分的逻辑起始很简单,就是规定一个起始时...

截至2019年7月8日 最新版本为 2.3.0 2.12为编译的scala版本 2.3.0为kafka版本

前面介绍了雪花算法的理论基础,可以对大概的算法有个了解,但是细节上可能还是模糊,下面来说一下雪花算法中用到的位运算。这里先介绍...
针对每个公司,随着服务化演进,单个服务越来越多,数据库分的越来越细,有的时候一个业务需要分成好几个库,这时候自增主键或者序列之...
记得第一次接触 Nginx 是在实验室,那时候在服务器部署网站需要用 Nginx 。Nginx 是一个服务组件,用来反向代理、负载平衡和 HTTP 缓存...

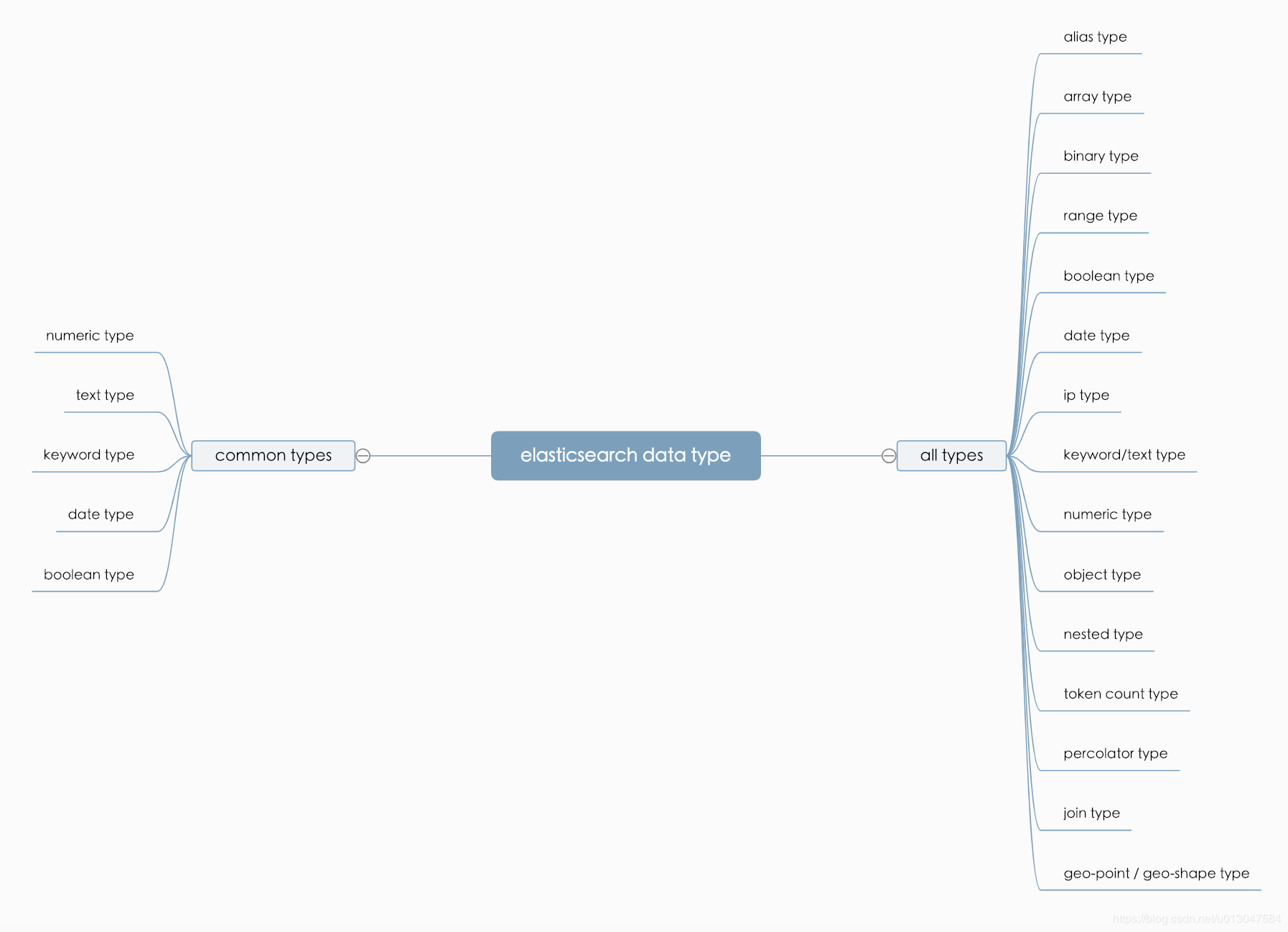
基本数据类型:string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
2018年3月初,萌生了一个想法:对Elasticsearch相关的技术书籍做拆解阅读,该想法源自非计算机领域红火已久的【樊登读书会】、得到的每...

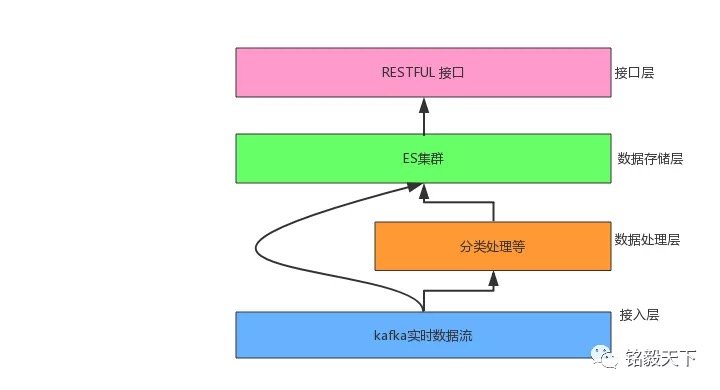
实时数据流通过kafka后,根据业务需求,一部分直接借助kafka-connector入Elasticsearch不同的索引中。另外一部分,则需要先做聚类、分类...
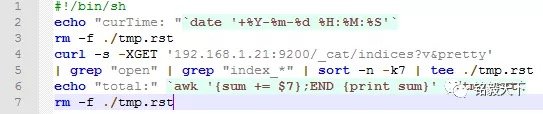
随着ELKStack在应用系统中的数据规模的急剧增长,每天千万级别数据量(存储大小:10000000*10k/1024/1024=95.37GB,假设单条数据10kB,...
本文讲述的是调教 Helm 3 和 harbor 1.6+ 的经验,从 helm2 更新到 helm 3 并且将 charts 推送到 harbor 中进行存储,移除了原先的 helm...

主要原因是,我不会 vim ,在 linux 上修改 charts 的很蹩脚,所以就想着能不能再 windows 上执行 helm 命令,将 charts install linux ...

需求:在每次线下活动的开始的前一天晚上七点给报名参加价值研习社的用户发一条通知短信用户记得准时参加活动。

企业在安全方面最关注的其实是业务安全、数据安全与安全检查,这篇文章来讲解一下我对于等保过检的经验与建设。

【实用小工具推荐】给技术同学们推荐一款比较好用的工具,可以实现一稿多发,主流的技术渠道基本涵盖了:[链接]因为工作的关系,认识了...
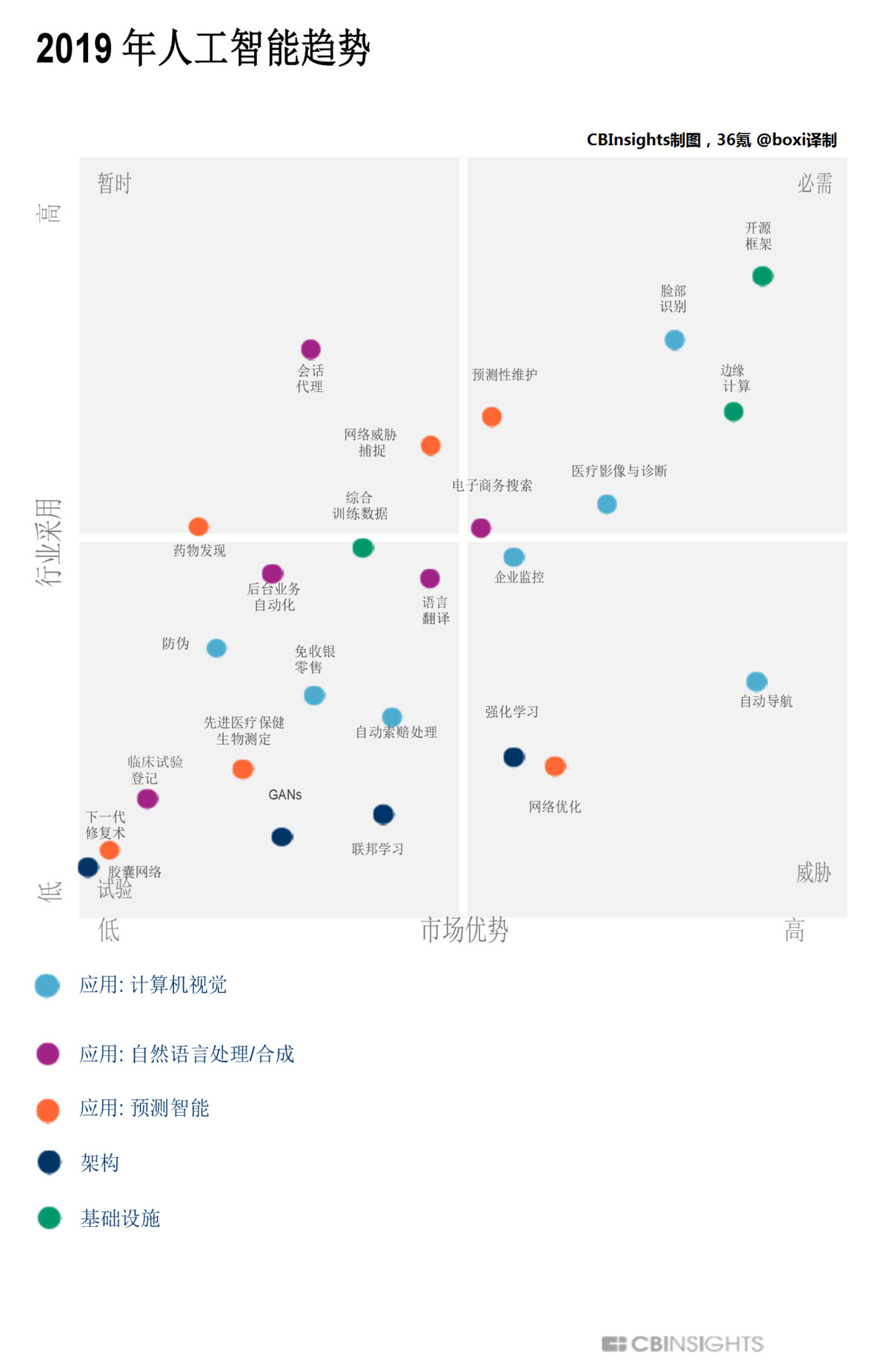
AI的进入门槛变得空前的低,得益于TensorFlow、paddlepaddle、Tengine等AI开源框架普及,人工智能的发展趋势请大家参考以下图片所示,来...
安装Kotlin编译器 {代码...} 命令行方式写kotlin {代码...} {代码...} {代码...} {代码...} {代码...} {代码...} {代码...} {代码...}
最近 TL 分享了下 《Elasticsearch基础整理》[链接] ,蹭着这个机会。写个小文巩固下,本文主要讲 ES -> Lucene的底层结构,然后详细...
通过Kafka的快速入门 [链接]能了解到Kafka的基本部署,使用,但他和其他的消息中间件有什么不同呢?Kafka的基本原理,术语,版本等等都...
今年上半年,我国一级市场的整体情况非常惨淡,募资规模与融资额规模均有30% - 50% 的下跌,哪怕是风口上的 AI 行业,行业投资总额也较...
雪花算法初步完成后,我们讨论了几个位运算的写法,大家知道雪花算法一旦确定后,很多数字都是定死的,比如机器占多少位,或者时间向左...
这里注意二进制数字的思路是相反的,在负整数中,除去负号外,那个数字越大,这个负数就越小,在Java的二进制形式中,首位代表正负号,...
前面的内容把雪花算法的时间部分和机器信息部分都生成了,下面来生成最后一部分,就是毫秒内的序列。什么意思呢?我们在生成时间部分获...
Docker中部署tomcat相信大家也都知道,不知道的可以google 或者bing 一下。这里主要是为了记录在我们启动容器之后,tomcat需要直接定位...
时间部分生成后,下一步是机器信息,占10位。我们这里把机器信息分成两部分,一部分是数据中心id,占5位,一部分是机器id,占5位。这两...
前面的理论基础和位运算都了解了,下面我们来生成雪花算法的第一部分,也就是时间部分。时间部分的逻辑起始很简单,就是规定一个起始时...
截至2019年7月8日 最新版本为 2.3.0 2.12为编译的scala版本 2.3.0为kafka版本
前面介绍了雪花算法的理论基础,可以对大概的算法有个了解,但是细节上可能还是模糊,下面来说一下雪花算法中用到的位运算。这里先介绍...
针对每个公司,随着服务化演进,单个服务越来越多,数据库分的越来越细,有的时候一个业务需要分成好几个库,这时候自增主键或者序列之...
记得第一次接触 Nginx 是在实验室,那时候在服务器部署网站需要用 Nginx 。Nginx 是一个服务组件,用来反向代理、负载平衡和 HTTP 缓存...
基本数据类型:string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
2018年3月初,萌生了一个想法:对Elasticsearch相关的技术书籍做拆解阅读,该想法源自非计算机领域红火已久的【樊登读书会】、得到的每...
实时数据流通过kafka后,根据业务需求,一部分直接借助kafka-connector入Elasticsearch不同的索引中。另外一部分,则需要先做聚类、分类...
随着ELKStack在应用系统中的数据规模的急剧增长,每天千万级别数据量(存储大小:10000000*10k/1024/1024=95.37GB,假设单条数据10kB,...
本文讲述的是调教 Helm 3 和 harbor 1.6+ 的经验,从 helm2 更新到 helm 3 并且将 charts 推送到 harbor 中进行存储,移除了原先的 helm...
主要原因是,我不会 vim ,在 linux 上修改 charts 的很蹩脚,所以就想着能不能再 windows 上执行 helm 命令,将 charts install linux ...
需求:在每次线下活动的开始的前一天晚上七点给报名参加价值研习社的用户发一条通知短信用户记得准时参加活动。
企业在安全方面最关注的其实是业务安全、数据安全与安全检查,这篇文章来讲解一下我对于等保过检的经验与建设。
【实用小工具推荐】给技术同学们推荐一款比较好用的工具,可以实现一稿多发,主流的技术渠道基本涵盖了:[链接]因为工作的关系,认识了...
AI的进入门槛变得空前的低,得益于TensorFlow、paddlepaddle、Tengine等AI开源框架普及,人工智能的发展趋势请大家参考以下图片所示,来...


 Arm 计算
Arm 计算
 安谋科技自研产品
安谋科技自研产品
 AI 应用
AI 应用
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西



















