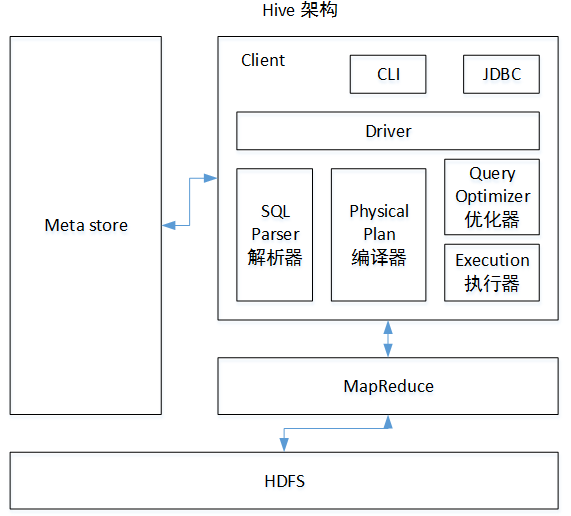
用户接口:ClientCLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
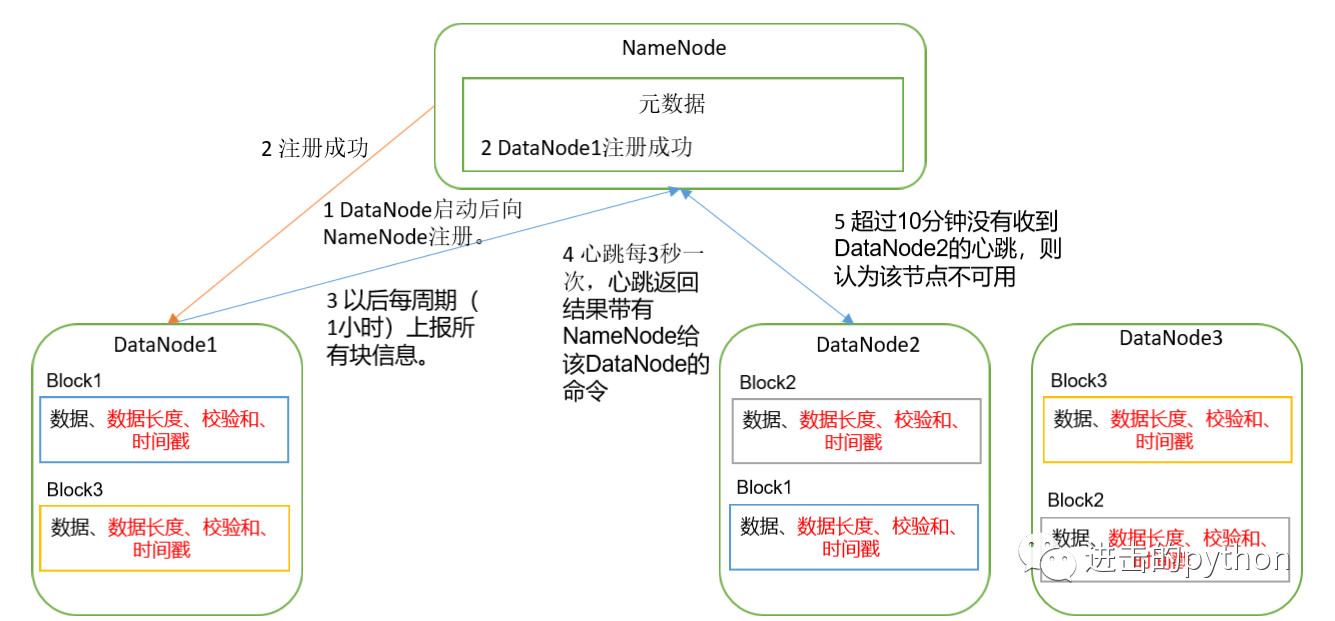
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及...
场景描述:2019 云栖大会于昨日落幕。在这三天里,阿里围绕「数·智」主题,进行了多场技术分享和交流。和以往不同,作为马云卸任后的首...

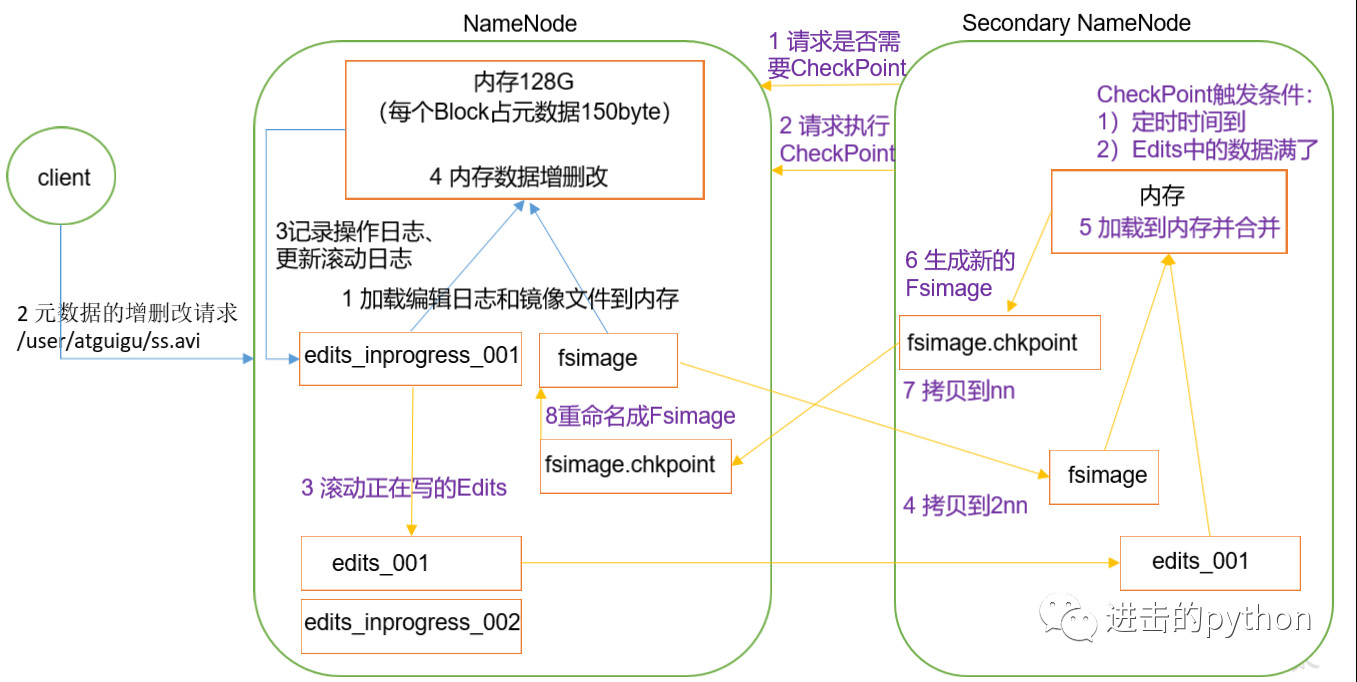
假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的
行转列原始数据:需求: {代码...} 实现: {代码...} 列转行原始数据:需求: {代码...} 实现: {代码...}

前言:今天接手了同事之前做的一个小项目,里面涉及到了 FastDFS 的使用。但是当我在本地运行项目的时候,却报了 Could not autowire No...

在正式开始前,千万不要把这一步与数据可视化或数据结果统计混淆——数据可视化或数据结果统计意味着结果。

集群环境:centOs6.8:hadoop102,hadoop103,hadoop104jdk版本:jdk1.8.0_144hadoop版本:Hadoop 2.7.2

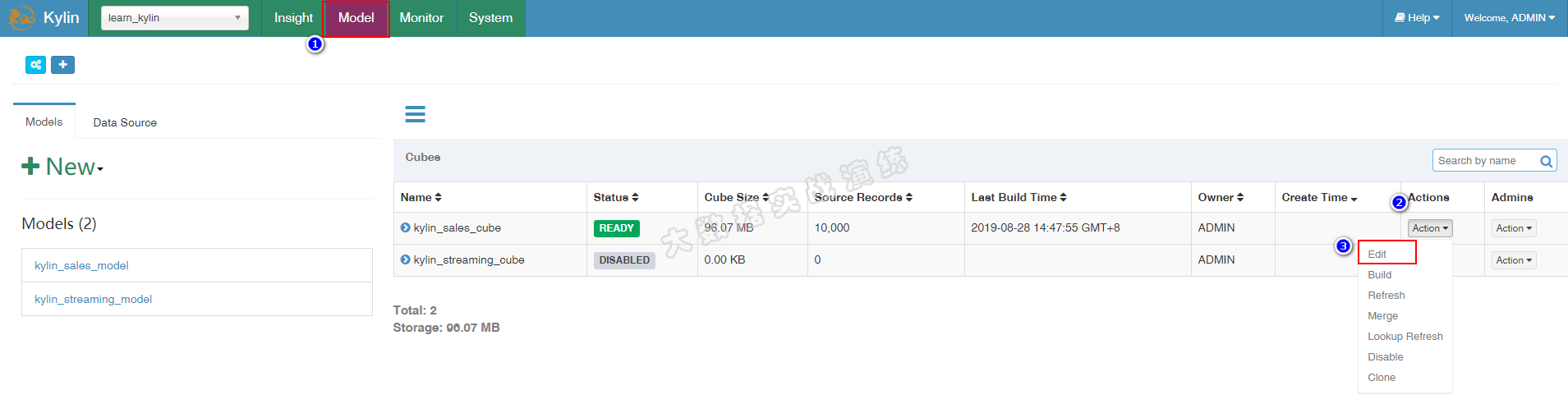
HDP版本:2.6.4.0Kylin版本:2.5.1机器:三台 CentOS-7,8G 内存Kylin 的计算引擎除了 MapReduce ,还有速度更快的 Spark ,本文就以 Ky...
我们知道,大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计...
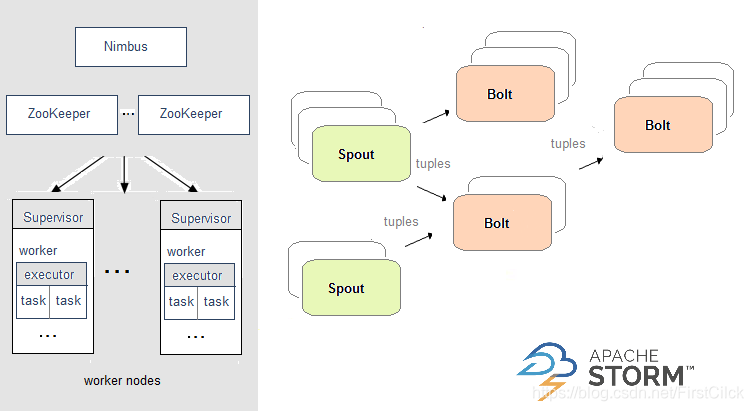
在学习了Zookeeper(后文都简称zk)的介绍和功能后,您已经很好地理解了zk。 现在,在这个zk教程中,我们将讨论zk的优点和局限性。 zk有...

在广告系统中倒排索引起着至关重要的作用,当请求过来时,需要根据定向信息从倒排索引中匹配合适的广告。我们的倒排索引采用的是Elastic...

Broker:Kafka的服务端即Kafka实例,Kafka集群由一个或多个Broker组成,主要负责接收和处理客户端的请求

上次我们通过分析KafkaProducer的源码了解了生产端的主要流程,今天学习下服务端的网络层主要做了什么,先看下 KafkaServer的整体架构图

流式计算可以广泛应用于金融银行、互联网、物联网等诸多领域,如股市实时分析、插入式广告投放、交通流量实时预警等场景,主要是为了满...
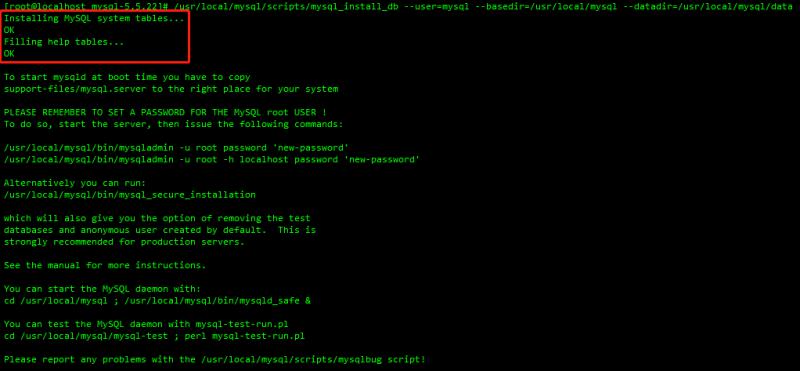
MySQL 数据库是一个关系型数据库管理系统,是服务器领域中受欢迎的开源数据库系统,目前有 Oracle 公司主要负责运营与维护;
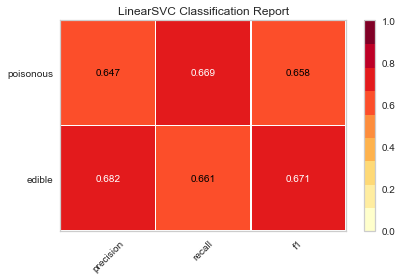
从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性...
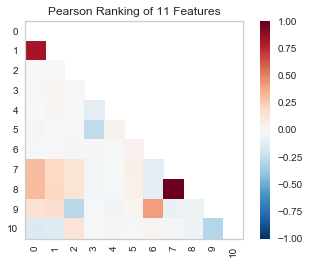
从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性...


 Arm 计算
Arm 计算
 安谋科技自研产品
安谋科技自研产品
 AI 应用
AI 应用
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西
















