目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提供全套的训练、微调模型(包括大模型、文本转向量、文本生成、...

随着 ChatGPT 和 GPT-4 等强大生成模型出现,自然语言处理任务方式正在逐步发生改变。鉴于大模型强大的任务处理能力,未来我们或将不再...

使用Stable Diffusion生成视频一直是人们的研究目标,但是我们遇到的最大问题是视频帧和帧之间的闪烁,但是最新的论文则着力解决这个问题。
内容一览:从光鲜亮丽的明星,到素装淡裹的普通人,大家都会无可避免地老去,经历形容的变化与身体机能的退化。正因为此,人们也在努力...

LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
“DeepFaceLab”项目已经发布了很长时间了,作为研究的目的,本文将介绍他的原理,并使用Pytorch和OpenCV创建一个简化版本。
这篇文章的目的是详细的解释Flash Attention,为什么要解释FlashAttention呢?因为FlashAttention 是一种重新排序注意力计算的算法,它...
信息抽取是 NLP 任务中非常常见的一种任务,其目的在于从一段自然文本中提取出我们想要的关键信息结构。
生成式人工智能正在快速发展,许多人正在尝试使用这项技术来解决他们的业务问题。一般情况下有4种常见的使用方法:
内容一览: 人脸识别可以锁定人类身份,这一技术延申到鲸类,便有了「背鳍识别」。「背鳍识别」是利用图像识别技术,通过背鳍识别鲸类物...
文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自...
pycorrector: 中文文本纠错工具。支持中文音似、形似、语法错误纠正,python3开发。实现了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA...

Similarities 相似度计算、语义匹配搜索工具包,实现了多种相似度计算、匹配搜索算法,支持文本、图像等。

内容一览:对养猪业而言,母猪产仔是其中关键的一环。因此,提高猪仔成活率、确保母猪分娩过程安全,成为重要课题。现有的 AI 监测方式...

医学成像数据与其他我们日常图像的最大区别之一是它们很多都是3D的,比如在处理DICOM系列数据时尤其如此。DICOM图像由很多的2D切片组成...
这是我们部署Stable Diffusion的第三篇文章了,前两篇文章都详细介绍了Automatic1111的stable-diffusion-webui的安装,这次主要介绍如何...
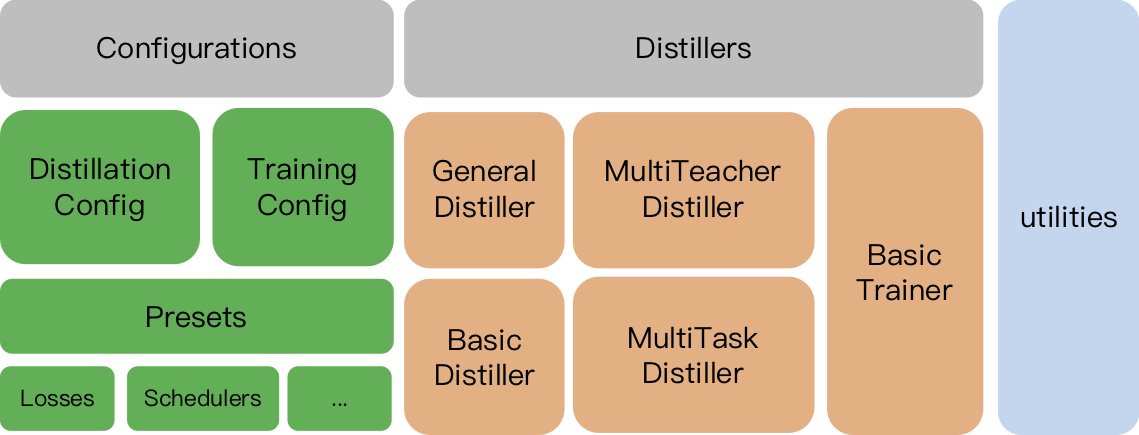
TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包,融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的...
多模态预训练模型通过在多种模态的大规模数据上的预训练,可以综合利用来自不同模态的信息,执行各种跨模态任务。在本项目中,我们推出...

这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强Retrieval Augmented技术,目的是让深度学习在表格数据上超过梯度增强模型。
科技云报道原创。最近,又一个概念火了——向量数据库。随着大模型带来的应用需求提升,4月以来多家海外知名向量数据库创业企业传出融资喜...








